Chris Pollett >
Students >
Ajinkya
( Print View)
[Bio]
[Blog]
CS297 Deliverable 2
Testing a few decentralized storage systems based on blockchain
Description: I started out by selecting a few decentralized filesystems based on multiple factors like popularity, available documentation, ease of usage, system architecture and protocols used
Results Following are the results and outcomes which were observed
IPFS is a filesystem which provides a client user interface along with a command line client and also provides great support to developers trying to leverage the filesystem for their applications. It provides limited free storage which comes without any guarantee of persistence of the data. Following is a test case which records the time required to store a file on IPFS and retrieve it.
Following are the results recorded

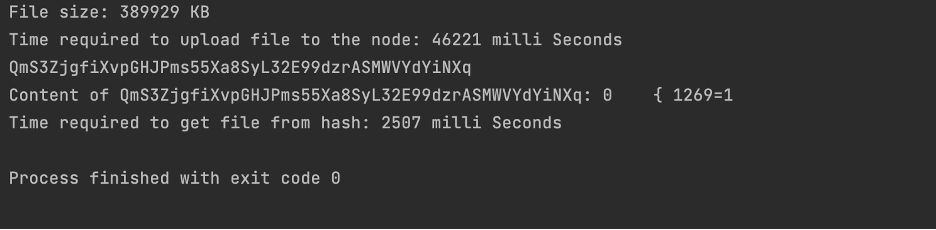
2. Storj
Storj is a cloud based decentralized filesystem based on blockchain which uses storj tokens. Along with the web browser interface it provides a command line client which helped me to time the upload process for a file


As displayed in the terminal it nearly took 751 seconds i.e more than 12 minutes to store a 390 MB file.
While accessing the file it provides information regarding number of nodes storing the piece of the file and its approximate locations over the globe.

3. Sia and SWARM
Sia and SWARM require a few available tokens to store on their systems. No open-source developer supported options were available to execute performance testing. Swarm provides a simple gateway to store a file up to the size 10 MB.
In conclusion IPFS performs better than Storj when it comes to uploading a file as big as 400 MB or 1 GB.
It took merely a few seconds for IPFS to store a 400 MB file and about a couple of minutes to store a 1 GB file. On the contrary Storj nearly took more than 12 minutes to store a 400 MB file.
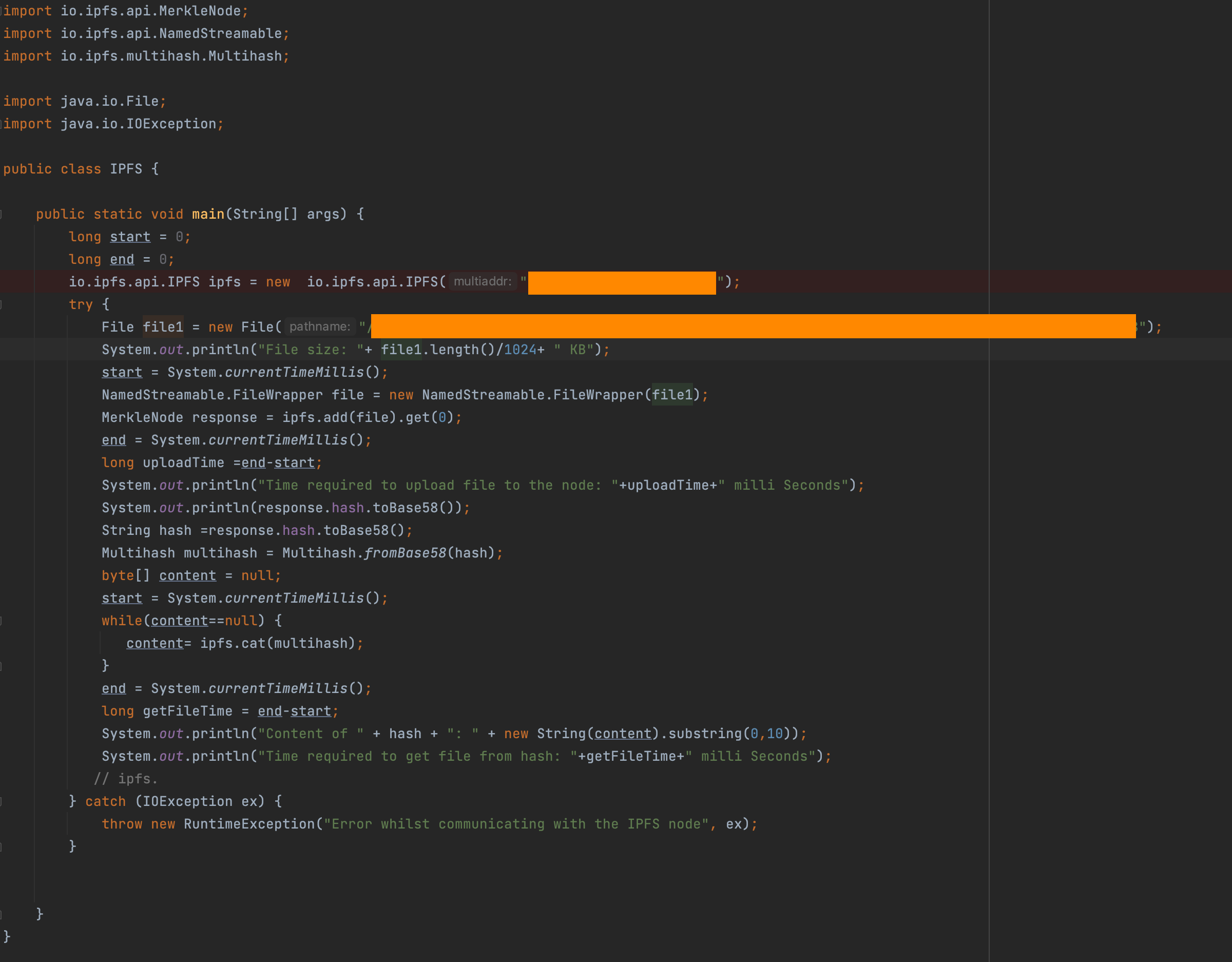
IPFS.java
import io.ipfs.api.MerkleNode;
import io.ipfs.api.NamedStreamable;
import io.ipfs.multihash.Multihash;
import java.io.File;
import java.io.IOException;
public class IPFS {
public static void main(String[] args) {
long start = 0;
long end = 0;
io.ipfs.api.IPFS ipfs = new io.ipfs.api.IPFS("/ip4/127.0.0.1/tcp/5001");
try {
File file1 = new File("/Users/ajinkyarajguru/Documents/CS297
/FileSystemPerformance/src/main/resources/part-r-00000-18");
System.out.println("File size: "+ file1.length()/1024+ " KB");
start = System.currentTimeMillis();
NamedStreamable.FileWrapper file = new NamedStreamable.FileWrapper(file1);
MerkleNode response = ipfs.add(file).get(0);
end = System.currentTimeMillis();
long uploadTime =end-start;
System.out.println("Time required to upload file to the node: "+uploadTime+" milli Seconds");
System.out.println(response.hash.toBase58());
String hash =response.hash.toBase58();
Multihash multihash = Multihash.fromBase58(hash);
byte[] content = null;
start = System.currentTimeMillis();
while(content==null) {
content= ipfs.cat(multihash);
}
end = System.currentTimeMillis();
long getFileTime = end-start;
System.out.println("Content of " + hash + ": " + new String(content).substring(0,10));
System.out.println("Time required to get file from hash: "+getFileTime+" milli Seconds");
// ipfs.
} catch (IOException ex) {
throw new RuntimeException("Error whilst communicating with the IPFS node", ex);
}
}
}
I started out by selecting a few decentralized filesystems based on multiple factors like popularity, available documentation, ease of usage, system architecture and protocols used
The experimentation code can be found at [ Download - Zip]