Chris Pollett >
Students >
Shawn
Print
View
[Bio]
CS280 Project Blog
I'm working on improving Yioop's archive crawl performance by distributing the work to a scalable number of fetchers (full proposal). Below you'll find my planned schedule for the semester followed by progress reports, with the newest ones at the top.
Schedule
| Week | Plan | Results |
|---|---|---|
| Feb 07 | Write proposal and add class. | Done |
| Feb 14 | Get Yioop installed and prepare diagrams explaining the crawl architecture and network configuration (Deliverable 1). | I installed Yioop, started to familiarize myself with the source, and did an initial web crawl. I didn't have time to draw up diagrams. |
| Feb 21 | Finish previous assignment and write code to fetch successive chunks of web pages from an archive. | Done |
| Feb 28 | Set up project web page. Design the new archive crawl interface and get the name server to send successive chunks of data to fetchers. | Partial I got the project page up and set my schedule, but didn't get the name server sending data. |
| Mar 06 | Finish new front-end interface and set up new filesystem organization for Wikimedia archives. | Done Archives are showing up as choices in the archive crawl list, and the appropriate settings are saved. |
| Mar 13 | Specify common archive bundle iterator interface, and implement for Wikimedia bundles. Get new archive crawl process working for Wikimedia archive bundles with at least one fetcher. Fix the standard web archive iterator to take into account fetcher number. | Partial I fixed up the old archive crawl interface, but still didn't get the modifications to the crawlTime done. |
| Mar 20 | Study popular distributed file systems and identify architecture features that are applicable to Yioop. Get archive crawls working with multiple fetchers. | Incomplete due to lack of time. |
| Mar 27 | Continue to study popular distributed file systems and improve distributed crawl architecture. Implement common archive bundle iterator interface for arc archives. | Progress |
| Apr 03 | Continue to work on distributed crawl architecture and implement common archive bundle iterator interface for ODP RDF archives. | Progress I ran into issues with slow performance on MediaWiki archive reading. |
| Apr 10 | Continue to work on distributed crawl architecture and implement common archive bundle iterator interface for Web archives. | Progress I implemented bzip2 decompression in PHP and modified the MediaWiki iterator to use it. |
| Apr 17 | Finish implementing code changes with the exception of final tuning (Deliverable 2). | Complete |
| Apr 24 | Test various tuning parameters for a distributed crawl. | Complete |
| May 01 | Continue testing and start on report of experimental results. | Complete |
| May 08 | Report on experimental results (Deliverable 3). | Complete |
| May 15 | Final patches to implement experimental results (Deliverable 4). | Complete |
Progress Reports
Note that newer progress reports come at the top.
May 15
I've completed the majority of what I set out to do, and written up my results in a report (pdf). As the report mentions, I ended up spending a lot of time modifying the existing archive iterators to be able to save and restore state between requests to the name server for batches of pages. In the end, the new distributed crawl process should be working for ARC, MediaWiki, and ODP RDF bundles. Web re-crawls and live web crawls should work exactly as they always have. I didn't have as much time as I wanted in order to test the system, and I suspect that once it's used to crawl a very large archive (like a full dump of Wikipedia) we will find that the tuning parameters need some work.
In the coming weeks I may get an opportunity to test the system out on several virtual machines provided by SJSU in order to try out a full Wikipedia crawl.
Finally, as part of my experiments with seeking into bzip2 files, I converted a minimal Javascript implementation of bzip2 decompression into PHP. I ended up pursuing a much faster heuristic strategy (using a regex to match the magic number at the beginning of each block), but someone may have some use for doing bzip2 decompression in PHP, so I've posted the code here.
April 10
As per our discussion I found a javascript implementation of bzip2 decompression and converted it to PHP. After verifying that the PHP implementation was capable of decompressing a file compressed using the standard bzip2 utility, I added support for serializing the PHP class that implements decompression, and restoring at a particular offset into the compressed file. I then modified the MediaWiki archive iterator to use this class to decompress MediaWiki archives, and to actually save state and restore partially through the file, rather than starting over at the beginning each time.
April 3
I implemented most of the new archive crawl procedure, and got data moving between the name server and a fetcher, and between a fetcher and a queue server. I need to decide whether compressing the page data (after it's decompressed and parsed from the archive) has large enough savings in network bandwidth to justify the cost of compressing on the name server and decompressing at the fetcher. I also ended up modifying the protocol a bit to better mirror the normal web crawl flow, where the fetcher gets a new crawl time from the name server and then gets updated crawl parameters from the current queue server.
I ran into a problem working with MediaWiki archives because PHP doesn't allow seeking on files opened with bzopen, which makes efficiently restoring the archive iteration state between requests for batches of archive data infeasible. After the first few blocks of pages, the requests just time out.
March 20
I fixed up old archive crawls to work with all of the various archive iterators, and submitted my changes to go out with the next Yioop! release, but otherwise made no progress. I plan to catch up over Spring break by actually making the necessary changes to send archive data over the local network.
March 13
I got old web archive crawls working again, and continued to work on setting up the new archive crawl architecture. I modified the web archive bundle iterator to take a prefix as an extra parameter, which it uses to find the appropriate archive to iterate over. While trying to re-crawl my previous web crawl, the iterator ran into the following error after processing the first 5030 pages:
0-fetcher.log:13334: Web archive saw blank line when looked for offset 123890950
I had a lot of work this past week to prepare for an upcoming project due date, and so I'm behind on specifying a common archive iterator interface and getting new crawls started. I'm planning to do what I can this week and next, but I expect to have to catch up over the break. I've determined that I definitely need to modify the crawlTime logic to let the fetcher know that the new crawl is an archive crawl, because right now except in the case of resuming a crawl, the fetcher gets all of the initial crawl information from the first queue server that it contacts. I'll need to modify the checkCrawlTime function in fetcher.php to have an even more complicated return, such that it can signal resuming a crawl, starting a new archive crawl, or starting a new web crawl.
March 06
I continued to work toward implementing the new archive crawl logic. I modified CrawlModel::getCrawlList to search for old web crawls in the usual place (PROFILE_DIR/cache/), but to also search under PROFILE_DIR/cache/archives/ (when $return_arc_bundles is true), and to treat directories found there specially. In particular, these archive directories can have any name, and are expected to contain a file arc_description.ini, which for now has the settings arc_type (which should be MediaWikiArchiveBundle for MediaWiki archives, and should be similarly-named for other archive types) and description, which will end up being the description of the crawl. The crawl time for the archive is taken from the filectime() of the directory.
I modified the admin controller and CrawlModel::setSeedInfo to store the archive type and the path to the archive directory in crawl.ini, and to make those settings available when the crawl is started via CrawlModel::sendStartCrawlMessage. The next step is to propagate that information when actually starting the new crawl, and to modify the fetcher to detect the archive crawl and check in with the name server instead of the queue server for the crawl settings.
I also worked on fixing up the normal re-crawl process. I modified the fetcher to set its own fetcher number to 0 if it isn't given a number when invoked, and rewrote the logic where it writes files to always prefix the file name with its fetcher number. So now the fetcher finds the appropriate archive directory, but it doesn't get any data because the iterator doesn't know about fetcher prefixes. As part of building a consistent archive iterator interface, I'll be changing iterators to work with filenames instead of just crawl times, so that they don't need to be so aware of file structure. That should fix this particular problem.
February 28
I worked out a schedule for the rest of the semester and set up the project blog with my work so far and the full schedule. I tried getting an archive crawl going on a previous web crawl, but I couldn't get the fetcher to recognize the archive. So I moved on to reading the Yioop source to figure out how the list of available archives gets generated, and how an archive crawl procedes now.
The user interface will remain effectively the same for now. The only major differences happen on the backend; it should take less work on the command line to set up an archive crawl. It should suffice to create a directory under the (new) CRAWL_DIR/cache/archives directory with a file indicating the archive type, and any archive files.
Outline of code changes:
- crawl_model.php
- getCrawlList — needs to be modified to search a new archives-only directory, which lives under the cache directory.
- aggregateCrawlList — similar to getCrawlList
- fetcher.php
- loop — needs to handle a new archive crawl message from the name server, passed along as part of the result of checkCrawlTime. This requires setting up the appropriate directories if they're not already set up and dealing with the initial page data. In the case that an archive crawl has already been initiated, needs to avoid the call to checkScheduler, since the fetcher no longer gets its schedule from queue_servers.
- checkCrawlTime — needs to handle a new archive crawl.
- downloadPagesArchiveCrawl — needs to be modified to request the next block of data from the name server.
- updateFoundSites — logic for sending data to queue servers needs to be tweaked, since now the fetcher could have data for any and all of the queue servers.
- updateScheduler — maybe, for the same reasons as updateFoundSites.
- fetch_controller.php
- archiveSchedule — new; needs to handle sending a new batch of pages (from the name server)
- crawlTime — needs to handle signaling a new archive crawl to the fetcher, along with sending initial page data.
For next week I need to actually make the changes to implement the new protocol for archive crawling, and get the name server sending chunks of pages for Wikimedia archives.
February 21
I drew up a diagram of a typical Yioop network configuration, another diagram of a typical web crawl from a single fetcher's perspective, and a final diagram of my proposed archive crawl, again from a single fetcher's perspective:
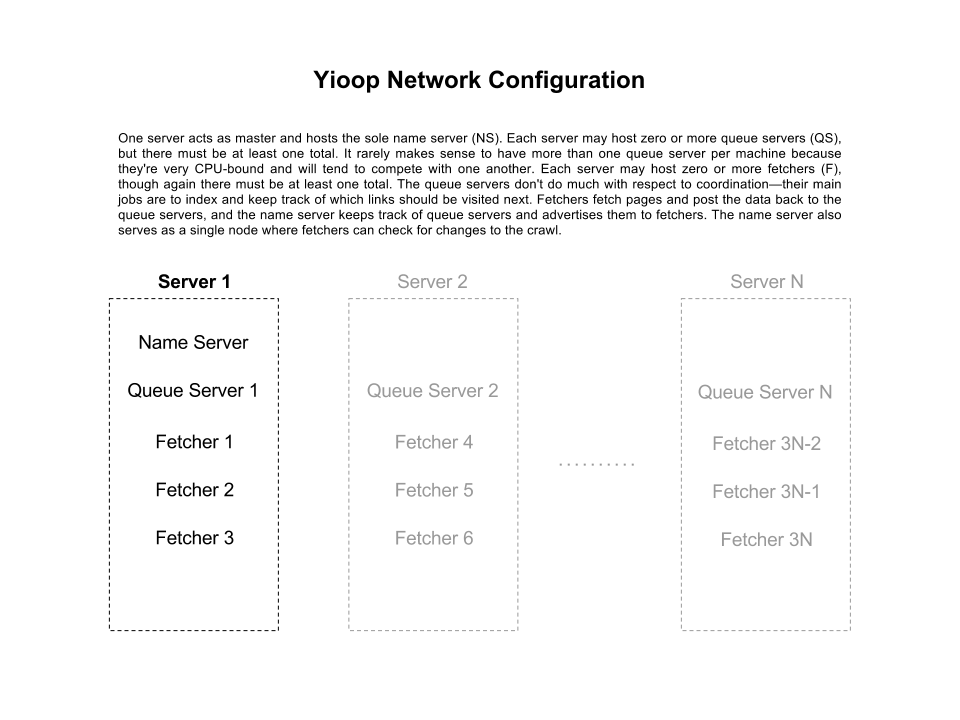
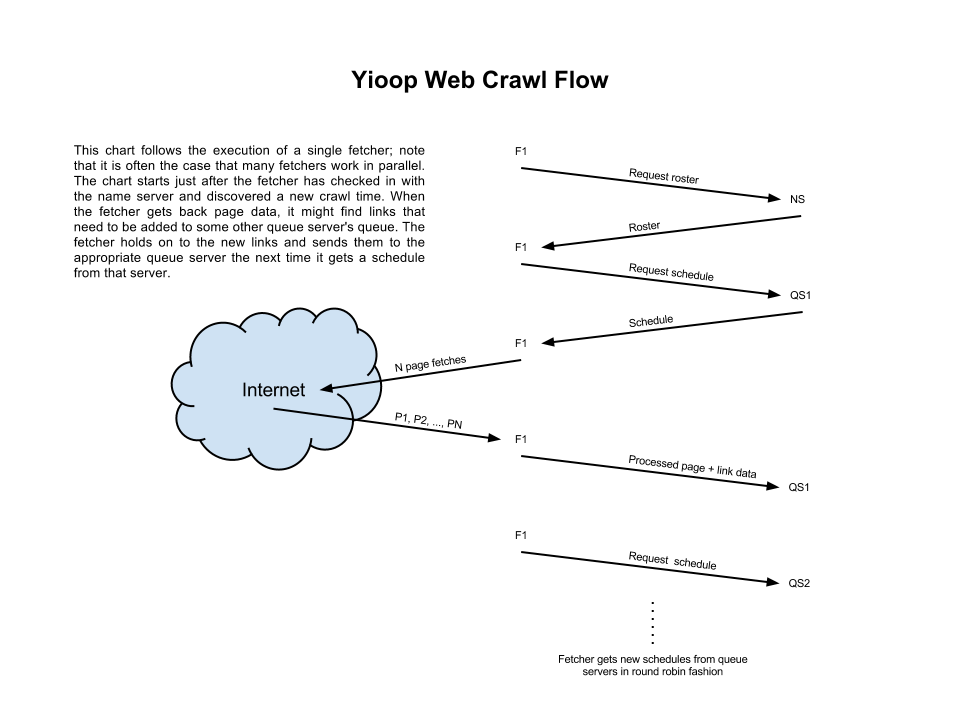
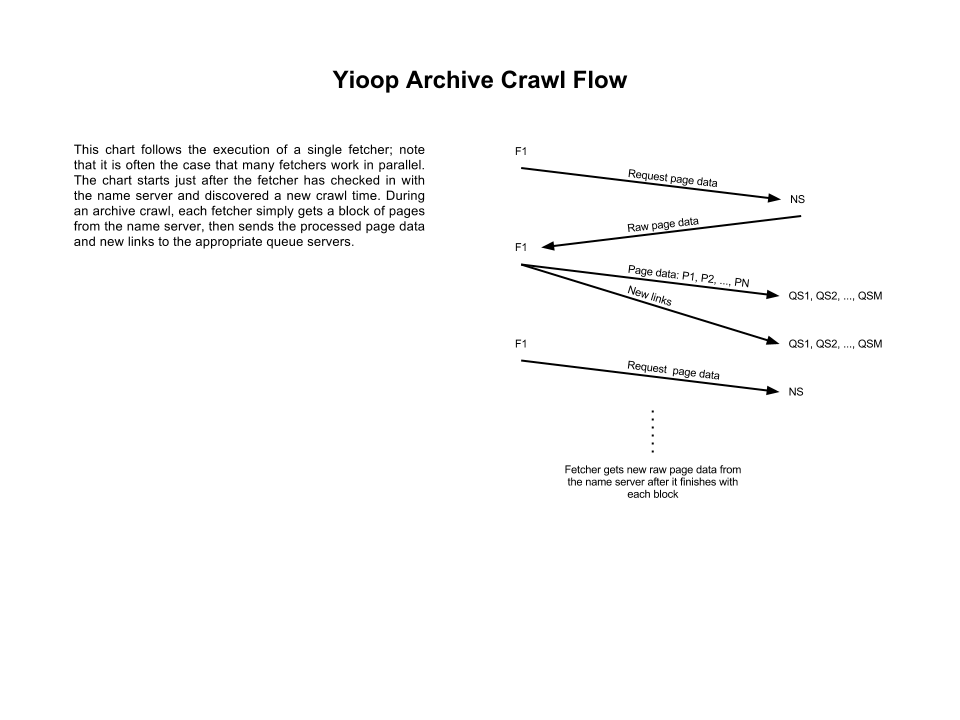
I also wrote some code to use the wikimedia archive bundle iterator in order to fetch chunks of page data from a wikimedia archive. In the process I learned that bundle iterators don't implement a standard interface, which I'll almost certainly want to change as I add a unified interface for performing archive crawls.
I found that fetching pages from an arbitrary offset in the archive file was very slow. I'll need to investigate options for speeding up the time it takes to read from the archive in general, and if we want to be able to stop and re-start archive crawls then I'll also need to investigate creating an index as iteration proceeds, so that it's fast to seek to an arbitrary point.