Chris Pollett >
Students >
Ayan
( Print View)
[Bio]
[Blog]
[Q-Learning for Vacuum World - PDF]
[Playing Atari with Deep Reinforcement Learning - PDF]
[The Arcade Learning Environment - PDF]
Q-learning agent for Ms. Pacman
Description:
Q-learning is a form of reinforcement learning (where an agent learns about a world through the delivery of periodic rewards) that allows our agent to act on a quality-function, Q(s,a), that denotes the sum of rewards of from state s onwards if action a is taken.
The goal of this deliverable is to apply the research into reinforcement learning over this semester to implement an agent that can play Pacman by maximizing its possible Q-values at each time step.
Files:
Please see the "Files" section under Deliverable 4.
Tools:
TensorFlow 2.9:
i) The keras API provides bindings for convolutional neural network (CNN) layers, dense layers, loss functions, activation functions and optimizers among other useful features.
Arcade learning environment:
i) Allows import of atari rooms for environment building using the ale-import-roms command line utility.
ii) Once imported, supported roms can be specified as environment arguments for Gym with the following command: env = gym.make("ALE/MsPacman-v5")
stable-baselines3:
i) Provides the atari_wrappers.py library (https://github.com/DLR-RM/stable-baselines3/blob/master/stable_baselines3/common/atari_wrappers.py)
ii) The library allows wrapping of atari game frames into batches of 4, rgb downsampling to greyscale, downsampling of image size, among other features.
iii) The code was copied into the notebook as we cannot import stable-baselines3 on this version of TensorFlow.
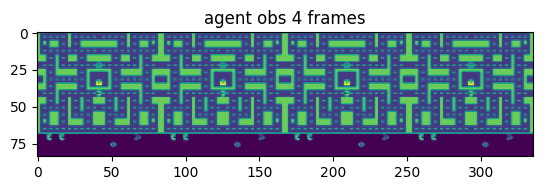
Image 1: batch of 4 frames of Ms. Pacman generated by the Atari wrappers in stable-baselines3
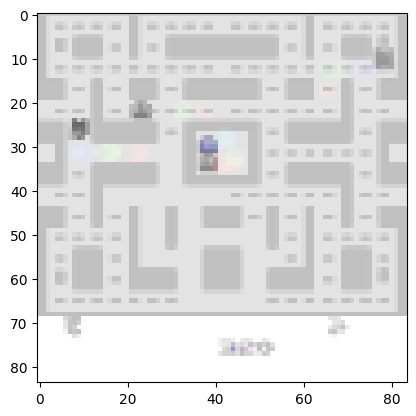
Image 2: Sample frame of the Ms PacMan ALE environment after downscaling image size and converting to greyscale using the DeepMind Atari wrappers. This is what the input to the CNN looks like.
Use the OpenAI Gym environment for world building:
i) Provides encodings for actions
ii) Allows generation of random walks without too much hassle
Training and testing:


Neural network architecture:
The neural network implemented is based on the architecture proposed in the research paper "Playing Atari with Deep Reinforcement Learning", by the team at DeepMind.
Under construction.
Steps to run the file:
1. All code was developed on Macbook Air running the M1 chip. The following steps were taken to setup the environment:
i) Please follow steps at https://developer.apple.com/metal/tensorflow-plugin/ to set up Tensorflow on Apple silicon-based systems.
ii) Download and install Visual Studio Code: https://code.visualstudio.com/.
iii) Install the Jupyter extension on VS Code.
3. Select open notebook.
4. Open this file.
5. Select "Run All Commands".
Experiment 1:
Experiment 1Video 1: An agent trained using the network defined above, playing Ms. Pacman. The agent has been trained with a target reward of 110, over 170 episodes.
Experiment 2:
Experiment 2Video 2: Same agent from video 1. However, the agent was only trained for 10 episodes.
Observations:
We observe that the agent is able to interpret and navigate the PacMan successfully. This behavior is what we desired from this deliverable. Due to the limited compute power on the local machine, it is extremely hard to train the agent to solve the game at this point in time. The goal for deliverable 4 will by to implement a deep q-network that will build on the work done here and attempt to actually try to win the game.