This deliverable details the experimentation with different parameter-efficient fine-tuning (PEFT) methods applied to DistilBERT for legal case classification. The focus was on comparing fine-tuning techniques like LoRA, DoRA, and QLoRA, exploring various PEFT classes, and implementing explainable AI tools to enhance model interpretability.
Below is an image showing the difference between these fine-tuning techniques

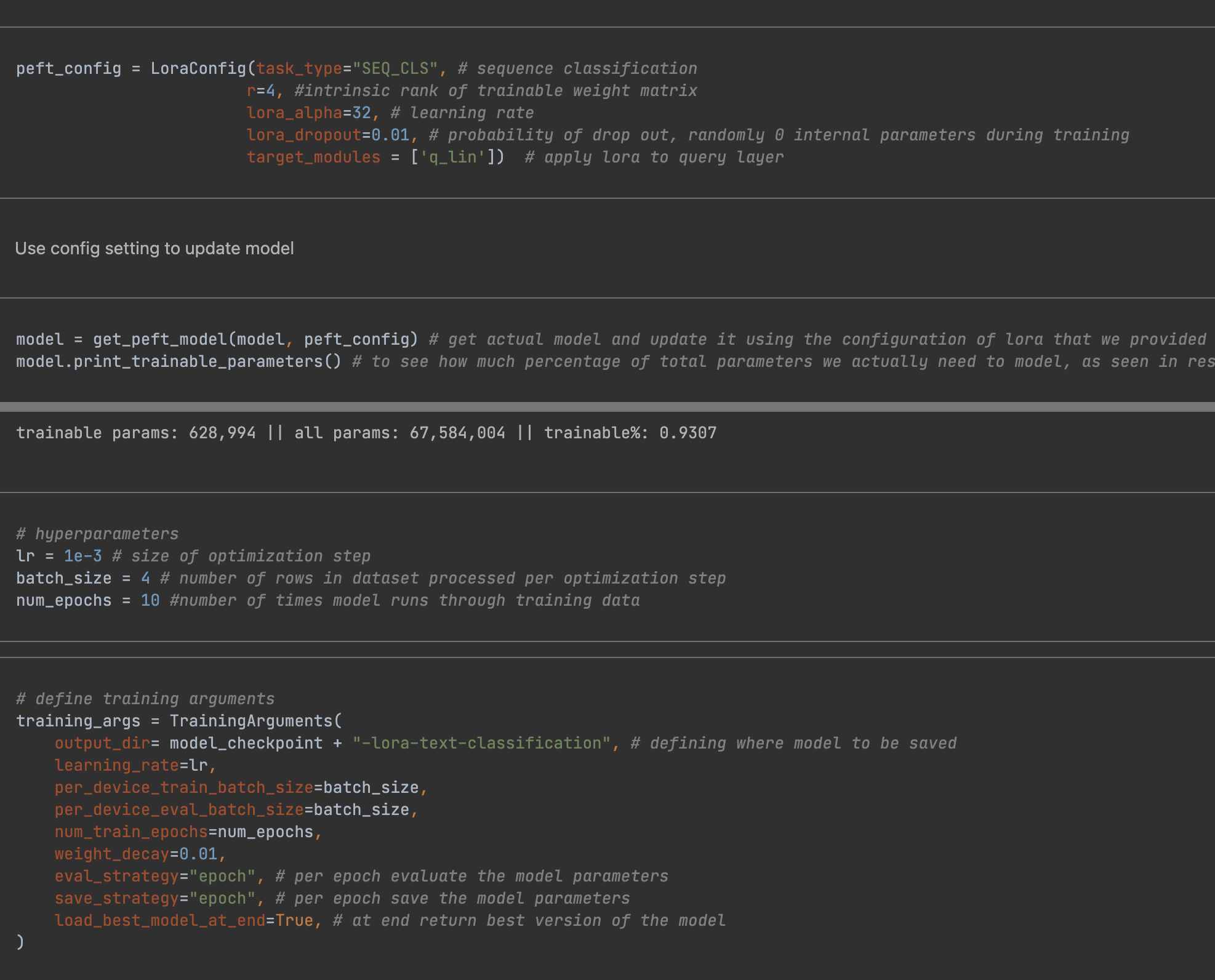
Using the PEFT type classes defined above, LoRA, DoRA, and QLoRA were applied across different model components. This experimentation allowed us to observe how each method affected performance, generalization, and computational efficiency.
Below is the image showing the accuracy result of 10 epoch using LoRA:
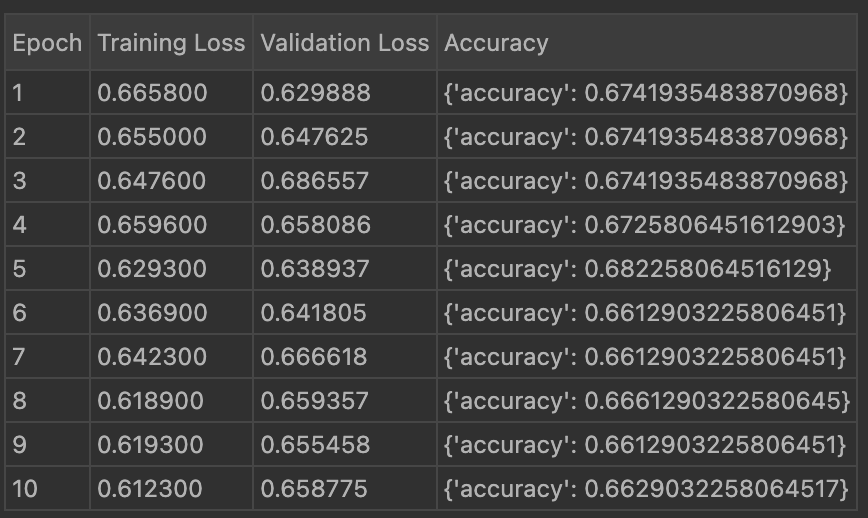
Below is the image showing the accuracy result of 10 epoch using DoRA:
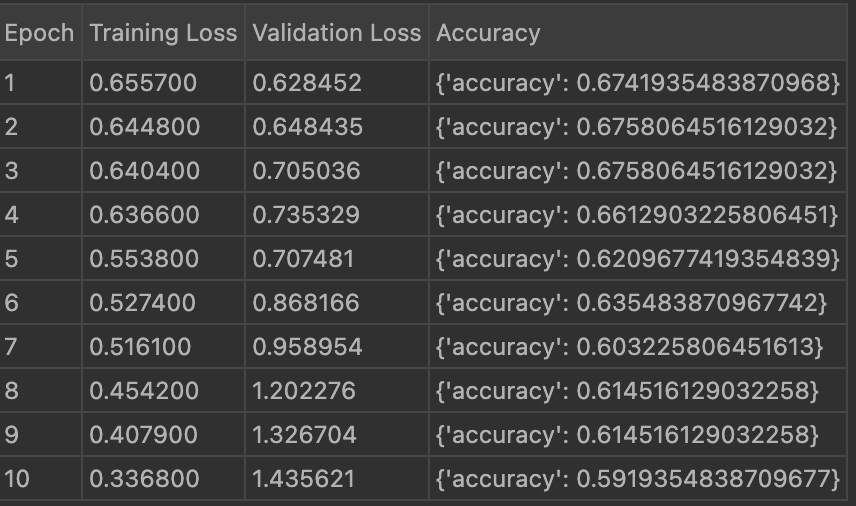
Below is the image showing the accuracy result of 10 epoch using QLoRA:
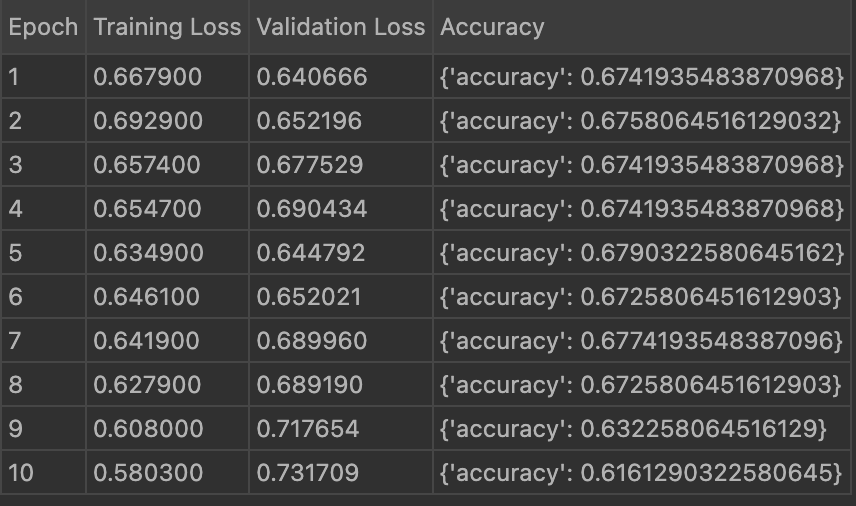
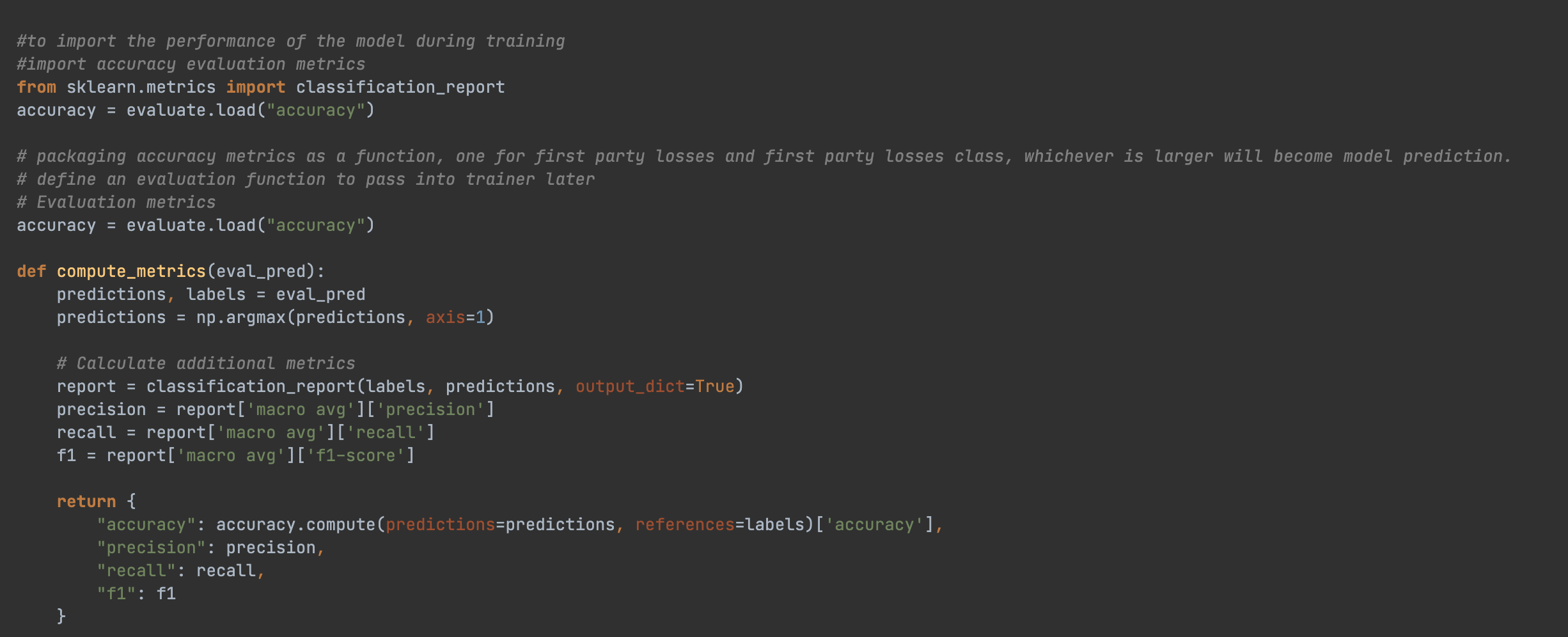
To evaluate model performance comprehensively, the following metrics were used:
These metrics together allowed for a more nuanced evaluation of LoRA, DoRA, and QLoRA, highlighting not only overall accuracy but also the reliability of each model's predictions in terms of specificity and coverage.
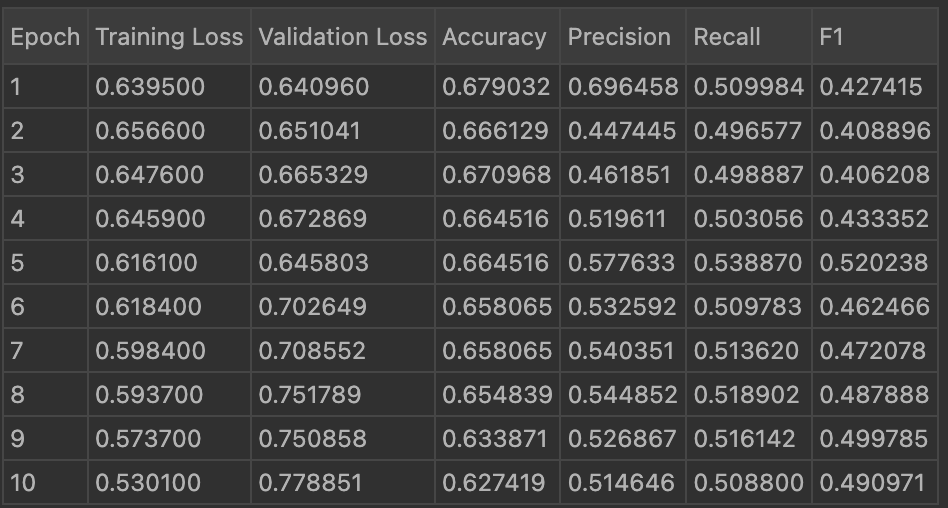
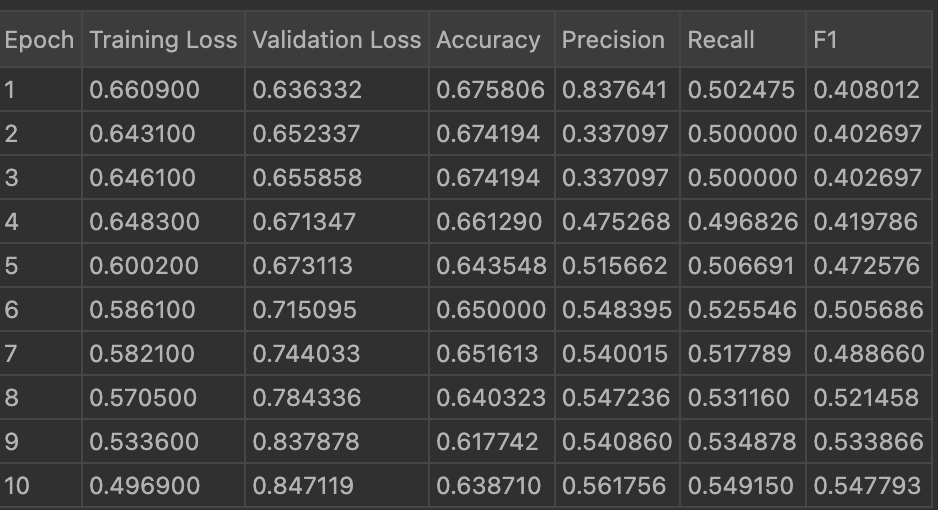
Below is the image showing the result of 10 epoch using LoRA with the updated evaluation metrics:
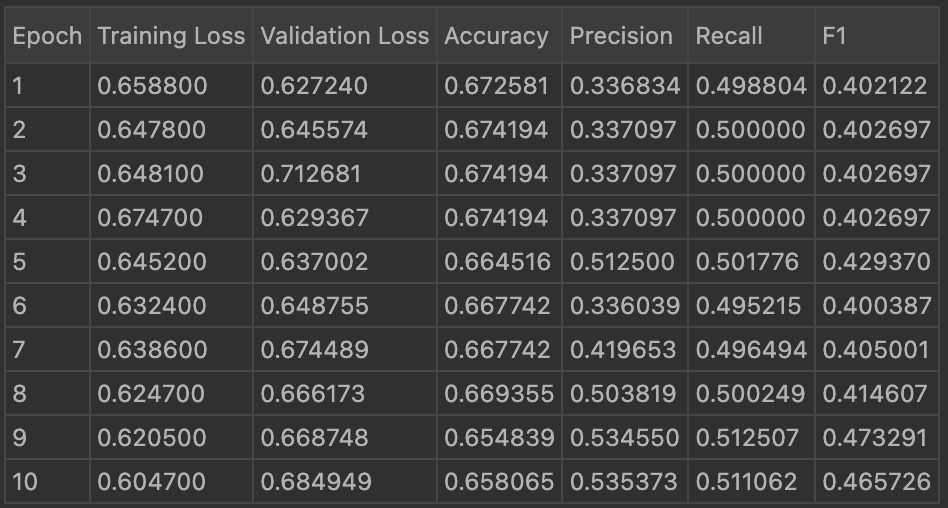
Below is the image showing the result of 10 epoch using DoRA with the updated evaluation metrics:
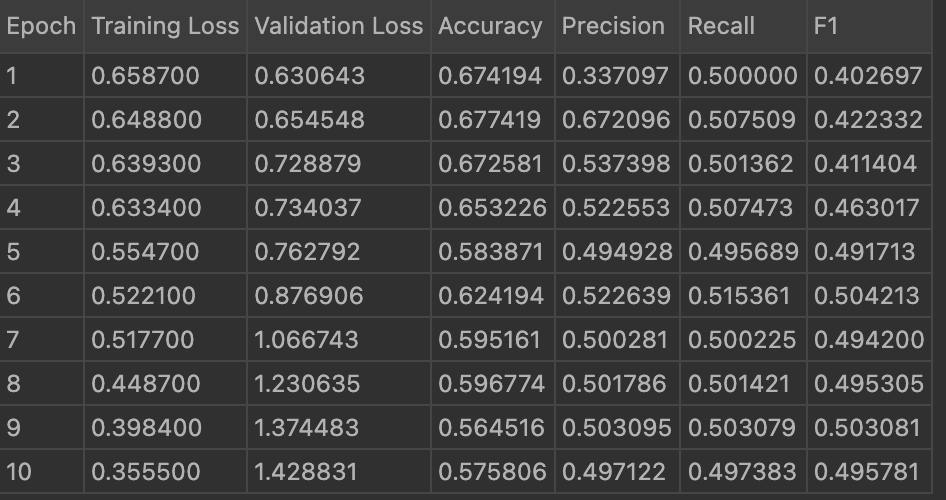
Below is the image showing the result of 10 epoch using QLoRA with the updated evaluation metrics:
Through detailed experimentation, LoRA emerged as the most effective PEFT technique for legal case prediction based on the following factors:
Based on these advantages, LoRA was selected as the primary technique for further fine-tuning and evaluation in legal case classification tasks.
In this step, I selected specific layers (0, 2, 4, and 6) in DistilBERT to apply LoRA transformations
using the layers_to_transform parameter. By focusing only on these layers, the model can
achieve a balance of targeted domain adaptation and computational efficiency, as not all layers undergo
fine-tuning.
layers_to_transform
By restricting LoRA transformations to specific layers:
In contrast, the default LoRA setting-without specifying layers_to_transform tends to
produce higher-quality embeddings as all layers undergo adaptation, resulting in a more robust model
output, especially for complex tasks like legal case prediction.
Below is the image showing the result of 10 epoch using LoRA with no extra layers of embeddings:
Below is the image showing the result of 10 epoch using LoRA with extra layers of embeddings:
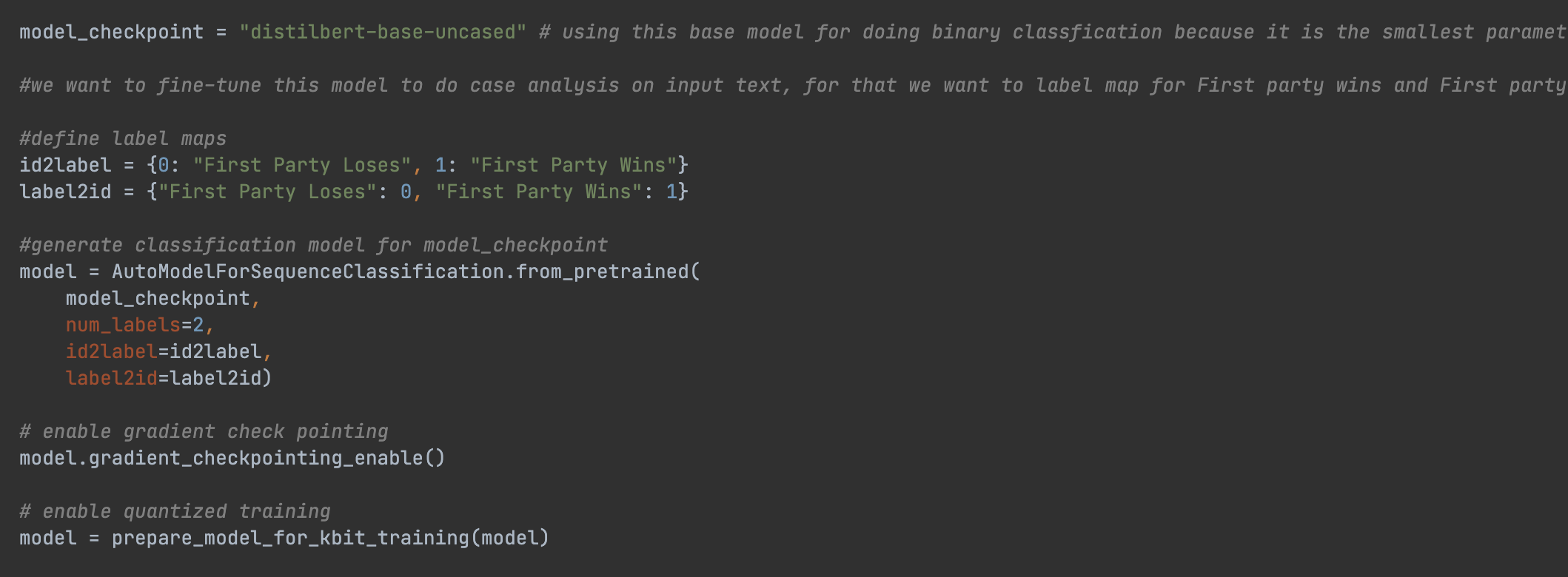
Parameter-efficient fine-tuning (PEFT) optimizes large language models (LLMs) for a variety of specific tasks. The following task types benefit from PEFT methodologies:
After researching all these task types, I found that sequence classification is the best suited for our use case, as it effectively aligns with our goals of accurately categorizing legal cases based on predefined classes.
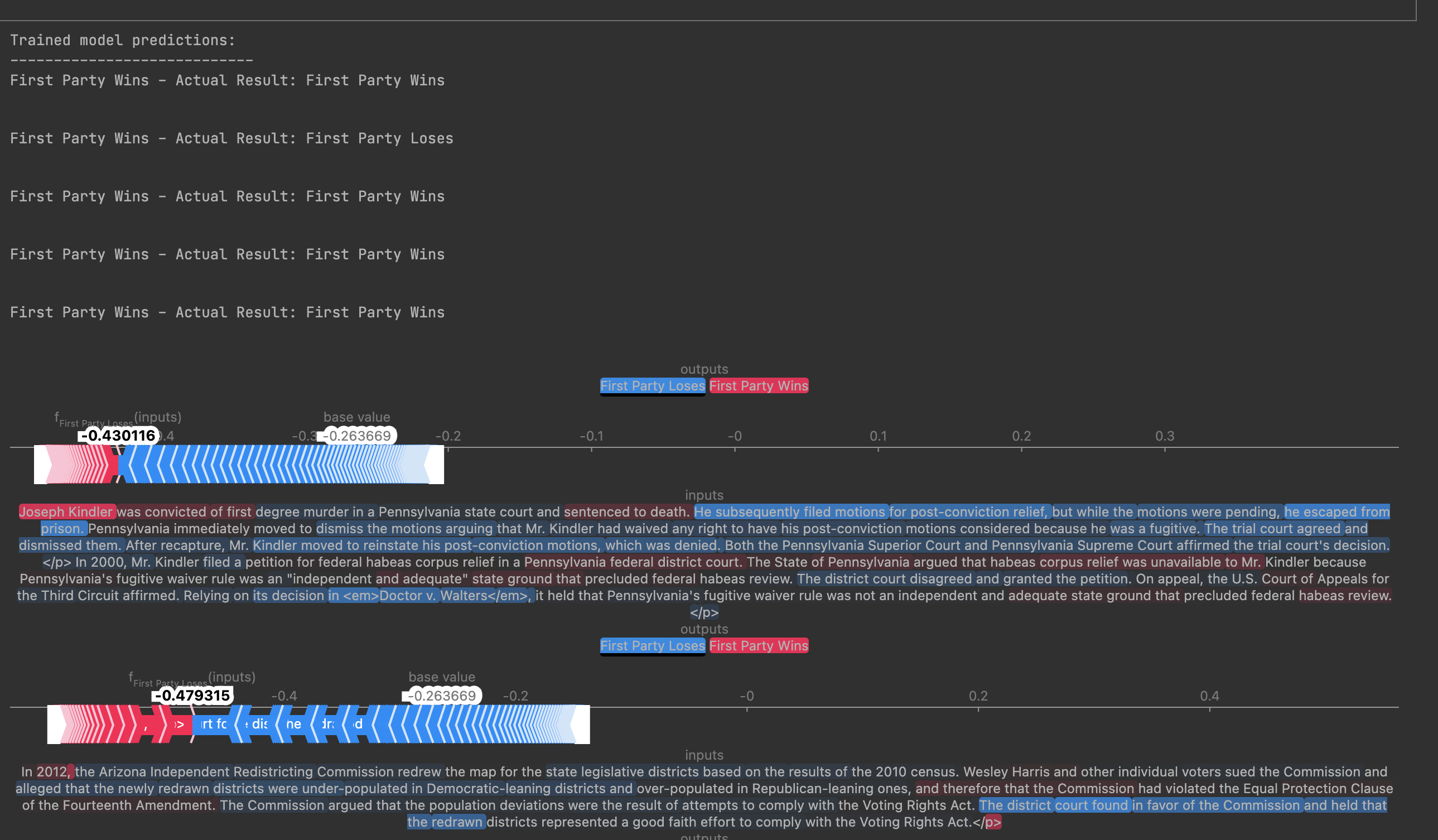
Why Explainable AI (XAI)? To interpret the model's decision-making process, I integrated XAI tools such as SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-Agnostic Explanations). These tools helped highlight which case details most influenced the model's verdict predictions, enhancing transparency and trustworthiness in legal contexts.
pip install shap
explainer = shap.Explainer(model)
shap_values = explainer(test_data)
shap.summary_plot(shap_values, test_data)
Below is the image showing the result of integrating ExAI using LoRA:
1. Code snippet for using multi-faceted evaluation metrics:
2. Code snippet for fine-tuning with LoRA:

3. Code snippet for fine-tuning with DoRA:

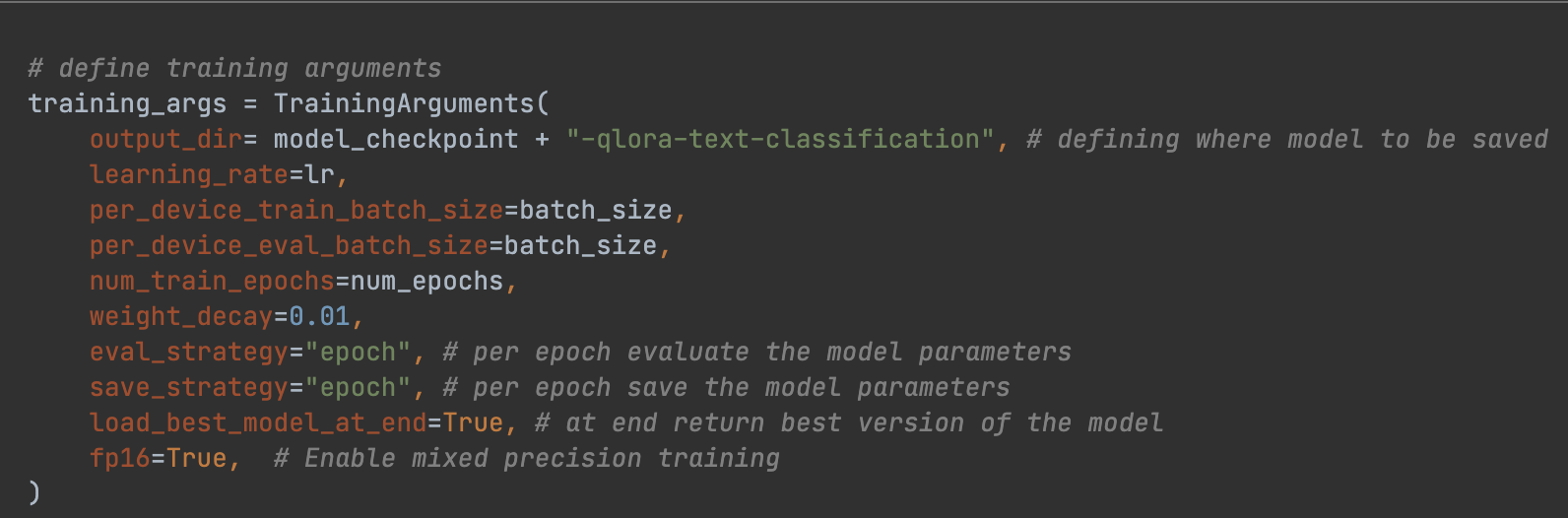
4. Code snippet for fine-tuning with QLoRA:
5. Code snippet for applying embeddings to multi layers with LoRA:

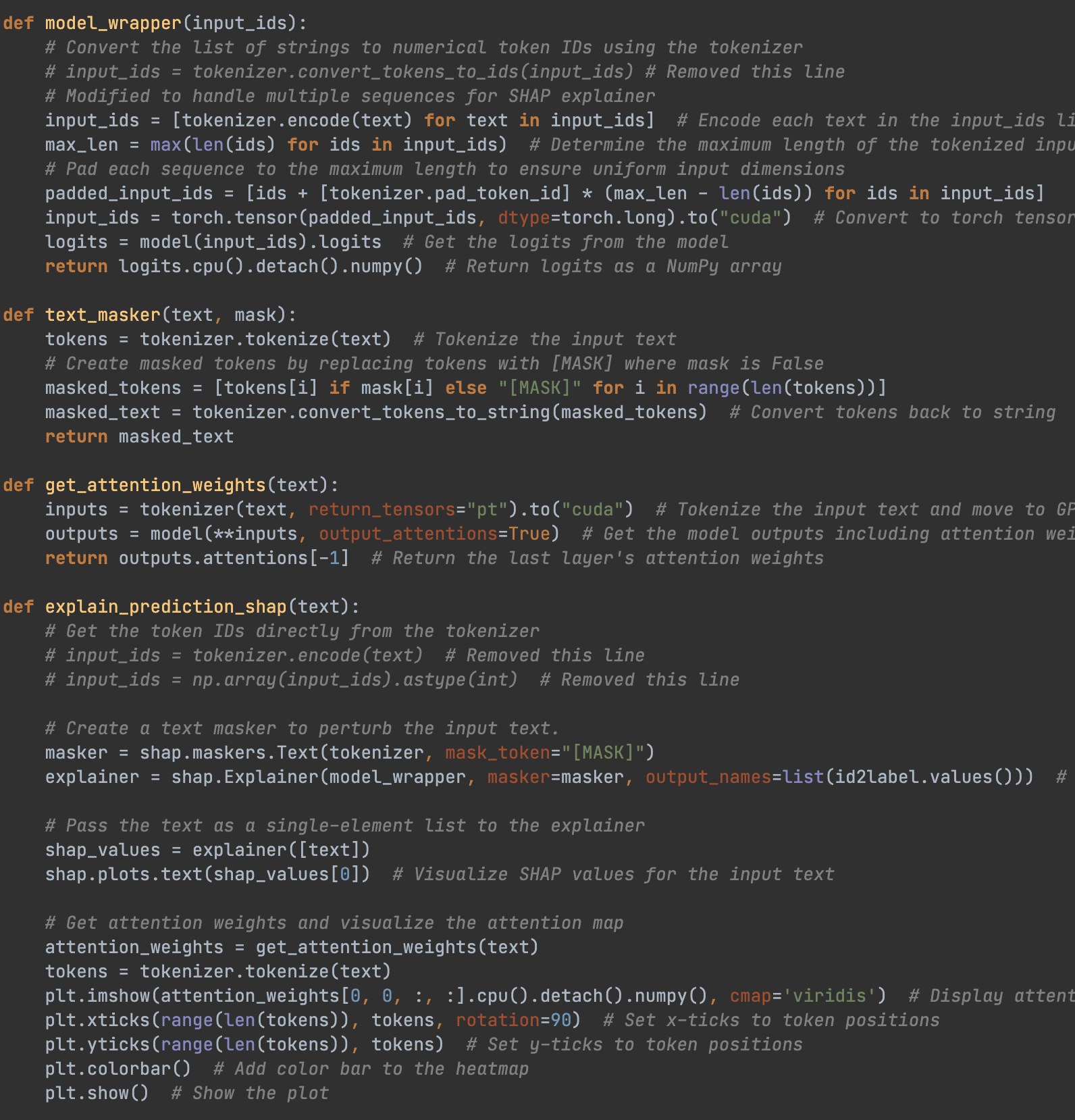
6. Code snippet for explainable AI integration:
After experimenting with each PEFT technique, LoRA achieved the highest accuracy, peaking at 68.4%, while DoRA and QLoRA provided computational efficiency gains without significant loss in accuracy. The explainable AI integration revealed that factual accuracy was a primary driver in the model's verdict predictions.
This experimentation reinforced the value of PEFT techniques in optimizing model performance for domain-specific tasks. Explainable AI provided essential insights into the model's reasoning process, proving invaluable for ensuring fair and transparent legal predictions.
Future work includes experimentation with other models to gain better accuracy.
Tutorial Reference: You can find the tutorials I followed for understanding the different types of fine-tuning techniques:
Comparing fine-tuning optimization techniques lora qlora dora and qdora
What is LoRA? Low-Rank Adaptation for finetuning LLMs EXPLAINED
DoRA LLM Fine-tuning explained : Improved LoRA
LoRA & QLoRA Fine-tuning Explained In-Depth
You can download the complete Jupyter notebook by clicking the link below:
LoRA vs DoRA vs QLoRA : with accuracy measures:
CS_297_AI_Powered_Legal_Decision_Support_System_Fine_tuning_with_LoRA.ipynb
CS_297_AI_Powered_Legal_Decision_Support_System_Fine_tuning_with_DoRA.ipynb
CS_297_AI_Powered_Legal_Decision_Support_System_Fine_tuning_with_QLoRA.ipynb
LoRA vs DoRA vs QLoRA : with multiple evaluation metrics:
LoRA with multi layer embedding:
CS_297_AI_Powered_Legal_Decision_Support_System_With_LoRA__More_embeddings.ipynb
LoRA with explainable AI:
CS_297_AI_Powered_Legal_Decision_Support_System_With_LoRA_Explainable_AI.ipynb
Presentation PDF available:
Different Fine-Tuning Models - PDF