Chris Pollett >
Students >
Ayan
( Print View)
[Bio]
[Blog]
[Q-Learning for Vacuum World - PDF]
[Playing Atari with Deep Reinforcement Learning - PDF]
[The Arcade Learning Environment - PDF]
Deep Q-Network for Ms. Pacman
Description:
Deep q-learning bridges the q-learning algorithm to a deep neural network which operates directly on RGB images. This is the approach that the authors of the paper "Playing Atari with Deep Reinforcement Learning" use to solve games like Breakout and Space Invaders.
The goal of this deliverable is to implement a deep q-network that can play the game of PacMan better than the basic q-learning agent from deliverable 3.
Files:
Tools:
TensorFlow 2.9:
i) The keras API provides bindings for convolutional neural network (CNN) layers, dense layers, loss functions, activation functions and optimizers among other useful features.
Arcade learning environment:
i) Allows import of atari rooms for environment building using the ale-import-roms command line utility.
ii) Once imported, supported roms can be specified as environment arguments for Gym with the following command: env = gym.make("ALE/MsPacman-v5")
stable-baselines3:
i) Provides the atari_wrappers.py library (https://github.com/DLR-RM/stable-baselines3/blob/master/stable_baselines3/common/atari_wrappers.py)
ii) The library allows wrapping of atari game frames into batches of 4, rgb downsampling to greyscale, downsampling of image size, among other features.
iii) The code was copied into the notebook as we cannot import stable-baselines3 on this version of TensorFlow.
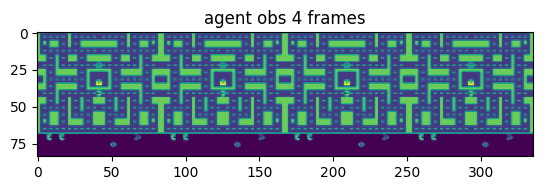
Image 1: batch of 4 frames of Ms. Pacman generated by the Atari wrappers in stable-baselines3
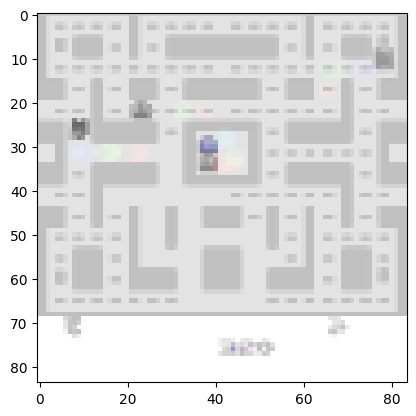
Image 2: Sample frame of the Ms PacMan ALE environment after downscaling image size and converting to greyscale using the DeepMind Atari wrappers. This is what the input to the CNN looks like.
Use the OpenAI Gym environment for world building:
i) Provides encodings for actions
ii) Allows generation of random walks without too much hassle
Training and testing:


Neural network architecture:
The neural network implemented is based on the architecture proposed in the research paper "Playing Atari with Deep Reinforcement Learning", by the team at DeepMind.
1. 3 convolutional layers:
i) 32 filters of 8x8, stride of 4, activated by ReLU
ii) 64 filters of 4x4, stride of 2, activated by ReLU
iii) 64 filters of 3x3, stride of 1, activated by ReLU
2. Flattening layer to flatten the output of the convolutional layers.
3. 2 dense layers:
i) 512 neurons, activated by ReLU
ii) 5 neurons (size of the action space for the agent), with a linear activation function
Steps to run the file:
1. All code was developed on Macbook Air running the M1 chip. The following steps were taken to setup the environment:
i) Please follow steps at https://developer.apple.com/metal/tensorflow-plugin/ to set up Tensorflow on Apple silicon-based systems.
ii) Download and install Visual Studio Code: https://code.visualstudio.com/.
iii) Install the Jupyter extension on VS Code.
3. Select open notebook.
4. Open this file.
5. Select "Run All Commands".
Goals for this deliverable:
Outperform the previous iteration of the agent.
Test the deep q-network after training for 5000, 10000, 20000 episodes.
Test the DQN on a reduced movepool, i.e., remove actions ['FIRE','UPRIGHT','UPLEFT','DOWNRIGHT','DOWNLEFT','UPFIRE','RIGHTFIRE','LEFTFIRE','DOWNFIRE','UPRIGHTFIRE','UPLEFTFIRE','DOWNRIGHTFIRE','DOWNLEFTFIRE'], which may be confusing the model in deciding which step is the best step to take.
Computation time to train the Deep Q-Network for this task:
4000 episodes: 20 mins
10000 episodes: 1 hour
25000 episodes: 3 hours
50000 episodes: 7 hours 20 mins
Experiment 1:
Experiment 1Video 1: An agent trained using the deep q-network defined above, playing Ms. Pacman. The agent has been trained over 4000 episodes and survives for 97 time steps.
Experiment 2:
Experiment 2Video 2: Improved performance observed as the agent was trained for 10000 episodes.
Experiment 3:
Experiment 3Video 3: Agent scores a high score of 1400 after training for 25000 episodes.
Experiment 4:
Experiment 4Video 4: This agent acts on a reduced moveset. Diagonal moves (UPLEFT, UPRIGHT, DOWNLEFT, etc) are no longer valid actions. The agent scores a high score of 2570 after training for 25000 episodes. The agent is able to survive for 208 time steps.
Experiment 5:
Experiment 5Video 5: This agent acts on the reduced moveset. The agent scores a high score of 3090 after training for 25000 episodes. The agent is able to survive for 173 time steps.
Experiment 6:
Experiment 6Video 6: This agent acts on the reduced moveset. The agent scores a high score of 3700 after training for 50000 episodes. The agent is able to survive for 216 time steps.
Experiment 7:
Experiment 7Video 7: This agent acts on the reduced moveset. The agent scores 2640 after training for 50000 episodes. The agent is able to survive for 272 time steps. Of particular importance here is the fact that while the agent does not set a high score, the agent is able to almost win the game at this stage, with only 6 pieces of food remaining at the end of this trial.
Observations:
The deep q-network is able to break the threshold scores of 200, from the previous deliverable, deliverable 3. In deliverable 3, we observed the limited understanding of the game's environment by the agent. The agent mostly just moved along one path and then stopped moving once it reached a dead end. In this deliverable, we see the agent is actually playing to win the game. Due to limited compute power, there is a limit to the amount of episodes the keras neural network can be trained for. However, we observe the agent's performance is improving as the number of episodes increase and the game is solvable with enough training.