2. Public XML Languages
XHTML
The specification for XHTML can be found at:
http://www.w3.org/TR/2002/REC-xhtml1-20020801/
XHTML is an XML version of HTML.
Like HTML documents, XHTML documents have an .html or .htm suffix. The prelude contains an XML declaration and a DTD declaration. The <html> root element of an XHTML document must contain the XHTML namespace declaration:
<?xml version="1.0"?>
<!DOCTYPE html
PUBLIC "-//W3C//DTD XHTML 1.0
Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns = "http://www.w3.org/1999/xhtml">
<head><title> This is my
first XHTML document </title><head>
<body>
<p> This is my first XHTML
document </p>
</body>
</html>
XHTML elements are the same as HTML elements: tables, forms, images, text, scripts, and of course, links. (Of course these elements belong to the XHTML namespace.)
However, like all XML documents, an XHTML document must be well formed. This means XHTML documents have restrictions that HTML documents don't need to worry about. Here's a list of these restrictions:
docs must be well-formed
element and attribute names must be lower case
attribute values must be quoted
non-empty elements must have end tags
start tag of an empty element must end with />
MathML
MathML is an XML language for marking up mathematical expressions. The specification for mathML can be found at:
http://www.w3c.org/TR/2003/REC-MathML2-20031021/
A MathML expression is an element of the form:
<math xmlns="http://www.w3.org/1998/Math/MathML">
<!-- expression components go here
-->
</math>
MathML has three types of elements: presentation, content, and interface. Presentation elements allow us to represent mathematical expressions symbolically, while content elements allow us to represent expressions logically. Most processors don't fully support content elements, so we will concentrate on presentation elements.
The primitive MathML expressions are numbers <mn>, identifiers <mi>, and operator symbols <mo>.
New MathML expressions can be built from existing expressions by sequencing and nesting. For example, the expression "x + 22 = 100" is simply a sequence of primitive expressions:
<math xmlns="http://www.w3.org/1998/Math/MathML">
<mi>x</mi>
<mo>+</mo>
<mn>22</mn>
<mo>=</mo>
<mn>100</mn>
</math>
More complex MathML expressions include roots, fractions, superscripted expressions, subscripted expressions, under-scripted expressions, matrices, and expressions bracketed by parentheses.
Here's a markup for the Pythagorean theorem:
<math xmlns="http://www.w3.org/1998/Math/MathML">
<mi>c</mi>
<mo>=</mo>
<msqrt>
<msup>
<mi>x</mi>
<mn>2</mn>
</msup>
<mo>+</mo>
<msup>
<mi>y</mi>
<mn>2</mn>
</msup>
</msqrt>
</math>
If we attempt to embed a MathML expression in an ordinary HTML document, the browser simply ignores the MathML tags it doesn't understand. In other words, it displays the text:
c = x2 + y2
On the other hand, if we embed a MathML expression in an XHTML document, then a browser equipped with the right plugin (for example, MathPlayer from:
http://www.dessci.com/en/products/mathplayer/)
or a browser with a native ability to understand MathML such as Amaya from:
can properly display both the XHTML elements and the MathML elements.
Here's an example of embedding MathML in XHTML:
<html xmlns = "http://www.w3.org/1999/xhtml">
<!-- content goes here -->
<head><title> My First
XHTML document </title></head>
<body>
<p> Here's the Pythagorean
theorem.</p>
<p>
<math
xmlns="http://www.w3.org/1998/Math/MathML">
<mi>c</mi>
<mo>=</mo>
<msqrt>
<msup>
<mi>x</mi>
<mn>2</mn>
</msup>
<mo>+</mo>
<msup>
<mi>y</mi>
<mn>2</mn>
</msup>
</msqrt>
</math>
</p>
</body>
</html>
Here is a screen shot of Amaya:
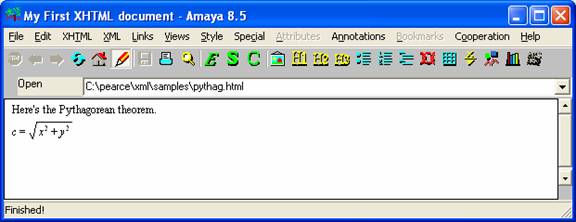
SVG
SVG is an XML markup language for standard vector graphics. The specification for SVG can be found at:
http://www.w3c.org/TR/2003/REC-SVG11-20030114/
Of course we can embed SVG elements in XHTML documents. Enabled browsers can then display the graphical elements. Here are a few examples of SVG elements:
Rectangles
<svg xmlns="http://www.w3.org/2000/svg"
version="1.0" height="74px">
<rect stroke="black"
fill="none" y="0px" x="1px"
width="173px"
height="74px"/>
</svg>
Ellipse
<svg xmlns="http://www.w3.org/2000/svg"
version="1.0">
<ellipse stroke="black"
fill="none" cy="45px" cx="63px"
rx="63px"
ry="45px"/>
</svg>
Two Lines
<svg xmlns="http://www.w3.org/2000/svg"
version="1.0">
<line stroke="black"
y1="15px" x1="12px" x2="168px"/>
<line stroke="black"
y1="15px" x1="205px" x2="6px"/>
</svg>
Polylines
<svg xmlns="http://www.w3.org/2000/svg"
version="1.0">
<polyline stroke="black"
fill="none" points="0,15 38,0 89,14 133,0
241,15 129,15 174,0 174,0
174,0"
transform="translate(34,0)"/>
</svg>
Curves
<svg xmlns="http://www.w3.org/2000/svg"
version="1.0">
<path stroke="black"
fill="none" d="M 26,1 C 25,3 72,14 88,15 C
114,16 174,0 201,0 C 224,0 277,13
301,15 C 301,15 301,15 301,15"/>
</svg>
Groups
<svg xmlns="http://www.w3.org/2000/svg"
version="1.0" height="69px">
<g>
<rect stroke="black"
fill="none" y="0px" x="8px"
width="120px"
height="57px"/>
<circle stroke="black"
fill="none" cy="56px"
cx="83px"r="12px"/>
</g>
</svg>
Screen Shot
Here's a screen shot of Amaya displaying an XHTML document containing the above SVG elements:
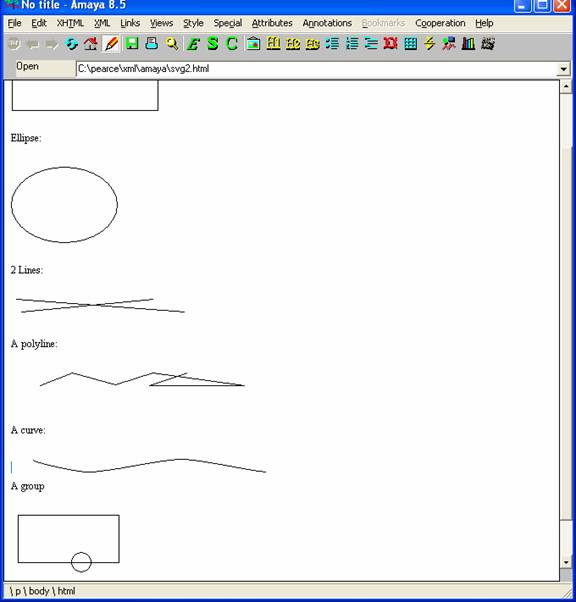
Syndication with XML
Syndication is a common XML application, and RSS is a public XML syndication language.
News agencies such as Reuters, Associated Press (AP), and United Press International (UPI) provide RSS files on their web sites called feeds or channels. An RSS feed is simply a list of news items. Each item might have a title, a description or teaser, and a link to the actual article:
<item>
<title>Earth
Invaded</title>
<link>http://news.example.com/2004/12/17/invasion</link>
<description>The earth was
attacked by an invasion fleet
from halfway across the galaxy;
luckily, a fatal
miscalculation of scale resulted in the
entire armada
being eaten by a small
dog.</description>
</item>
A
web portal such as Yahoo contains a box titled Today's Top Stories. In this box
we see the titles, descriptions, and links for late-breaking stories from
Reuters, AP, and UPI. The contents of this box are generated by an aggregator.
Of
course the aggregator controls how items from the various feeds are displayed,
while the news agencies control the actual content of their stories. Users can
get stories from many different sources without having to actually visit many
different sites. Users can even customize aggregators to only display stories
that are on topics that are of interest: foreign affairs, economy, and Pamela
Anderson, for example.
As
another example, Acme Inc. provides RSS feeds for product announcements and for
job openings. An employment agency might aggregate job opening feeds from Acme
and several other employers, while a retail outlet for bear traps might
aggregate product announcement feeds from Acme and several other bear trap
providers.
A
weblog (blog) is a public online diary. A blog author might provide an RSS feed
that lists juicy excerpts. An aggregator publishes these feeds so interested
readers can follow along.
There
are several versions of RSS. RSS 0.9x stands for Really Simple Syndication. It
was developed by Netscape and is now in the hands of UserLand Software (http://rss.userland.com/).
RSS
1.0 is maintained by an ad-hoc group of interested people (http://web.resource.org/rss/1.0/).
It incorporates RDF (Resource Description Framework) to markup its meta data.
It's a more complicated language that many regard as distinct from RSS 0.9x. In
fact, RSS 1.0 stands for RDF Site Summary.
My
information about RSS comes from a good online tutorial located at http://www.mnot.net/rss/tutorial/.
Here's
a simple example of an RSS 0.91 feed:
<?xml
version="1.0"?>
<rss version="0.91">
<channel>
<title>Example
Channel</title>
<link>http://example.com/</link>
<description>My example
channel</description>
<item>
<title>News for September
the Second</title>
<link>http://example.com/2002/09/01</link>
<description>other things
happened today</description>
</item>
<item>
<title>News for September
the First</title>
<link>http://example.com/2002/09/02</link>
</item>
</channel>
</rss>
Configuration
Control with XML
Parsing XML documents in a Java or C++ program is pretty easy to do. For this reason XML can be used to parameterize how a program should configure itself when it starts up. An XML configuration document might describe user preferences and GUI layout.
Ant (http://ant.apache.org/) is a build tool from the Apache Foundation that replaces the old make utility from Unix. Recall that make searched for a makefile that described dependencies between the different files of a program. It automatically recompiled all files that changed since the last build. It also recompiled all of the files that depended on these files. Finally, it linked together all indicated object files into an executable. Ant performs a similar function, except the makefiles are XML documents. Here's an example:
<project name="MyProject" default="dist"
basedir=".">
<description>
simple example build file
</description>
<!-- set global properties for this
build -->
<property name="src"
location="src"/>
<property name="build"
location="build"/>
<property name="dist" location="dist"/>
<target name="init">
<!-- Create the time stamp -->
<tstamp/>
<!-- Create the build directory
structure used by compile -->
<mkdir
dir="${build}"/>
</target>
<target name="compile"
depends="init"
description="compile the
source " >
<!-- Compile the java code from
${src} into ${build} -->
<javac srcdir="${src}"
destdir="${build}"/>
</target>
<target name="dist"
depends="compile"
description="generate the
distribution" >
<!-- Create the distribution
directory -->
<mkdir
dir="${dist}/lib"/>
<!-- Put everything in ${build}
into the MyProject-${DSTAMP}.jar file -->
<jar
jarfile="${dist}/lib/MyProject-${DSTAMP}.jar"
basedir="${build}"/>
</target>
<target name="clean"
description="clean up"
>
<!-- Delete the ${build} and
${dist} directory trees -->
<delete
dir="${build}"/>
<delete
dir="${dist}"/>
</target>
</project>
Web Services
Open Distributed Processing (ISO 10746)
ODP is a reference architecture for systems constructed from distributed, heterogeneous components. Components communicate by passing messages. A component has one or more unique identifiers. A component is either a service requestor, a service provider, or both. A service provider component implements one or more interfaces. Associations between interfaces and the identifiers of implementing components are maintained by registries. A registry is like the yellow pages section of a phone book. Using a registry, a client component can dynamically locate and interact with the provider components it needs. This is called discovery. (See http://www.joaquin.net/ODP/).
UML Notation
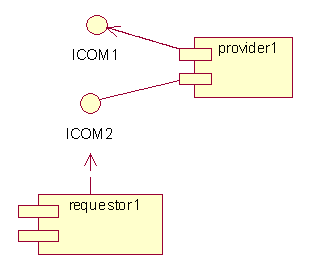
ODP Implementations
There are several notable implementations of the ODP architecture. The best known is the Object Management Group's (http://www.omg.org/) Object Management Architecture or OMA. The OMA reference architecture envisions layers of applications, services, and facilities, all written in different Object-Oriented languages. Remote method invocation is provided by an object request broker or ORB. (In fact OMA better known as CORBA-- Common Object Request Broker Architecture).
Microsoft's COM (Component Object Model) architecture implemented ODP for programs running on the same Windows platform. This enabled the popular Object Linking and Embedding (OLE) technology. The DCOM extension allowed OLE to reach across networks.
Java RMI implemented ODP for cooperating Java programs.
The Web Services Architecture (WSA) is the latest implementation.
Web Services Architecture (WSA)
WSA is a reference architecture, similar to ODP and OMA. The details can be found at:
http://www.w3.org/2002/ws/arch/
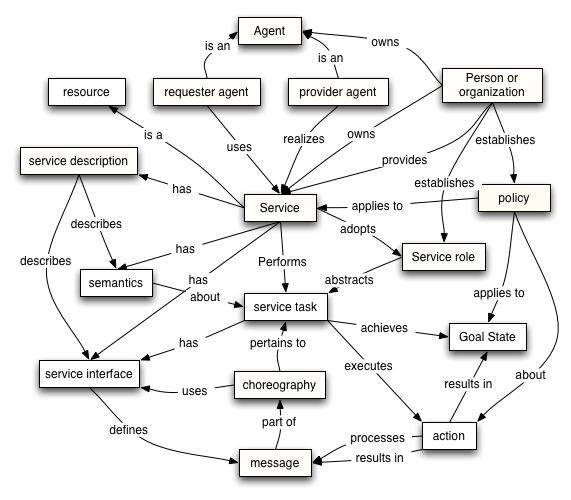
WSA Teminology
Web Service = service
interface
WSD = web services
descriptor = interface description (supports discovery)
Agent = component =
service implementor (provider agent and/or requestor agent)
Applications
The original
motivation envisioned new applications built out of distributed components, but
now the tendency is to make existing applications partially available on the
web by incorporating agents, thus creating a web-enabled application. The
ultimate goal of web-enabling an application is low-cost integration of
existing applications.
WSA Models
Message Model
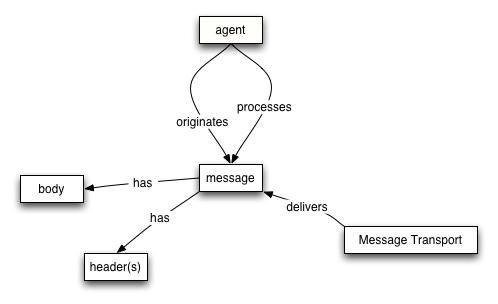
Services Model
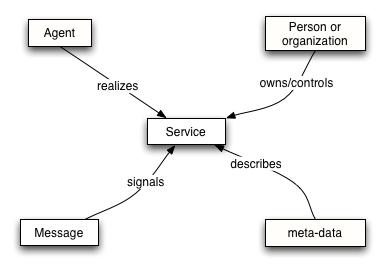
Resource Model
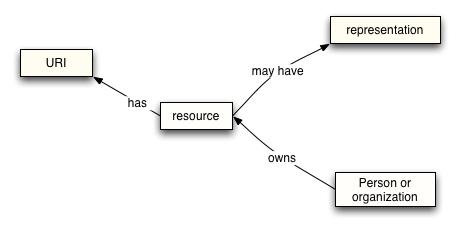
Policies Model
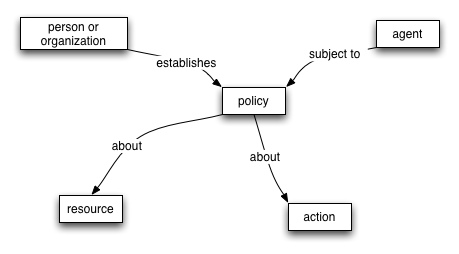
Services Model (Elaboration)
W3C Standards
SOAP = Simple Object Access Protocol (Messages)
WSDL = Web Services Description Language
OASIS Standards (see http://www.oasis-open.org/home/)
UDDI = Universal Description, Discover, and Integration
Implementations
.NET
J2EE
J2EE Support
Apache
IBM
Eclipse
BEA
Sun
See http://java.sun.com/xml/docs.html
Soap
References
http://www.w3c.org/TR/2003/REC-soap12-part0-20030624/
Format
<?xml version='1.0'
?>
<env:Envelope
xmlns:env="http://www.w3.org/2003/05/soap-envelope">
<env:Header>
<!-- Headers are optional.
Any XML can go in a header.
Headers contain header blocks.
Header blocks describe context information.
-->
</env:Header>
<env:Body>
<!-- any XML goes here -->
</env:Body>
<env:Envelope>
Example
<?xml version='1.0'
?>
<env:Envelope
xmlns:env="http://www.w3.org/2003/05/soap-envelope"
xmlns =
"http://www.demo.org/memo">
<env:Header>
<from>Dr. Morris
Fishbine</from>
<to>HR</to>
<date>2001-11-29</date>
</env:Header>
<env:Body>
<employee>
<name>Joe
Smith</name>
<ssn>555-55-1234</ssn>
<dept>R&D</dept>
</employee>
</env:Body>
</env:Envelope>
Conversational Message Exchanges
Although SOAP
stands for "Simple Object Access Protocol" implying that it's
original application was remote method invocation, SOAP can be used to
represent ordinary messages. In this case the sender agent simply encapsulates
a message in the body of a SOAP envelope and sends it to a receiver agent. The
message itself may be transported using RPC, email, or HTTP. In the simplest
model sessions betwenn a sender and receiver are stateless, but more complicated
patterns can be implemented.
For example:
<?xml version='1.0'
?>
<env:Envelope
xmlns:env="http://www.w3.org/2003/05/soap-envelope"
xmlns =
"http://www.demo.org/memo">
<env:Header>
<from>Dr. Morris
Fishbine</from>
<to>HR</to>
<date>2001-11-29</date>
</env:Header>
<env:Body>
<employee>
<name>Joe
Smith</name>
<ssn>555-55-1234</ssn>
<dept>R&D</dept>
</employee>
</env:Body>
</env:Envelope>
Remote Procedure Call
<?xml version='1.0'
?>
<env:Envelope
xmlns:env="http://www.w3.org/2003/05/soap-envelope"
xmlns =
"http://www.demo.org/memo">
<env:Header>
<from>Dr. Morris
Fishbine</from>
<to>HR</to>
<date>2001-11-29</date>
</env:Header>
<env:Body>
<method>dot-product</method>
<vector xc = "3" yc
= "4" zc = "2"/>
<vector xc = "1" yc
= "8" zc = "-7.6"/>
</method>
</env:Body>
</env:Envelope>
Error Handling
<?xml version='1.0' ?>
<env:Envelope xmlns:env="http://www.w3.org/2003/05/soap-envelope"
xmlns:rpc='http://www.w3.org/2003/05/soap-rpc'>
<env:Body>
<env:Fault>
<env:Code>
<env:Value>env:Sender</env:Value>
<env:Subcode>
<env:Value>rpc:BadArguments</env:Value>
</env:Subcode>
</env:Code>
<env:Reason>
<env:Text
xml:lang="en-US">Processing error</env:Text>
<env:Text
xml:lang="cs">Chyba zpracování</env:Text>
</env:Reason>
<env:Detail>
<e:myFaultDetails>
<message>vectors must have
same length</message>
<errorcode>999</e:errorcode>
</myFaultDetails>
</env:Detail>
</env:Fault>
</env:Body>
</env:Envelope>
Object Serialization
XML can be used
as a language-independent object persistence mechanism:
<object-repository>
<object class = "Person"
OID = "ID505">
<field name = "name"
type = "string">Howard Johnson</field>
<field name = "address"
type = "Address" ref = "ID509"/>
</object>
<object class = "Address"
OID = "ID505">
<field name = "bldg"
type = "int">123</field>
<field name = "street"
type = "string">Sesame St</field>
<field name = "city"
type = "string">NYC</field>
<field name = "state"
type = "string">NY</field>
<field name = "zip"
type = "string">10010</field>
</object>
<!-- etc. -->
</object-repository>
Various schemes
can be found including SOAP, XLINK, and RDF/OWL.
The xml.org Resigstry
See http://www.xml.org/xml/registry.jsp for DTDs and Schemas for other domain-specific languages.
XML Meta-Languages
Of course there are standard XML languages for describing XML languages and documents. These include schemas, style sheets, link bases, and ontologies and will be discussed elsewhere.