Chris Pollett >
Students >
Shawn
Print
View
[Bio]
[299 Blog]
Deliverable 2
This deliverable provides the bulk of the administrative interface for creating, editing, and deleting classifiers. The classifier framework hasn't yet been integrated with Yioop, so creating and editing classifiers just results in simple data structures being created, read from, and serialized to disk in order to save state between requests. Thus the server-side implementation will change significantly for the next deliverable, while the client-side interface should remain mostly the same.
The Classifiers Page
The first page lists any existing classifiers in a table and provides a text input field to create a new one. Classifiers must have unique names, and the names are automatically restricted to alphabetic and numeric characters plus the underscore (significantly, that means no spaces). This is because classifiers are stored in the file system by name. Creating a new classifier refreshes the page to display the updated table of classifiers. For each classifier, the user is presented with its name, the time it was created, the number of positive and negative examples in its training set, and two action links which can be clicked to edit or delete the classifier. As with creating a new classifier, deleting an existing one refreshes the page to display the updated table. Clicking on the Edit link, however, takes the user to a new page where she can change the classifier label and add new training examples.
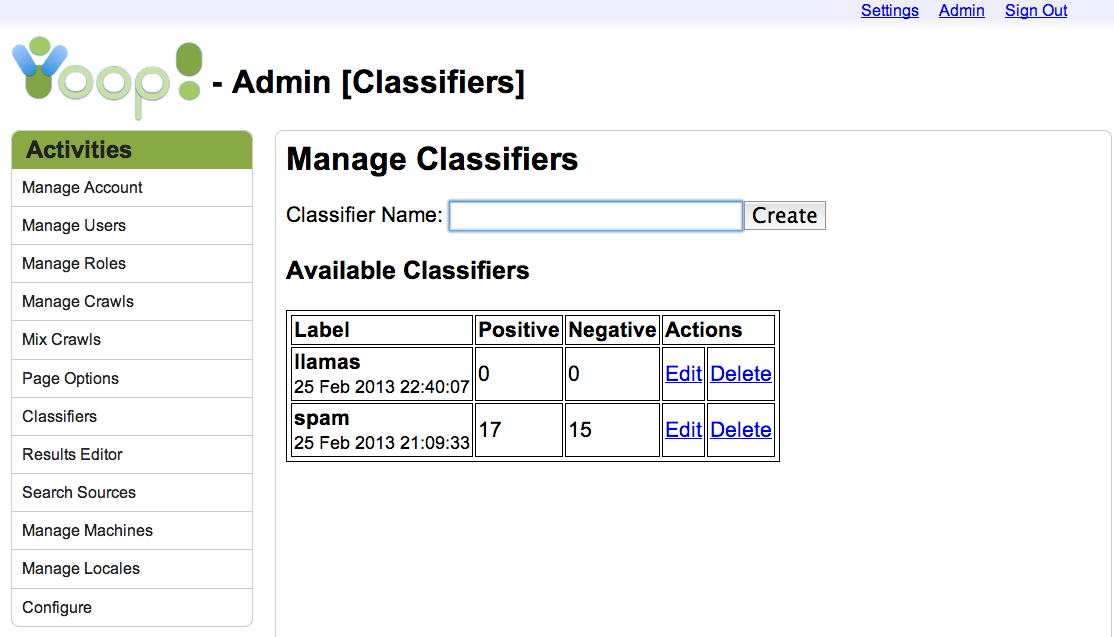
The Edit Page
On this page the user is presented with a text box where she can change the classifier label, and a form which will allow her to execute a query on any previous crawl and label the results, adding to the training set. Alternatively, the user may specify that all documents which match the query are either positive or negative examples, making it easy to provide many training examples in one go. If no specific crawl is selected, then the currently-active index is selected by default.
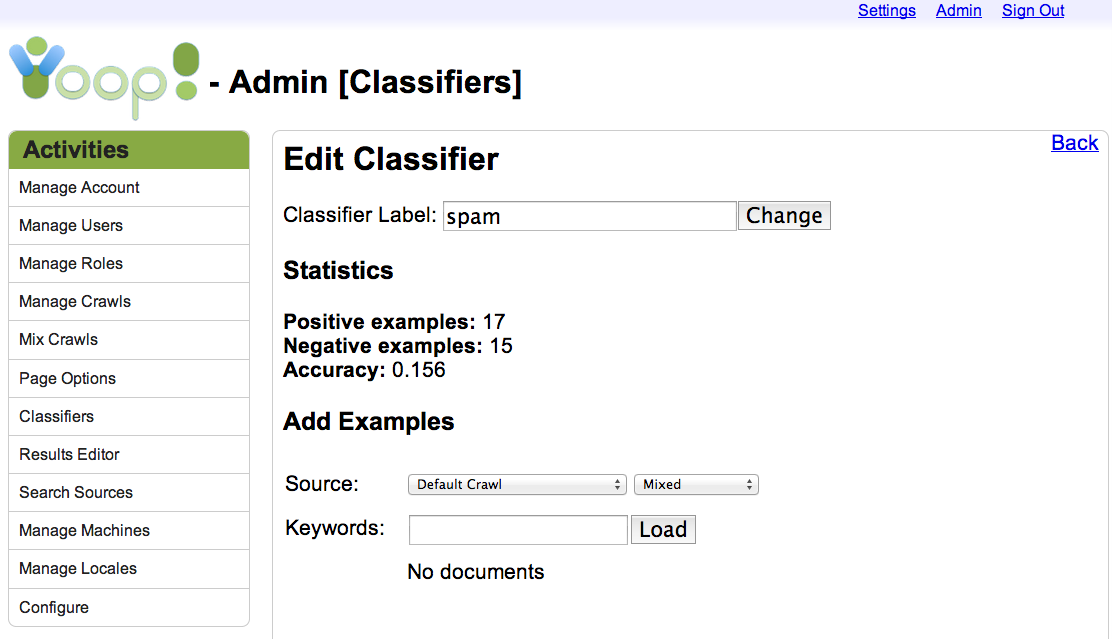
When the user presses the Load button the query is submitted via an XMLHttpRequest to the server, and the server responds with a JSON-encoded data structure that—among other things—includes updated authentication information (used to authenticate the next request) and a collection of documents matching the query. The first document is displayed to the user in a format similar to that for search results (except that the link is to the cache page for the document, rather than to the web page, if there is one), with three extra action links along the left-hand side. These links allow the user to mark the document as a positive or negative example, or to withhold judgement and move on to the next document.
Once one of the action links has been clicked, the new label is immediately sent to the server via another XMLHttpRequest, the next document (if any) is displayed, and the background color of the previous document is changed to indicate that a decision has been reached. The user can always see the previous ten documents that she has labelled (or skipped), as well as the label she selected, and can change the label for each at any time. As more documents are labelled, older ones are eventually removed, and at present there is no way to change their labels after that point. Similarly, if the page is refreshed or navigated away from, then any documents which have been labelled and are still visible on the page will no longer be available to be relabelled.
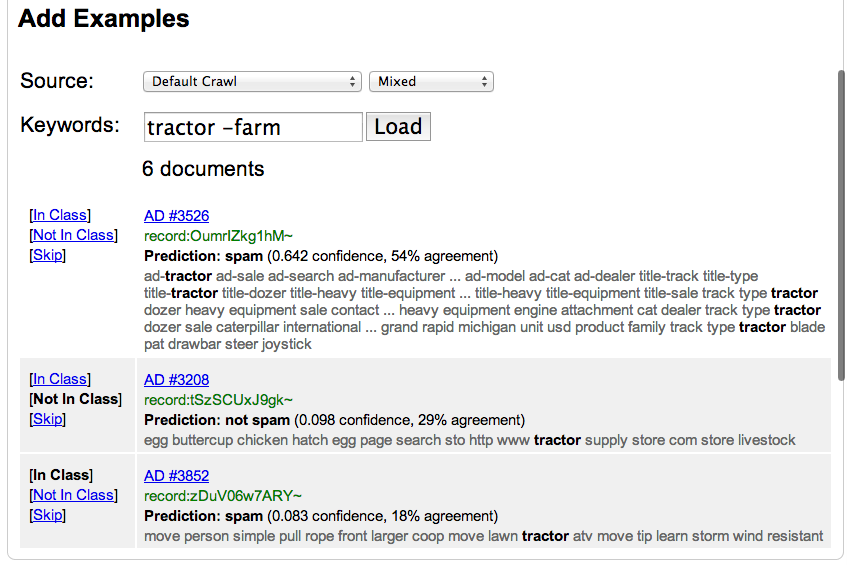
Each time a label is sent to the server the classifier is updated to remember that the associated URL has a particular label, the counts of positive and negative examples are updated, and the classifier accuracy is recalculated (although right now the accuracy is just a random number). All of this information is JSON-encoded and sent back to the browser in the response so that the display may be updated. In addition to the updated statistics, the server may also send back more documents matching the query if the client requests them. This allows for a kind of pagination, where only a few documents are sent at a time, and as each document is labelled, more may be loaded in. A new request is able to pick up where an old one left off thanks to the crawl mix iterator used to iterate through search results, which has built-in support for saving iteration progress (keyed by a timestamp) to the file system. Each classifier has one crawl mix that it reuses to iterate through documents matching different queries; the crawl mix record is created automatically the first time the user issues a query, and is deleted when the classifier is deleted.