Chris Pollett >
Students >
Bui
( Print View)
[Bio]
[Blog]
A WARC file reader/writer in Node.js
David Bui (david.bui01@sjsu.edu)
Purpose
The goal of this deliverable is to create a Warc parser capable of reading, writing, and manipulating WARC files plus their index CDX files
CLI Application
The WARC reader/writer was implemented as a CLI application that can perform various other tasks related to WARC file as well. The code can be found on Github with instructions. Below is the link plus explanations of the various capabilities of the program
Github repo of application
Code download: warcfilter.zip
WARC files
Web ARChive or WARC files are a file format tailor made to for archiving resources from webpages. They are mostly used for historical preservation purposes.
Each WARC file is a concatenation one many WARC records. Each record is a web resource of some kind usually obtained from a web crawl like a web page or
a image. A WARC record can be broken down in two distinct parts a WARC header and the content block. With the WARC header containing some information about
the content block.
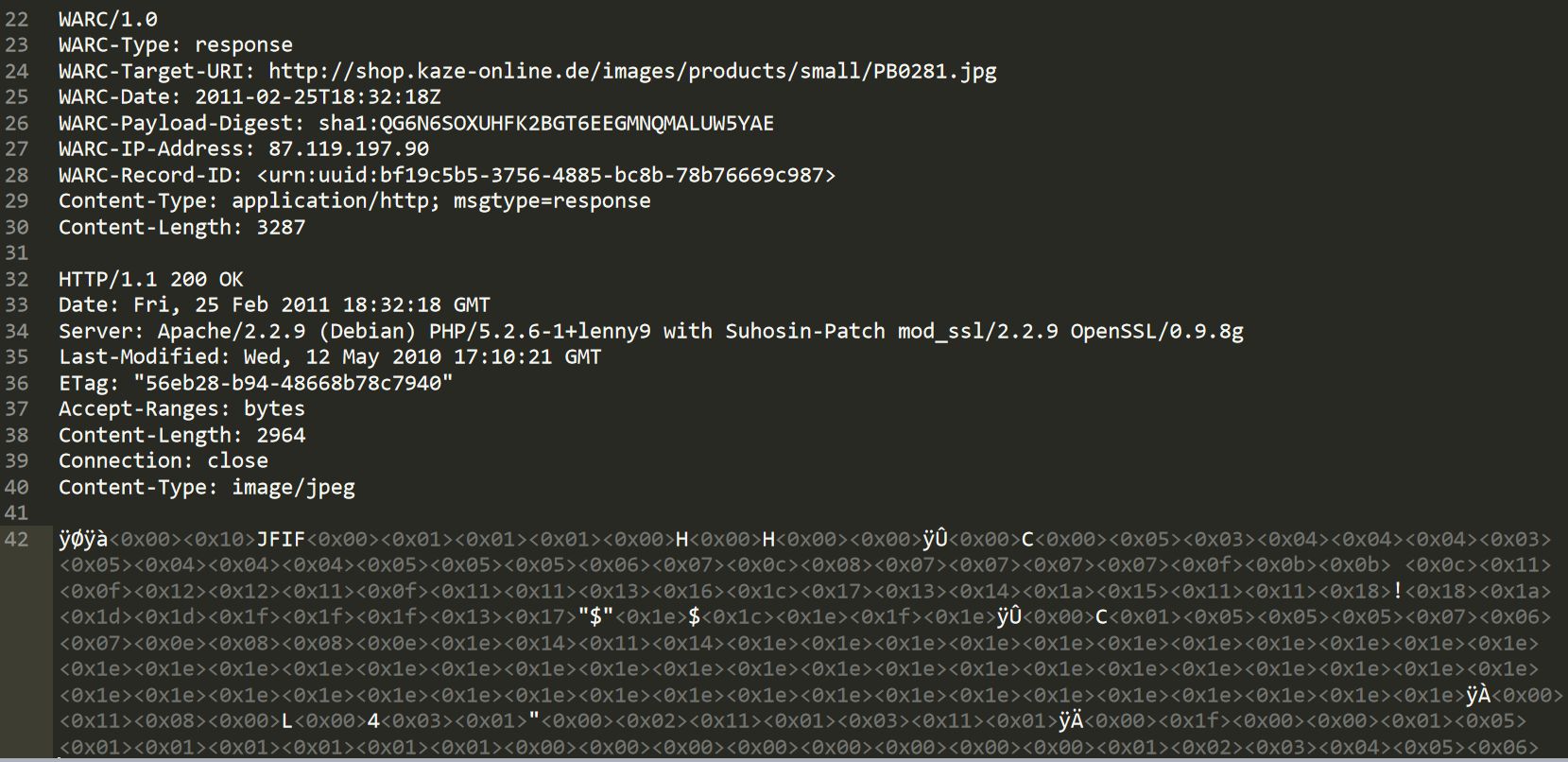
WARC file specifications
Basic WARC Parsing
WARC files are usually very large and so are gzipped. So to efficiently parse them streams are necessary along with the Node.js built in zlib library for decompression
purposes. WARC record headers all start with this line 'WARC/1.0'. So, when this line is encountered just keep reading until a another header line is encountered.
Once another line is encountered that means all the previous lines as a record.
WARC filtering
An objective of the parser was to be able to retrieve and filter out specific WARC records based on some criteria. So, for this parser the ability to filter records are based
on 3 criteria. The url of where the content was retrieved from, the file type of the content of the record i.e jpg, png, html, etc., and the date or date range the record
was retrieved from. All 3 criteria are implemented in the parser's cli program and will write WARC records that meet user specified criteria to a specified destination file. The
parser is also able to read from multiple WARC files for if a user wants to create new WARC files from multiple sources.
CDX files
CDX files are used to index records in WARC files. A CDX file contains a header line specifying the format of all subsequent lines.
All subsequent lines universally contain the URL of a WARC record, information about the record, and offset plus length of the record in a WARC file.
Thus you can read a CDX index line and then read the subsequent offset specified to retrieve the WARC record in a WARC file
quickly.
CDX file specifications

CDX Parsing
CDX files are simple to parse as you just need to read the first line in the CDX file then parse generate the format structure based on the official CDX file specifications.
Then read line by line retrieving and parsing the line according to that format structure. In the CDX structure there should be a WARC file name and offset where we can use
to quickly retrieve the CDX record associated with this index.
CDX Filtering Works much like the WARC file filtering except made easier as the CDX index itself usually contains the url, content type, and date of the WARC record. So, indexes themselves can be filtered out before even reading the WARC file itself. The output of the cli program will be much like the WARC parser a WARC file containing records that meet the user specified criteria.
CDX Creation
With the parsing of WARC parser and CDX files completed another objective of this deliverable was to be able to create your own CDX files.
Since, the parser in before write new filtered WARC files we would also want to be able to index those newly created WARC files as well. To create a CDX file is the same as parsing a WARC file instead this time instead of filtering record we take every record but break down it's information such as record url and offset then write it to the newly created CDX file.
Web Graph file creation from Common Crawl WAT files
One use case for WARC file parsing is to generate files URL pair files that are used to generate web graphs. Common Crawl have their web crawls available to the public in WARC format, CDX format, and even other types of WARC formats such as WARC Archive Transformation or WAT format. The WAT format is the same as a WARC in structure with a header and content except the content portion is replaced by a JSON object containing metadata of the content rather than the content itself.
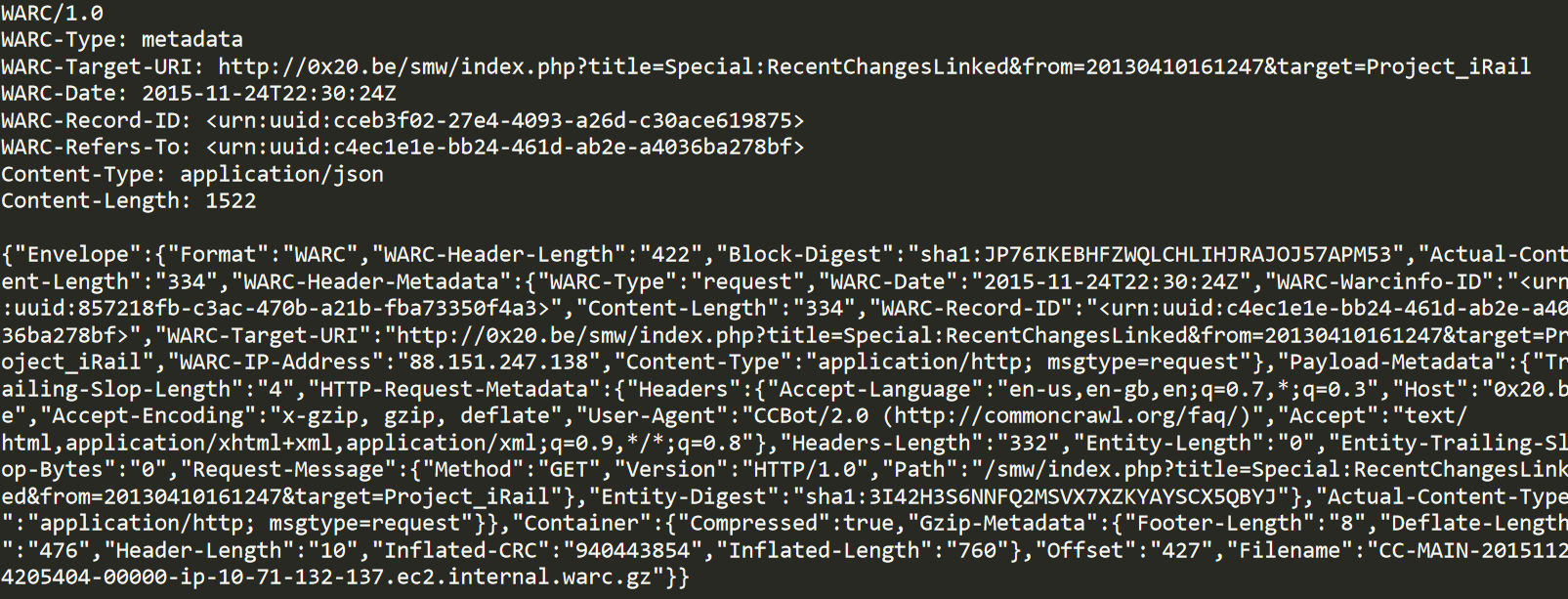
Web Graph dataset creation from Common Crawl data
A feature in the created CLI parser is to pass in a WAT path file from the Common Crawl dataset which will then read the paths in the file and stream the associated WAT file. Parsing the WAT file
we retrieve only HTML type records and write to a destination file the URL the record was retrieved from and any links on the page as pairs to the destination file. The output file will contain url pairs separated by a space each line. The cli program can limit the number of WAT files read as well as the offset into the path file to read from.
