Chris Pollett >
Students >
Padia
( Print View)
[Bio]
[Blog]
The paper proposes a machine learning based cache admission and eviction algorithm. In this framework, a set of features are derived from query logs. The admission and eviction decision are based on a machine learning model trained from these features. The paper proposes machine learning models for both static and dynamic cache. Populating static cache has been modeled as an offline cache allocation problem while the latter has been modeled as an online eviction problem.
To derive features from the query log, AOL query logs were used. The subset of features was selected based on the availability of query logs and Yioop indexing data structures. ‘IAT_NEXT’ is the ground truth value that represents the next time the same query appears i.e., the number of queries between the next appearance of the query. The goal of the machine learning model was to predict the IAT_NEXT value as close to the actual IAT_NEXT value. The query having the highest IAT_NEXT value was evicted if the cache was full.
To create the features, queries were first cleaned (Code: Data Cleaning). The query was converted to lowercase, stop words were removed, and words were stemmed. Features were then extracted from the clean queries. The key observation from the data was that the data was highly skewed. More than 80% of the data had an IAT_NEXT value of less than 1% of the total data (Figure 1). To mitigate this issue, IAT_NEXT values were binned using logarithmic binning. This reduced the effect of skewness in the data (Figure 2). A regression model was fitted and evaluated on this data. (Code: Machine Learning Dynamic Cache Training Zip)
| Features | Description |
|---|---|
| QUERY_HOUR | Hour of the day, query was fired |
| LAST_MIN_FREQ | Frequency of query in last minute |
| LAST_HOUR_FREQ | Frequency of query in last hour |
| LAST_DAY_FREQ | Frequency of query in last day |
| PAST_FREQ Total | frequency of the query |
| IS_TIME_COMPAT | Whether query is time compatible |
| QUERY_LENGTH | Number of words in the query |
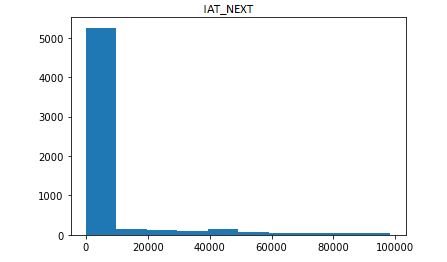
Figure 1: Distribution of IAT_NEXT values
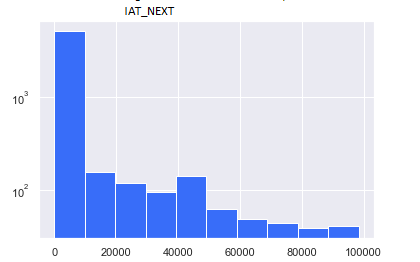
Figure 2: Distribution of IAT_NEXT values after log binning