Chris Pollett >
Students >
An
( Print
View )
[Bio]
[Del1]
[Del2]
[Del3]
[Del4]
Overall Structure
Description: In this deliverable, we introduce our database architecture concentrating on its logical and physical storage representations. Our database consists of a Document Manager, a Query Engine, a Tree Storage Manager, a Storage Manager, and a Recovery Manager.
The Storage Manager is responsible for storing document trees on disks or files and retrieving data back into memory. For simplicity, a page is our storage unit. When a specific page is accessed, our sub-system will first look for the page in the buffer pool in main memory. If the page is not found in memory, the Storage Manager performs fetch operation and loads the requested page and the two pages that follow into memory.
Below are brief explanations of our components:
Tree Storage Manager: like NATIX, it maps trees used to model documents into pages.
Document Manager: provides API for applications to access XML documents.
Query Engine: analyze queries (based on our DML) and returns appropriate result(s) or action(s).
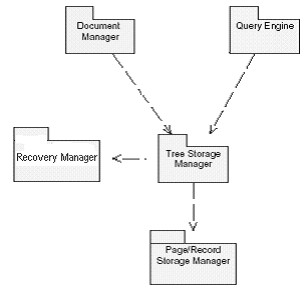
Storage Manager:
The Storage Manager is composed of Logical and Physical parts as describe below:
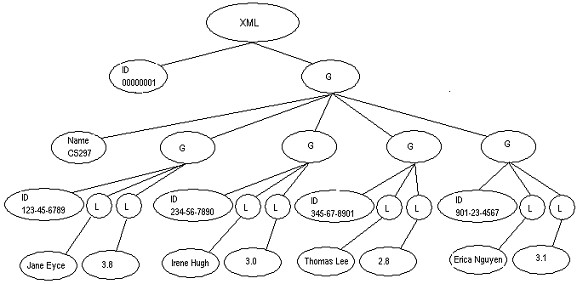
Logical Model: like NATIX, we map XML Elements tree nodes one-to-one onto our logical data model. Attributes are mapped to child nodes. However, for simplicity sake, our XML document contains only 3 types of tags and will be discussed in more details in deliverable 2.
Example 4: The following is an example XML document:
<XML ID="00000001">
<<G name="CS297">
<G id="123-45-6789">
<L>Jane Eyre</L>
</G>
<G id="234-56-7890">
<L>Irene Hugh</L>
<L>3.0</L>
</G>
</G>
</XML>
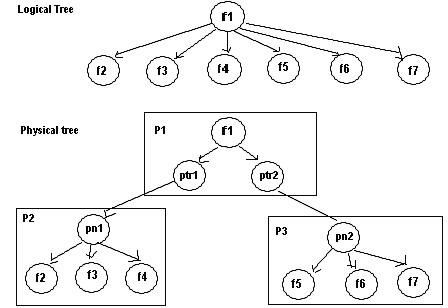
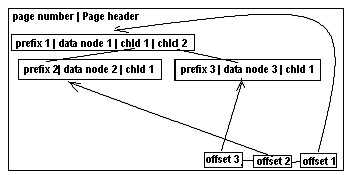
The logical data tree is materialized as a physical data tree and stored on disk(s). Detail structure of a physical page is shown on Figure 14. The page contains a page number, a page header followed by the root node of the sub-tree, and the list of its children. At the end of the page is a list of pointers to reusable nodes in the page. When inserting nodes into a tree results in a page overflow, we split the data tree into sub-trees. This result in the root page of the physical tree containing the Left page number and the Right page number instead of proxy nodes as in NATIX.
Recovery Manager: we plan to implement our Recovery Manager based on NATIX in the Fall, 2004.
Here is the general flow of our database system:
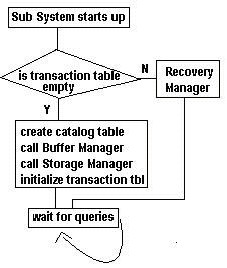
The following is a brief description of our components:
Buffer Manager: we implement Steal/No force for page management and simplified version of Least Recently Use (LRU) page swapping for buffer management. For Steal/No force, the page will be written to disk when it is needed by other transactions or when the Buffer Manager performs page swap without checking the commit status of updates on the page.
Transaction Manager contains a transaction table of active transactions. When a transaction commits, its entry in the transaction table will be removed.
Page management: in the header of every page, there is a flag to indicate if all the updates on this page have been committed. There is also a flag in every data field's prefix that indicate if the individual data field is committed and ready for reuse. The prefix also has a 4 byte field containing the length of the data field. At the bottom of the page is an ArrayList page map.
When a DML is submitted, it is scanned, parsed, and then analyzed. Then, it is passed to an agent to execute.
JUnit Testcase: At each stage of coding, we also provide corresponding unit testcases so that when new code is added, we can make sure the new code path does not regress the already working version. It also helps in debugging and diagnosing a specific error. Following is an example of a testcase that has many test steps:
/**
*Title: The following class is a unit testcase that will
* start our database sub-system,
* read dml6.txt and execute statements in dml6.txt.
*Date: Spring 2004
*Author: Thien An Nguyen
* Advisor: Dr. Chris Pollett
*/
package cs297.xmldb.unit.server;
import junit.framework.*;
import java.util.*;
import java.lang.*;
import java.io.*;
import cs297.xmldb.src.server.*;
import cs297.xmldb.src.cm.*;
import cs297.xmldb.src.sm.*;
public class ThTestExecuteDML extends TestCase{
public ThTestExecuteDML(String name) {
super(name);
}
protected void setUp() {
}
public void testExecuteDML6(){
System.out.println("\ntestExecuteDML6()");
try{
/* Initial database sub-system */
ThSystem subSys = new ThSystem();
/* start the database sub-system */
subSys.start();
/* pass sub-system object to an agent so that it can access global objects */
ThAgent agent = new ThAgent(subSys);
/* Test Query Engine. Parse the DML file for DML syntax error */
ThPlan plan = ThParser.compileDML("c://an//cs297//xmldb//dml6.txt");
/* Execute statements in the DML file*/
int rc = agent.executeDMLPlan(plan);
/* If there turn code from executing the dml file is not 0, signal error*/
if (rc > 0){
fail("ExecuteDML Error!");
}
}catch (Exception e){
fail(e.toString());
}
}
public static void main(String args[]) {
junit.textui.TestRunner.run(ThTestExecuteDML.class);
}
}
Following is the input dml6.txt:
CREATE DATABASE DB1DB;
CREATE XMLDOC XML1DOC IN DB1DB;
LOAD "c://an//cs297//xmldb//test1.xml"
INTO XML1DOC;
printTree(XML1DOC);
/* add to the end of first element of /G[1], /G[2], ...
INSERT INTO XML1DOC PATH("/G/G[1]") VALUES("<L>392 Lily Ann Way,
San Jose CA 95111</L>",
"<L>(408)123-1234</L>");
INSERT INTO XML1DOC PATH("/G/G[2]") VALUES("<L>123 No Name St.,
San Jose CA 95112</L>",
"<L>(408)123-1234</L>"); COMMIT;
INSERT INTO XML1DOC PATH("/G/G[3]") VALUES("<L>234 Bernal,
San Jose CA 95012</L>");
INSERT INTO XML1DOC PATH("/G/G[4]") VALUES("<L>555 Bailey Road,
San Jose CA 94091</L>");
INSERT INTO XML1DOC PATH("/G/G[5]") VALUES("<L>1234 1st street,
San Francisco CA 95012</L>",
<L>(510)344-1010</L>");
INSERT INTO XML1DOC PATH("/G/G[6]") VALUES("<L>2234 2st street,
Santa Rosa CA 94323</L>",
<L>(808)463-1203</L>");
INSERT INTO XML1DOC PATH("/G/G[7]") VALUES("<L>3542 3st street,
Santa monica CA 95002</L>",
<L>(808)463-1203</L>");
/* comments
printTree(XML1DOC);
DELETE FROM XML1DOC WHERE PATH("/G/G[4]");
DELETE FROM XML1DOC WHERE PATH("/G/G/L[4]", "/G/G/L[3]");
printTree(XML1DOC);
UPDATE XML1DOC SET VALUE("<L>392 Pasilo dr., San Jose CA 95123</L>")
WHERE PATH("/G/G/L[2]");
printTree(XML1DOC);
ROLLBACK;
DROP XMLDOC XML1DOC;
DROP DATABASE DB1DB;
Following is the result from running the above testcase:
