Chris Pollett > Students > Dhole
Print View
[Bio]
[Blog]
[Deliverable #1: Naive Bayes Classifier]
[Hierarchical Agglomerative Clustering - PDF]
[Deliverable #2: Hierarchical Agglomerative Clustering]
[Deliverable #3: Classifiers and Clustering in Yioop]
[Deliverable #4: Recipe plugin scale out]
A study of Classifiers and Clustering in Yioop
Aim
To understand and make a report on Classifiers and Clustering in Yioop
Introduction
Yioop does a number of things to improve the quality of its search results. Yioop Indexes can be used to create classifiers which then can be used in labeling and ranking future indexes. For example, you can add the classifier externally for specific label, like "finance" class and having meta words for it like bank, savings, checking, account, withdraw, credit, debit, etc.
Overview
classifier_tool.php is a command line tool for creating a classifier it can be used to perform some of the tasks that can also be done through the Web Classifier Interface. classifier_trainer.php is a daemon used in the finalization stage of building a classifier. The Classifiers activity provides a way to train classifiers that recognize classes of documents; these classifiers can then be used during a crawl to add appropriate meta words to pages determined to belong to one or more classes. Clicking on the Classifiers activity displays a text field where you can create a new classifier, and a table of existing classifiers, where each row corresponds to a classifier and provides some statistics and action links. A classifier is identified by its class label, which is also used to form the meta word that will be attached to documents.
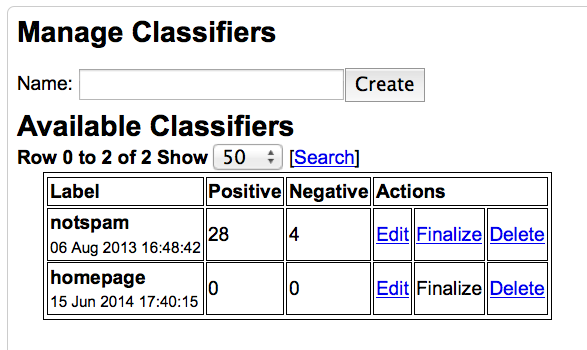
Description
Primary there are following programs, which manage the whole classification in Yioop.
The primary class classifier.php controls the behavior of classification. An instance of this class represents a single classifier in memory, but the class also provides static methods to manage classifiers on disk.
A single classifier is a tool for determining the likelihood that a document is a positive instance of a particular class. In order to do this, a classifier goes through a training phase on a labeled training set where it learns weights for document features (terms, for our purposes). To classify a new document, the learned weights for all terms in the document are combined in order to yield a pdeudo-probability that the document belongs to the class.
A classifier is composed of a candidate buffer, a training set, a set of features, and a classification algorithm. In addition to the set of all features, there is a restricted set of features used for training and classification. There are also two classification algorithms: a Naive Bayes algorithm used during labeling, and a logistic regression algorithm used to train the final classifier. In general, a fresh classifier will first go through a labeling phase where a collection of labeled training documents is built up out of existing crawl indexes, and then a finalization phase where the logistic regression algorithm will be trained on the training set established in the first phase. After finalization, the classifier may be used to classify new web pages during a crawl.
During the labeling phase, the classifier fills a buffer of candidate pages from the user-selected index (optionally restricted by a query), and tries to pick the best one to present to the user to be labeled (here `best' means the one that, once labeled, is most likely to improve classification accuracy). Each labeled document is removed from the buffer, converted to a feature vector (described next), and added to the training set. The expanded training set is then used to train an intermediate Naive Bayes classification algorithm that is in turn used to more accurately identify good candidates for the next round of labeling. This phase continues until the user gets tired of labeling documents, or is happy with the estimated classification accuracy.
Instead of passing around terms everywhere, each document that goes into the training set is first mapped through a Features instance that maps terms to feature indices (e.g. "Pythagorean" => 1, "theorem" => 2, etc.). These feature indices are used internally by the classification algorithms, and by the algorithms that try to pick out the most informative features.
Once a sufficiently-useful training set has been built, a FeatureSelection instance is used to choose the most informative features, and copy these into a reduced Features instance that has a much smaller vocabulary, and thus a much smaller memory footprint. For efficiency, this is the Features instance used to train classification algorithms, and to classify web pages. Finalization is just the process of training a logistic regression classification algorithm on the full training set.
A short on command line tool execution of classifier, bin/classifier_tool.php, To build and evaluate a classifier for the label 'spam', trained using the two indexes "DATASET Neg" and "DATASET Pos", and a maximum of the top 25 most informative features: php bin/classifier_tool.php -a TrainAndTest -d 'DATASET' -l 'spam' -I cls.chi2.max=25