The Document Object Model (DOM)
Programmers often want to parse XML documents into tree-like data structures. Of course these data structures will be slightly different depending on the language of the parser: Java, C++, etc. To bring some order to the potential chaos the WWW Consortium introduced DOM, which specifies the structure of these trees. The DOM model can also be applied to HTML documents.
Here's the interesting part: when an HTML document is downloaded to a browser, it is automatically parsed into a DOM tree. This tree can be accessed by any scripts contained in the document. Thus, a script can access (and modify) itself!
The root of the tree is an implicit object called window.
The window object has methods for displaying dialog boxes and opening new windows. See win.html for a demonstration.
The window object also has two interesting fields:
window.document
window.navigator
The navigator field is an object that represents the browser. This allows a script to access browser properties. See nav.html for a demonstration.
The document field represents the HTML document itself. It contains subfields representing the elements (tables, scripts, links, forms, etc.) contained in the HTML document.
Here's a simplified view of the DOM tree:
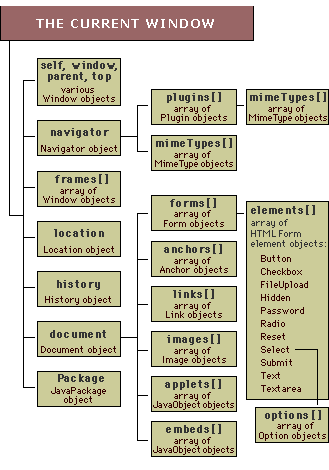
The document object has the write and writeln methods that allow scripts to dynamically insert text into the documents that contain them. See doc.html for a demonstration.