Chris Pollett >
Students >
Priya
( Print
View )
[Bio]
Deliverable 2 - Implementation of K-means clustering algorithm
Goal
The goal of this deliverable is to implement K-means clustering.
Introduction
K-means clustering is one of the partitional clustering algorithms. The number of clusters to produce in the input data is to be specified prior to the execution. The algorithm assigns each of the input data to the cluster whose center is the nearest. The center of a cluster is the average of all points belonging to the cluster.
Implementation Details
The implementation was done in PHP. The number of clusters to be formed (K) and the data to be clustered is the input. The input data was represented as a point in Euclidean space.
K random points were selected as the centroids initially. The Euclidean distance to each of the centroids from the data points was calculated. The data point was assigned to the cluster to which the distance to the center was the least. The centroids were recalculated from the points assigned to the cluster. The points were reassigned to the clusters. This process was repeated until the new assignment was same as the previous assignment.
The output displayed the the input data, centroids of each cluster, the clusters. Figure 1 below shows a sample output.
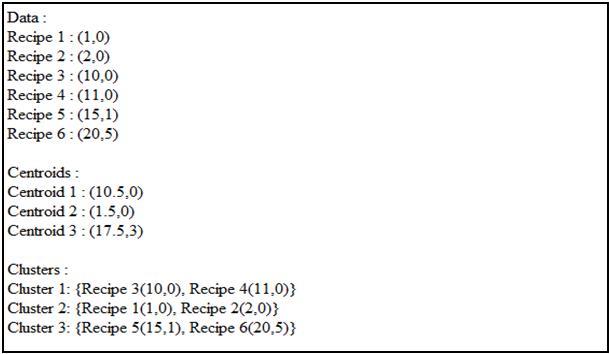
Figure 1: Sample output for K=3