Chris Pollett >
Students >
Bui
( Print View)
[Bio]
[Blog]
Consistent hashing implementation
David Bui (david.bui01@sjsu.edu)
Purpose
The goal of this deliverable was to create a consistent hashing implementation on multiple instances of a key value store. As we are able to create multiple server instances in Node.js this is useful for distributing data among multiple Node.js servers for faster access times.
Consistent Hashing
Consistent hashing is a specialized hashing technique for distributing hashed keys among servers also called nodes. Originally invented as a way to distribute web pages among cache servers to alleviate web load, it can also be applied to key value pairs and distributing key-value pairs among servers. Keys are hashed using a ranged hash function typically from 0 - 1 to create a circle pattern like a unit circle. Each server/node is also hashed onto the circle. Keys hashed and are assigned to the nearest hashed node value. If a server is added keys are checked to see if they will be assigned to the new server. Likewise if a server is deleted all of it's keys are reassigned to the closest hashed node. Issues with this original idea were that if two nodes were close to each other one would have a greater share of the keys in the other. Another issues was that during a node add/delete the redistribution of keys would usually go to only one node rather than spread out.
The solution for this was to create multiple virtual nodes distributed evenly around the consistent hashing circle for each server. This way keys would go to more than one server whenever this operation would occur.
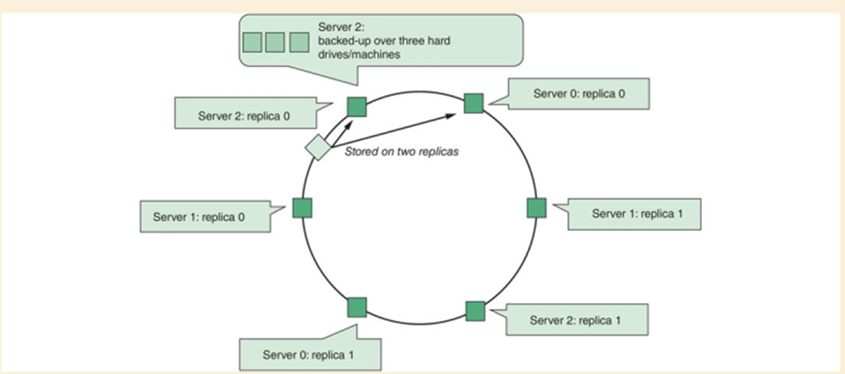
Program
The program similar to Deliverable 3 is a cli program manipulating a 'root server' representing the operations of a consistent hashing circle such as adding a server, deleting a server, and adding additional keys and distributing it among servers. The 'root server' also handles the creation of virtual nodes and can display them at any time. Below is a picture of the virtual nodes mapped to servers.
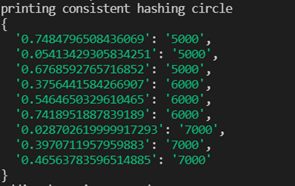
Data in servers
Below is an example of of example data inserts and how the key value pairs are distributed amongst the servers from the virtual nodes in the picture above.
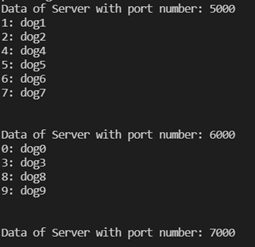
Data redistribution
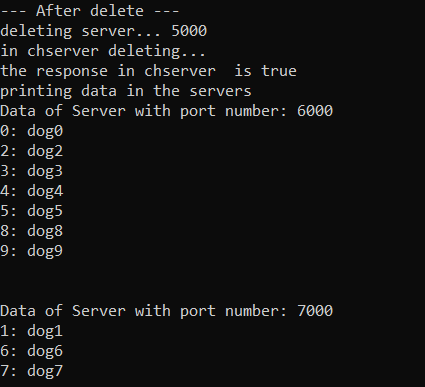
The picture below is after the server on port 5000 is deleted and keys are redistributed.
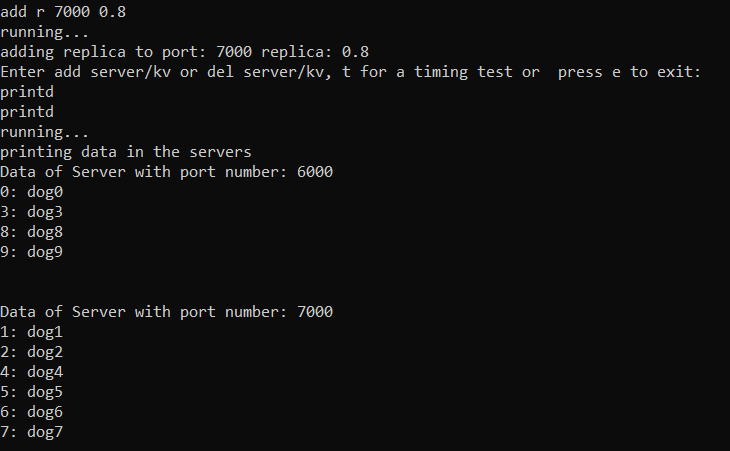
Adding replica
The picture below is after a replica is added for the server on port 7000 taking away keys from 6000 as the new
virtual node is closer to certain keys.