Chris Pollett >
Students >
Bhajikaye
( Print View)
[Bio]
[Blog]
Deliverable 3 :
Introduction
The previous deliverable was to implement an existing model for entity matching. It looked at the sentence structure from a subject and predicate perspective. In this deliverable, we try to identify the subject, verb and object parts of the sentence. These are the basic entities required to construct the clauses of the sparql query.Model Implemented
The model structure is an encoder-decoder model. Usually sequence-to-sequence learning is used to translate between two natural languages. It converts sequences from one domain (here, English sentences) to another domain ( the subject, verb and object mapping). The translation is completely at word level here.
The algorithm starts with an input sentence in English and a target sentence with every word identified as either a subject, verb or an object. There are two LSTM networks in the algorithm. The encoder LSTM takes the input sequence of words and processes it for every time step, learning the information for that word. The final output of the encoder is discarded and the final states of the LSTM cell are used as intermediate vectors.
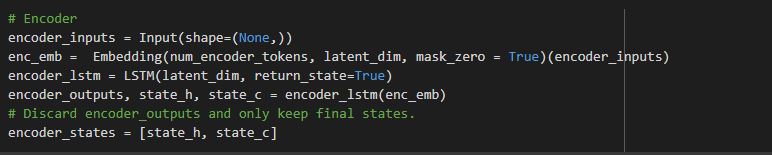
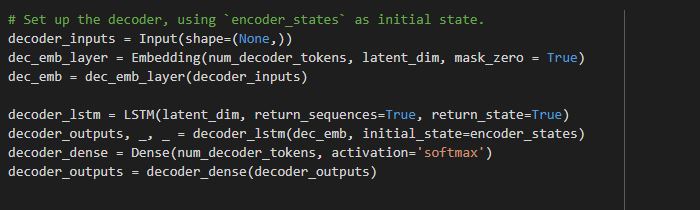
The final states of the encoder are initialized as the initial states of the decoder LSTM cell. The decoder takes input as the start marker along with the required output. At each time step, the LSTM trains on a word to learn the next word in the sequence. The target sequence for a decoder is constructed as the stop marker with the desired output.
Datasets Used
The first dataset was created with 20 random sentences with an average length of 15 words. The words were mapped to the respective entity as either S, V or O in a separate target.txt file.
The second training and testing dataset consisted of 3000 sentences with an average length of 25 words. These sentences were extracted from the Wall Street Journal articles in the Penn Treebank corpus. A similar mapping of S, V and O was done in a separate target file for the sequences.
Results
Training the 20 sentence dataset for 40 epochs results in an accuracy of 95%. On further examination it can be inferred that these results are a cause of the extra padding added at the end of each sentence. For shorter sentences, the padded characters are more than the actual informative characters of the input sentence. This indirectly increases the training accuracy of the model.
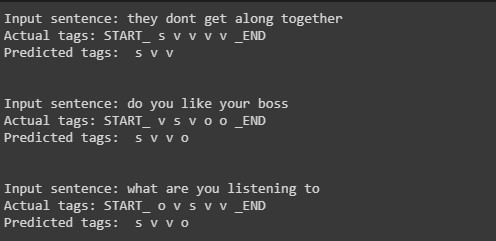
The results for the testing 3 sentences are -
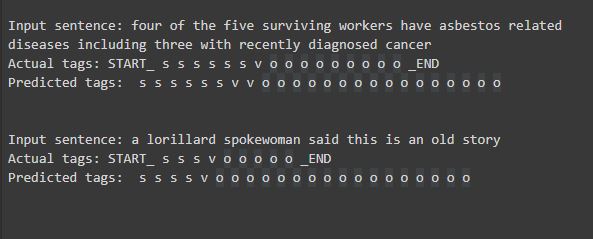
For the 3000 sentence dataset, the results look like -
There are a few issues with the results, the most prominent one being the length of the of the predicted tags. The model does not recognize the _END marker and the padding character correctly. To improve on this a custom loss can be defined to penalize the model over going over the input length. Another issue is the model always recognizes the start of the sentence as a subject token. This could be because of insufficiency of data and variety in it. The dataset needs to be improved to have sentences of all lengths with varied contexts.