Introduction
W3C: The World Wide Web Consortium (http://www.w3.org/)
W3C is a consortium of over 400 member organizations with a full-time staff of over 70 people. Member organizations contribute engineers who form teams that produce technical specifications. W3C is led by Tim Berners-Lee, the inventor of the WWW.
W3C Activities (http://www.w3.org/Consortium/Activities)
A W3C Activity typically consists of a working group, an interest group, and a coordination group. These groups produce technical reports, recommendations, and sample code.
The W3C activities are:
Architecture (http://www.w3.org/Architecture/)
Interaction (http://www.w3.org/Interaction/)
Technology and Society (http://www.w3.org/TandS/)
Web Accessibility Initiative (http://www.w3.org/WAI/)
Quality Assurance (http://www.w3.org/QA/Activity)
W3C Technical Reports (http://www.w3.org/TR/)
The basic work product of a W3C group is called a technical report. The lifecycle of a technical report passes through four maturity levels:
Working Draft ->
Candidate Recommendation ->
Proposed Recommendation ->
Recommended
Architecture of the Web: Agents and Resources
While browsing w3c.org I discovered an interesting document called Architecture of the World Wide Web (http://www.w3.org/TR/webarch/), which gives an abstract overview of the architecture of the web itself[1]. Here's an excerpt from the abstract:
The World Wide Web is a network-spanning information space of
resources interconnected by links. This information space is the basis of, and
is shared by, a number of information systems. Within each of these systems,
agents (people and software) retrieve, create, display, analyze, and reason
about resources.
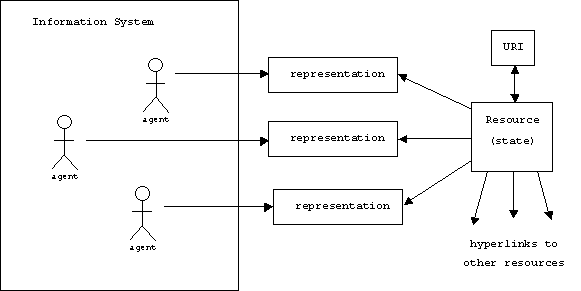
Web architecture includes the definition of the information space in terms of identification and representation of its contents, and of the protocols that support the interaction of agents in an information system making use of the space. Web architecture is influenced by social requirements and software engineering principles, leading to design choices that constrain the behavior of systems using the Web in order to achieve desired properties of the shared information space: efficiency, scalability, and the potential for indefinite growth across languages, cultures, and media. This document reflects the three bases of Web architecture: identification, interaction, and representation.
So basically, the web is a network of hyperlinked nodes called resources. Resources are consumed by human and software agents. Software agents include browsers, proxies, servers, spiders, and multi-media players.
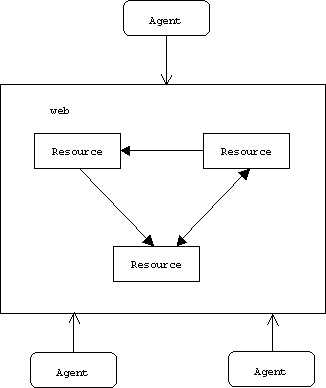
Each resource is identified by one or more unique names called a Uniform Resource Identifier or URI (URIs are the new URLs). Resources not only include documents (web pages and other types of files), but also web applications and web services.
A web application is any application with a web interface. Web applications are typically consumed by human agents. Priceline.com is an example of a web application. Human agents input desired departure date, destination, and price. Internally, the application searches several airlines for a match. The result of the search is then returned to the user.
A web service is a standalone component used by several
web applications. Web services are typically consumed by software agents and
web applications. Air
Resources can be stateful. For example, the state of a stock ticker web service might include the current DOW Jones average. Applications that use the stock ticker might choose to represent this information in different formats.
Enter XML
Originally, the web was oriented toward human agents. Web pages tended to be HTML documents containing a mixture of textual data, hyperlinks, and layout (paragraph breaks, lists, fonts, etc.) This made life difficult for software agents, which were forced to first separate the data from the layout, and then to guess at the structure of the data using highly customized parsing techniques.
The goal of XML is to first separate layout from data. XML documents only contain data. Secondly, XML allows authors to specify the structure of their data using markup tags similar to the tags used in HTML documents to specify layout. This means a software agent can infer the logical structure of an XML document using standard, widely available parsers.
Meta-XML
An XML document might contain information about a musical score, a chemical formula, a business contract, or additional information about the contents of other XML documents. For example, an XML document might describe the syntax or semantics of other XML documents. It might describe how a collection of documents are related to one another, or how a collection of documents should be displayed to human agents. We can think of these as meta-XML documents. Of course meta-XML documents are also XML documents, hence meta-meta-XML documents are possible. Thus, in addition to hyperlinks, an XML-based web can also have layers.
The XML Platform
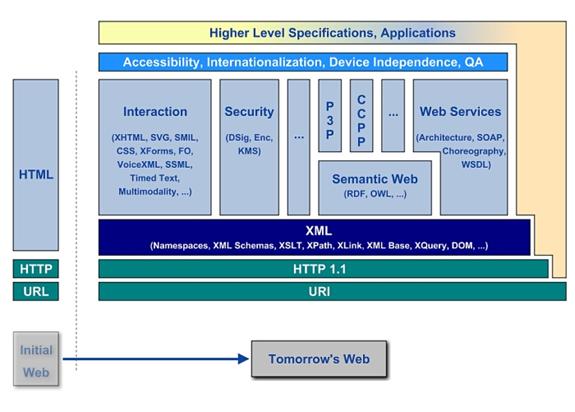
Ultimately, we can view the XML-based web as an open distributed platform for applications.
The following graphic is taken from the W3C site and summarizes this vision:
Example
The Marketing Department at Acme Inc. represents all internal memos in a local XML language called MemoXML. Here's a sample file called memo35.xml:
<?xml version = "1.0"?>
<memo>
<date> June 21, 2003
</date>
<from> Mr. Jones </from>
<to> all </to>
<re> Summer </re>
<body> Solstice occurs at 5:21 PM
today. </body>
</memo>
This may seem like a step backward. Wouldn't it be easier to read this memo if it was nicely formatted:
June
21, 2003
From: Mr. Jones
To: all
re: Summer
Solstice occurs at 5:21 PM today.
Three points need to be made.
First, the XML form is human readable.
Second, the XML form is also machine readable. In other words, a computer program (i.e., a software agent) can easily pick out the parts of the XML form, but not the formatted form. For example, it would be easy to write a search program that searches through a repository of memos for all of those written by Mr. Jones, or all of those written on a particular date.
This brings us to the third point: it's easy to write a display program that translates the XML form into the formatted form. The advantage of this is that if a change in company policy dictates a new format for all company memos, say a format that included a company logo at the top of the memo and that insisted that the "from" line follow the "to" and "re" lines, then it would be an easy matter to modify the display program so that all memos—past and future—could be displayed in the new format. As another example, company policy may require that all memos be available in text, PDF, and HTML format. Rather than require employees to make three copies of each memo they write, all three formats could be automatically generated from a single XML version of the memo.
Document Exchange between Systems
We can take the idea of the display program one step further. Suppose the XML memo structure above is used by department A, while department B uses a slightly different structure. Because we have so much freedom defining tags and structure, problems like this arise frequently. What happens when Mr. Jones (who works in department A) needs to send a memo to someone in department B. Jones can still write his memo using the tags and structure of department A memos, because it's an easy matter to provide a translator program that translates memos written in form A into memos written in form B:
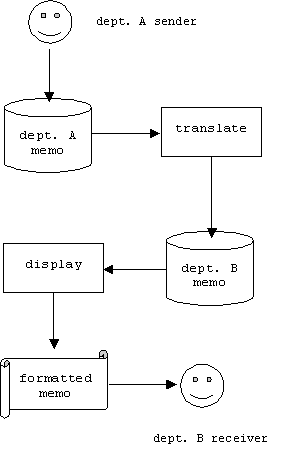
Document Structure
An XML document consists of a declaration followed by a single element called the root:
<?xml version = "1.0"?>
<ROOT>
CONTENT
</ROOT>
Of course the content of the root may contain other elements.
Usually an XML document will have an .xml extension:
memo35.xml
We can view the structure of an XML document as a tree:
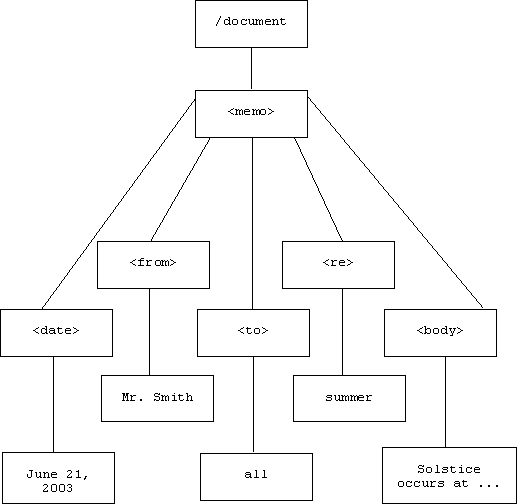
Besides the top-most document node, there are two types of nodes in this tree: nodes that correspond to document elements (labeled by markup tags), and nodes that correspond to document text. Text nodes are always leafs, while parent nodes are always elements.
Here's how IE displays memo35.xml:
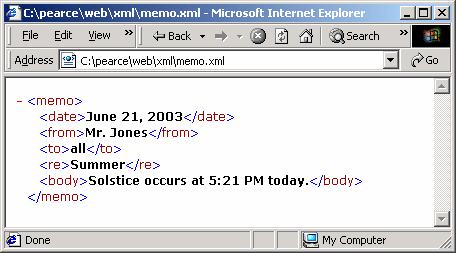
In addition to element and text nodes, an XML document may also contain comment nodes and PIs or processing instructions (which we will rarely use):
<!-- this is an XML comment -->
<?target value?>
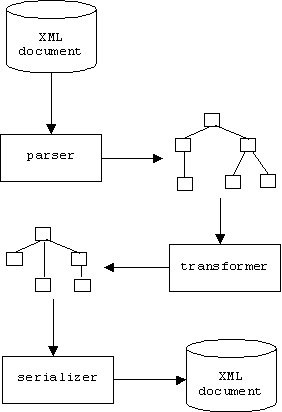
XML Document Parsers
An XML parser is a program that constructs a tree like the one shown above from an XML input document. This tree will be the "official" input to other programs that process XML documents. Of course if the document is not well formed, then the parser throws an exception, instead:
There are many freely available XML parsers including Xalan and Saxon.