Chris Pollett >
Students >
Gargi
( Print View)
[Bio]
[Blog]
[Paper 1: Large-scale IRLBot crawl PDF]
[Paper 2: Distributed Crawler Architecture PDF]
[Paper 3: Scalability Challenges PDF]
[Paper 4: High Performance Priority Queues PDF]
[Deliverable 1: Yioop Ranking Mechanisms PDF]
[Deliverable 2(ii): Modifying Yioop's UI Editor]
[Deliverable 3: Modifying Yioop's queuing process]
[Deliverable 4: Yandex Signal PDF]
[C298: Yandex-inspired Search Factors]
[C298: Latest Page Version in SERP]
Latest Page Version in SERP (CS298 Deliverable#2)
Aim:
Getting the "freshest" (most recent) version of a crawled page in the search results in case a URL is crawled more than once in a single crawl duration.
SERP:
Search Engine Results Page- The page that a search engine returns after a user submits a search query.
Background:
In the current Yioop implementation, we clear the list of crawled URLs periodically (such as every 24 hours). This is done to make the crawling operation efficient, as well as re-crawl important URLs that tend to change frequently. However, Yioop's host budgeting mechanism (crawling implementation) assumes that the URLs are crawled in order of their importance. With this notion, even if the same page is crawled a second time, the first version encountered is more important than the most recent one. Ideally however, for the same page, the user should be presented with the most recently crawled page version in the generated SERP. It is possible that the same term may not even exist in the latest version of the document. The rank for this result should be retained as that of the first-ever crawled version.
Implementation:
The changes for this deliverable are implemented in both the crawling and search logic. The following changes have been made:
-
IndexDocumentBundle::addScoresDocMap()
- Along with the position score list, a doc_map entry now stores a representation of the top 300 words appearing in the document.
- The value of 300 was chosen as a cap value through experimentation, where approximately 50,000 URLs were crawled and the maximum number of unique terms found in a single document was 282.
- A bloom filter is used to store the term ids of each of the 300 (or lesser) words with 3 bits each (i.e., 3 hash functions). The bloom filter is thus stored in a string of 125 bytes (1000 bits).
- The bloom filter string is prepended with a character 't' for backward compatibility purposes, such that the logic to find the latest version of a page is only carried out for crawls that took place after this change in the doc_map entry format.
- For each doc_map entry created and zipped (through Utility::pack()), this 126-byte string is prepended to the table entry and stored in the doc_map file.
-
WordIterator::getDocKeyPositionsScoringInfo()
- The primary search changes to get the latest version of a page are implemented in this function.
- The WordIterator class now accepts a flag $latest_version into its constructor, which indicates whether the logic to lookup the latest version of a result should be invoked.
- While iterating over the list of postings in the current generation (for the current search term id), we check if the flag is set and accordingly extract the first 8 bytes of the doc_key from its corresponding doc_map entry into $url_hash.
- The value in $url_hash (prepended with "info:" is then passed into a call to ParallelModel::lookupSummaryOffsetGeneration()) to get a list of all the occurrences of that url in the index.
- The obtained postings list is scanned to get the last entry ($latest_entry). If this is the same as the current posting/generation combination, it is skipped as the current posting is the latest version of the page.
- From $latest_entry, we find the doc_map entry associated with that posting and extract the bloom filter string embedded in it (the 125 bytes after the doc_key). We then check if the current term id is present in that string. If not, the posting is skipped, since this means that the term doesn't exist in the latest version of the page and should thus not appear in the SERP.
- If the document contains the current term, the term must appear in the postings file for the generation associated with $latest_entry. So we get the postings entry in that generation for the current term and find the posting with DOC_MAP_INDEX = that of $latest_entry['DOC_MAP_INDEX'].
- This posting entry is used to obtain the positions list and frequency associated with it.
- Finally, $posting is replaced with the $latest_posting values for generation, doc_map_index, positions, and frequency.
- The logic to fetch the positions file for the current generation and posting is extracted into separate functions getPositionsFile() and getPositionsList().
-
ParallelModel::lookupSummaryOffsetGeneration()
- A flag $latest_version_lookup is added to the parameters accepted by lookupSummaryOffsetGeneration(). If this flag is set, the list of postings (by generation) corresponding to the hash of the url passed to the function.
-
PhraseModel::getQueryIterator()
- The $latest_version flag is set to true for the WordIterator instance created.
Experimentation:
- I tested these modifications on a local instance of Yioop, and carried out two crawls of sizes (1) 1128038 and (2) 1793491.
- To check the impact on speed, I searched for the same words across each of the indexes and compared the results to the original codebase on a crawl of ~1500000 sites. These words included mobile, horse, mountain, goodread book, yahoo, weather.com, and combinations with meta words such as site:https://www.google.com/, site:https://www.wikipedia.org/, bestseller no:guess.
-
For most of the queries, there wasn't a noticeable difference in the time taken to generate the results page. Some examples of these are:
- mobile: Time taken to generate the SERP for the original codebase, crawl (1), and crawl (2) respectively: 801ms, 854ms, 870ms.
- mountain: Time taken to generate the SERP for the original codebase, crawl (1), and crawl (2) respectively: 688ms, 659ms, 710ms.
- goodread book: Time taken to generate the SERP for the original codebase, crawl (1), and crawl (2) respectively: 551ms, 563ms, 558ms.
- site:https://www.google.com/: Time taken to generate the SERP for the original codebase, crawl (1), and crawl (2) respectively: 1013ms, 1044ms, 1050ms.
-
For a few of the queries, there was a difference in the time taken to generate the results page. Some examples of these are:
- horse: Time taken to generate the SERP for the original codebase, crawl (1), and crawl (2) respectively: 440ms, 521ms, 523ms.
- yahoo: Time taken to generate the SERP for the original codebase, crawl (1), and crawl (2) respectively: 399ms, 472ms, 466ms.
- After implementing the above changes, a few of the results were updated with more recent versions of the page. Examples:
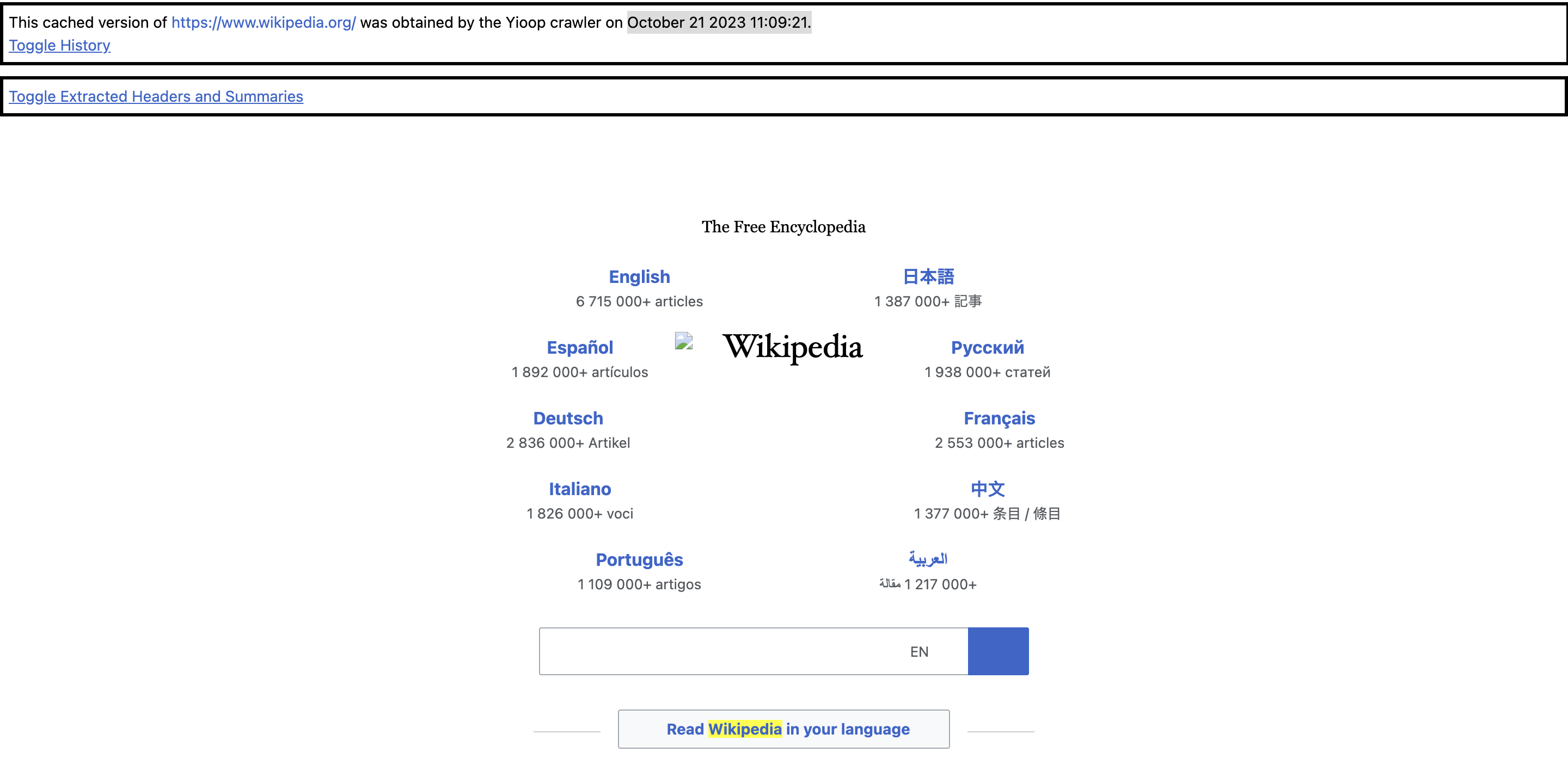

- This update in results was seen in crawl (2) after implementing the changes, crawl (1) had a single version downloaded for all of the result sites encountered.