Chris Pollett >
Students >
Bhajikaye
( Print View)
[Bio]
[Blog]
Deliverable 4 :
Introduction
Wikidata is an easily accessible RDF database over the web. Every resource in it is classified as either an item or property. Usually the subjects and objects are represented as the item and the predicate are represented as property. Once the parts of a triple are identified by methods like the previous POS tagging, their respective identifiers need to be fetched. This is required because unlike SQL queries, SPARQL does not use resource names but rather resource identifiers. In the select and where clauses we refer to the resource as either Qxx for an item with identifier number xx or Pxx for a property with the identifier number as xx.Model Implemented
To extract the identifiers for the subject, predicate and objects in the input query we wrote a program to connect to the dump and find all relevant items. The first step was to try to download the Wikidata dump on local disk but due to a size of ~56Gb it wasn't possible. Instead, the file could be connected and unzipped batch wise in memory to avoid downloading it. The data format was that of an array of JSON objects. Each JSON object had multiple fields that described a resource.The relevant fields for this study were type, id and label. The type was defined as either an item or property. Other fields included were aliases, description and claims. The labels also included names of the resource in other languages.
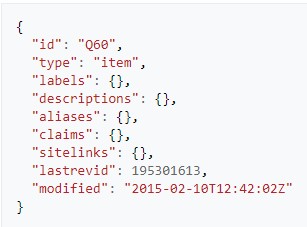

Results
The experiment consumed 5 million JSON objects, of which 1.2 million were discarded for not having a label in the English language. The results for 3 kinds of input queries are shown :
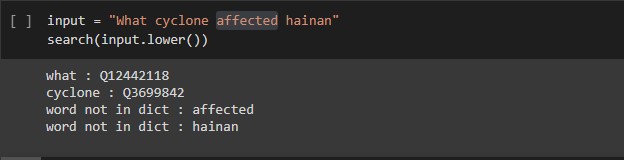
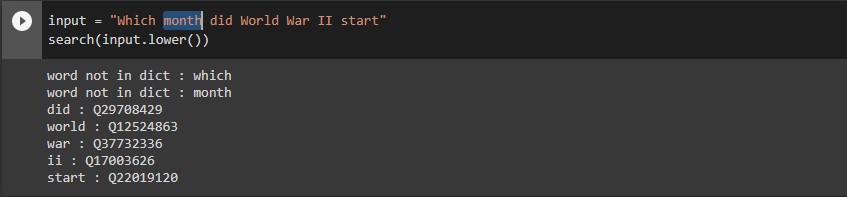
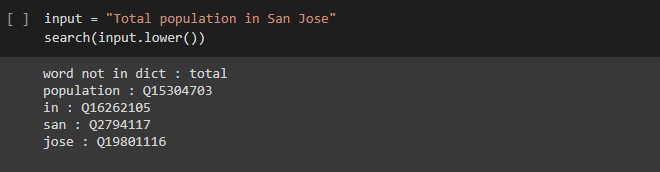
In the last two queries, the terms 'World War II' and 'San Jose' were searched as separate words. To make sure that the program also takes into consideration such situations, the next part searches for all consecutive segments that exists in the database.
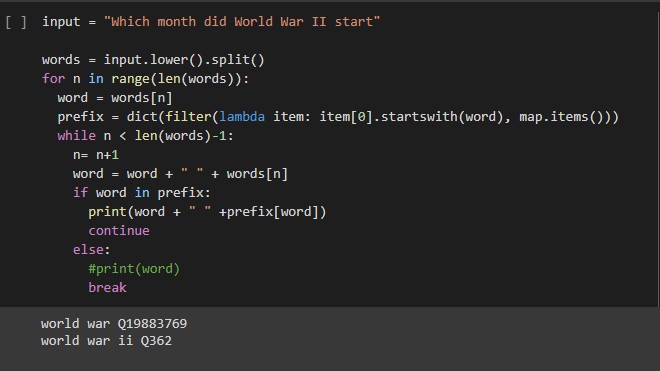
The method is very primitive but works for short sentences since the iterations would be limited. For longer sentences, a more efficient technique would be to search based on char-grams of the words.