Chris Pollett >
Students >
Ayan
( Print View)
[Bio]
[Blog]
[Q-Learning for Vacuum World - PDF]
[Playing Atari with Deep Reinforcement Learning - PDF]
[The Arcade Learning Environment - PDF]
Vacuum World with Deep Q-Learning
Description:
Artificial Neural Networks are essentially circuits that are made up of layer(s) of neurons or nodes. Neurons are connected through the means of "weights" between nodes. Over time and with sufficient training, a neural network can optimize these weights to reduce the error between the predicted and expected output. Usually, an activation function controls the amplitude of the output. Artificial neural networks are used for solving artificial intelligence (AI) problems. Deep learning is a modern machine learning technique that utilizes multi-layered neural networks to perform predictions on or analyze data. The models used in deep learning are usually trained by huge sets of labeled data.
The goal of this deliverable is to implement the deep Q-learning algorithm within our vacuum world game. The deep Q-learning algorithm essentially replaces the Q-table from the previous deliverable, with a neural network that can predict the best path to the goal. Our initial hypothesis is to converge upon the shortest path with a much smaller training time (around 200 episodes). Additionally, we aim to see perfect traversal of the vacuum world while the previous version of our agent was not perfect.
Files:
[vacuum-world-deep-q-learning.ipynb]
Tools:
Use the OpenAI Gym environment for world building:
i) Provides encodings for actions
ii) Allows generation of random walks without too much hassle
iii) The frozen lake environment provides encodings within an adjacency matrix as such: S = Start position, G = Goal position, F = Frozen path
Training and testing:


Neural network architecture:
Diagram generated at: alexlenail.me
Layer 1 (Input Layer): N^2 inputs. In the diagram below, there are 16 inputs for a 4x4 world.
Layer 2 (Dense Layer): 32 inputs and outputs.
Layer 3 (Output Layer): 4 outputs, each corresponding to one direction to the next state.

Steps to run the file:
1. Download the file above.
2. Log into Google Colab or Jupyter Lab.
3. Select import/upload notebook.
4. Upload this file.
5. Select "Run All Commands".
Experiment 1:
Initial state of 4x4 World:

S indicates the start position at 1,1 and G(the goal) indicates the dirt, which lies at position 4,4.
The following output was obtained after training on 200 episodes:
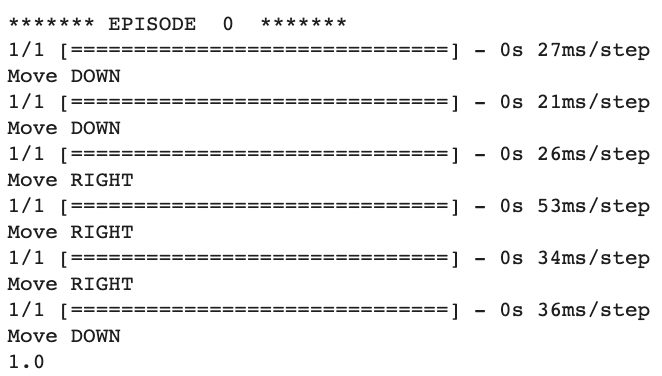
The bot is able to locate the dirt in the world in 6 moves, which is the shortest path possible.
Experiment 2:
Initial state of 4x4 World:

S indicates the start position at 1,4 and G(the goal) indicates the dirt, which lies at position 4,4.
The following output was obtained after training on 200 episodes:

The bot is able to locate the dirt in the world in 3 moves, which is the shortest path possible.
Observations:
We observe that the agent is able to locate the dirt successfully at the appropriate cells without any errors. This behavior is what we desired from this deliverable and improves upon our basic Q-learning implementation from deliverable 1.