5
Reflection
and Persistence
5.1
Overview
Often an object oriented application maintains a model of its application domain. For example, an inventory control program might maintain a model of a warehouse with aisles and bins. In addition to the application domain, a reflective application maintains a model of itself. This allows users to query the application about design decisions, and in some cases negotiate changes in the design while the program is running.
The first half of this chapter introduces reflective systems by surveying reflection in Java, MFC, and C++. Unfortunately, reflection in C++ is inadequate for our purposes. To compensate, we introduce the Prototype Pattern, which allows programmers to instantiate classes at runtime. This is useful when the identity of the class is unknown at compile time.
After a brief survey of database systems, the second half of the chapter builds a framework for writing and reading objects to files. This is a major application of the Prototype Pattern. The framework is used in subsequent chapters.
5.2
Reflective
Modules
Recall the abstraction principle from Chapter One:
The implementation of a module should be independent of its interface.
Next to modularity, abstraction is probably the most important principle in engineering. A module that hides its implementation from clients is called a black box module, because it's like an impermeable black box with lights and buttons on the outside, but offering no clues about the wires and chips inside. Everyone knows that black box modules are easier to use and easier to replace. But if this is true, then why did a group of heretics at Xerox PARC question abstraction? (See [WWW 2], [WWW 3], [WWW 4], and [WWW 11].)
The implementer of a module is usually faced with several possible implementations. He must choose which implementation to map the interface onto. This is called a mapping dilemma. For example, how will we implement a function that must sort text files:
void sort(string fileName) { ??? }
Heap sort? Quick Sort? Insertion Sort? The implementer will probably choose an implementation that will give his clients the best average performance. This is called a mapping decision. For example, we would probably choose quick sort because it has the best average behavior. However, the choice of implementation may impose performance penalties on the occasional application that isn't average. This is called a mapping conflict. For example, heap sort might be better suited for an application that must sort large files. Now the client must either introduce awkward workarounds into his code, or build his own supporting module.
Unlike a black box module, a reflective module (sometimes called a glass box module) reduces mapping conflicts by allowing clients to inspect and alter some aspects of its implementation.
5.3
Reflective
Systems
A reflective or open implementation (OI) system has two levels, a base level and a meta level. Base-level objects provide application services through the system's normal user interface, while meta-level objects describe policies, structures, and strategies used by base-level objects to implement these services:

Meta level classes are called meta classes. Instances of meta classes are called meta objects. Instances of a base-level class, A, will often be linked to a single instance of a meta class, MetaA, which encapsulates a description of A. Before responding to a message, an instance of A will first consult its associated meta object for instructions:
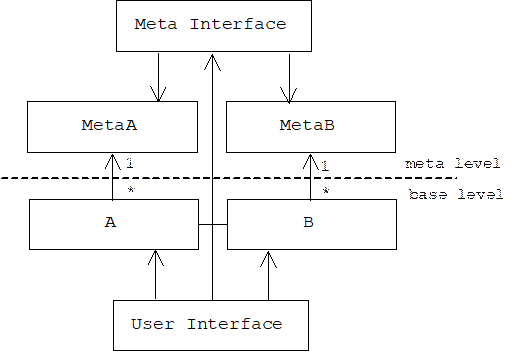
A meta interface or meta object protocol (MOP) allows clients— users and base-level objects —to access meta objects. Through the meta interface a client can inspect, modify, or replace a meta objects, thus dynamically changing the behavior of the associated base-level objects.
5.3.1 Applications of Reflective
Systems
5.3.1.1
Strategies
The Strategy Pattern introduced in Chapter 4 provides a small scale example of reflection. In this pattern the Context class belongs to the base level, while the associated Strategy class belongs to the meta level:

Changing the strategy used by an instance of the Context class, for example, changing the layout manager used by a frame, changes some aspect of the object's behavior.
5.3.1.2
Reflection
in UML
Sometimes it's better to represent application domain types as objects rather than classes. For example, a quantity is a number together with a unit: 5 kilometers, 3.50 US dollars, -20 degrees Fahrenheit, etc. We can think of a unit like US dollars as a type of number. Normally, types are represented by classes in an object oriented model:
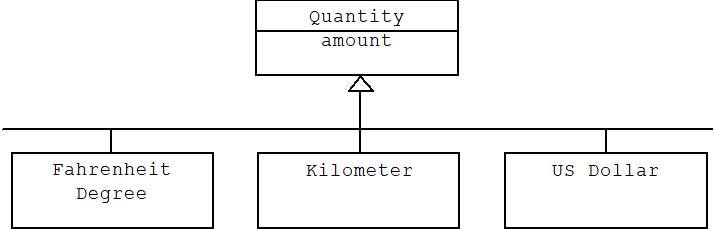
Unfortunately, a class hierarchy such as this one will never be complete. We will always be encountering new units. Adding these units to the hierarchy will involve changing the class diagram, adding new class declarations, and recompiling. Of course most programmers probably won't want a large cumbersome hierarchy that includes units they will never use, while others will complain that we've excluded exactly the units they need.
As an alternative, we can represent units as objects rather than classes:
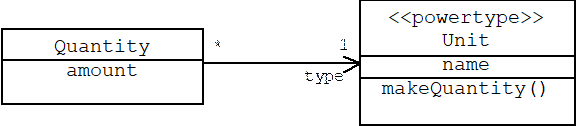
Now units such as Kilometer, US Dollar, and Fahrenheit Degree become instances of the Unit class. Adding new units is simply a matter of creating new instances of the Unit class, which can be done dynamically. Often Unit objects are factories that manufacture appropriately types quantities as products. (This prevents users from creating mistyped quantities.) As an added benefit, a Quantity object can answer the question: What is your unit? This is a primitive example of runtime type identification, which will be discussed later.
Unit is an example of a meta class, because we can regard a Unit object as a description of the Quantity objects linked to it. UML provides a <<metaclass>> stereotype for meta classes. In the case where instances of a meta class represent subtypes of a particular type, then it is more appropriate to use the <<powertype>> stereotype.
5.3.1.3
Reflective
Interpreters
An interpreter is a virtual machine that can execute programs without translating them into native machine code. The base level of a reflective interpreter consists of components needed to execute programs, such as a symbol table, an expression evaluator, a statement executor, a memory manager, and a control loop. Meta level components dictate semantic rules for the programming language such as parameter passing rules, scope rules, type equivalency rules, etc. By changing these meta level components, programmers can tailor the semantics of the programming language to suit a particular application.
5.3.1.4
Reflective
Operating Systems
A reflective operating system separates mechanisms (base level) from policies (meta level). For example, process swapping is a mechanism, but process scheduling: round robin, shortest job first, highest priority first, etc. is a policy that determines which processes to swap. Page replacement is a mechanism, but choosing the page to replace: least recently used, least frequently used, oldest, etc. is a policy. In a sense, all operating systems share the same basic mechanisms, but the "personality" of an operating system— for example the difference between Unix, MacOS, OS2, and Windows NT— is determined by the policies it uses. By allowing users to examine and change policies, we allow users to change the personality of their operating system.
This is similar to the idea behind the Microkernel Architecture used by Windows NT. Basic mechanisms are encapsulated in the microkernel, while policies are encapsulated in internal servers. The original idea was that Windows NT users could run Unix and OS2 applications simply by changing internal servers.
5.3.1.5
Meta
Programming
Objects that represent programming elements such as statements, variables, functions, and types are common meta-objects that are found in meta-programs: programs that manipulate other programs as data. Compilers, interpreters, debuggers, and optimizers are common examples of meta-programs.
Meta objects are also used in component-based programs. Recall that a component is an object known to its clients only through the interfaces it implements. Also recall that a client may not know which interfaces a component implements until runtime. Therefore, it is important that a component provides some standard way for clients to learn about these interfaces. We saw that ActiveX controls provide this by implementing the IUnknown interface. Java Beans— the Java notion of a component— don't need to implement a special interface because a Java Bean is a Java object, and every Java object is automatically associated with a number of meta objects that describe it. In fact, reflection in Java is so well developed, we can get a good picture of reflection in general by surveying its implementation in Java.
5.4
Reflection
in Java
All Java classes are subclasses of a pre-defined base class called Object. It doesn't matter if a programmer declares this or not. All Java classes are automatically subclasses of the Object base class. (Except for the Object class itself, obviously.) One advantage of this scheme is that it allows Java programmers to create generic methods and classes. This eliminates the need for templates. For example, here is how a Java programmer might declare a generic stack container. Notice that we avoid difficulties over the type of items stored in a stack by generically referring to all of them as Objects:
public class Stack {
private final int MAX = 200;
private int top = 0;
private Object[] stack = new
Object[MAX];
public void push(Object obj)
throws StackError {
if (MAX <= top) throw new
StackError("stack full");
stack[top++] = obj;
}
public Object pop() throws
StackError {
if (top <= 0) throw new
StackError("stack empty");
return stack[--top];
}
// etc.
}
Another advantage of this scheme is that any features placed in the Object base class are automatically inherited by all present and future Java classes. So what sort of features are contained in the Object base class? Currently, the Object base class includes methods that allow any object to duplicate itself (clone), convert itself into a string (toString), compare itself with another object (equals), wait for an event to occur (wait), be notified that an event has occurred (notify), and to answer the questions, "What is your identification number?" (hashCode) and "What class are you an instance of?" (getClass):
public class Object {
protected Object clone() { ... }
public boolean equals(Object obj) { ...
}
public String toString() { ... }
public void notify() { ... }
public void wait() { ... }
public int hashCode() { ... }
public Class getClass() { ... }
// etc.
}
This last feature is interesting. What sort of answer do we expect when we ask an object what class it instantiates? We expect a class, of course. But only objects, not classes, exist at runtime. How can an object return a class in response to this query? The solution is that instead of returning a class, it returns an object representing a class. At first this notion sounds strange. How can objects represent classes? But of course objects represent all sorts of things: cars, houses, boats, people, cats, planets. Why not classes?
The class of all objects that represent classes is defined in the java.lang package. Naturally, the name of this class is Class. It includes methods for discovering the name of the class (getName), the super class (getSuperClass), the methods (getMethods), and the attributes (getFields):
class Class {
public static Class forName(String name)
{ ... }
public Object newInstance() { ... }
public String getName() { ... }
public Class getSuperClass() { ... }
public Field getField(String name) {
... }
public Field[] getFields() { ... }
public Method getMethod(String name) {
... }
public Method[] getMethods() { ... }
// etc.
}
Of course this implies that there are also objects representing methods and fields. Naturally, these objects belong to the Method and Field classes, respectively, and of course like all Java classes, Class, Method, and Field are subclasses of the Object base class:

5.4.1 Runtime Type Information
(RTTI) in Java
To demonstrate reflection in Java, we introduce a hierarchy of classes that represent different types of musical notes:

The Note class declares two public integer fields representing the duration and frequency of a note. It also declares a play() method that simply prints a message in the console window, as well as a static method called main(), where we can place our test code:
public class Note {
public int frequency = 60; // frequency of note in Hz
public int duration = 300; // duration of note in millisecs
public void play() {
System.out.println("Playing a
generic note");
}
public static void main(String[] args)
{
// test code goes here
}
}
HornNote and ViolinNote are subclasses of Note that override the inherited play() method:
class HornNote extends Note {
public void play() {
System.out.println("Playing a
horn note");
}
}
class ViolinNote extends Note {
public void play() {
System.out.println("Playing a
violin note");
}
}
Our test driver, Note.main(), begins by declaring a reference to a note:
Note note;
Unlike C++, no object is created by this declaration. Instead, note is simply a variable capable of holding a reference to any object that instantiates the Note class or any of its subclasses. Java objects are created by the new operator, which creates an object on the heap, then returns a reference to it. The following statement creates a HornNote object, then places a reference to this object in the note variable:
note = new HornNote();
Next, we ask note which class it instantiates, then print the name of this class:
Class c = note.getClass();
System.out.println("class of note = " + c.getName());
Here is the output produced:
class of note = HornNote
Notice that Java wasn't fooled by the fact that note was declared as a Note reference. Instead, it dug deeper, returning the class of the object note currently references. To make this point clearer, we reassign note so that it references a ViolinNote, reassign c so that once again refers to the class of note, then print the class name:
note = new ViolinNote();
c = note.getClass();
System.out.println("now class of note = " + c.getName());
Now here's the output produced:
now class of note = ViolinNote
Again notice that getClass() actually fetches the class of the object, not simply the class of the reference.
Of course we can reassign c to reference any super class of ViolinNote:
c = c.getSuperclass();
System.out.println("base class of note = " + c.getName());
c = c.getSuperclass();
System.out.println("base of base class of note = " + c.getName());
Here is the output produced:
base class of note = Note
base of base class of note = java.lang.Object
5.4.2 Introspection in Java
In addition to information about super classes, we can also find out about the methods and fields of a class. Assuming c still references an object representing the ViolinNote class, then the following loop prints out the names of all of the ViolinClass methods:
Method methods[] = c.getMethods();
for(int i = 0; i < methods.length; i++)
System.out.println(methods[i].getName());
Here's the output produced:
main
hashCode
wait
wait
wait
getClass
equals
toString
notify
notifyAll
play
Notice that in addition to play(), all methods inherited from the Note and Object super classes are also listed. (The wait() method inherited from the Object super class appears three times because there are actually three different methods with this name.) Of course we could have printed out much more than the names of the methods. For example, we could have printed the parameter lists, the exception lists, and the return types.
The following code prints the names of the ViolinNote fields as well as their current values in the particular ViolinNote object referenced by note:
Field fields[] = c.getFields();
try {
for(int i = 0; i < fields.length;
i++) {
System.out.print(fields[i].getName()
+ " = ");
System.out.println(fields[i].getInt(note));
}
} catch(Exception e) {
// handle e
}
Here is the output produced:
frequency = 60
duration = 300
Non-public fields aren't printed.
5.4.3 Invoking Method Objects
Surprisingly, we can ask a Method object to invoke the method it represents. Of course we must provide it with the implicit and explicit arguments. For example, let's create a generic Note object, then call its play() method using reflection:
note = new Note();
c = note.getClass();
Method meth = c.getMethod("play", null);
meth.invoke(note, null);
Here's the output produced:
Playing a generic note
We repeat the experiment using a HornNote:
note = new HornNote();
c = note.getClass();
meth = c.getMethod("play", null);
meth.invoke(note, null);
Here's the output produced:
Playing a horn note
Notice that the HornNote play() method was invoked instead of the Note play() method.
Finally, we repeat the experiment one last time using a ViolinNote:
note = new ViolinNote();
c = note.getClass();
meth = c.getMethod("play", null);
meth.invoke(note, null);
Here's the output produced:
Playing a violin note
Of course it's far more efficient to simply call the play() method directly:
note.play();
Reflection is useful in those situations where we don't know which method we want to call at the time we are writing our program. Instead, this information will only be available at runtime.
5.4.4 Dynamic Instantiation in Java
Sometimes we don't even know the type of object we want to create until our program is running. We saw examples of this problem when we introduced the Factory Method Pattern in Chapter 3. In Java, we can create an instance of a class, C, from a Class object representing C using the newInstance() method. To make things harder, we will assume nothing is known about C at compile time. This might be the case if we were trying to define a universal instrument class. A universal instrument can imitate all other types of instruments. This is done with a play() method that expects as its input only the name of the type of note to play:
class UniversalInstrument {
public void play(String noteType) {
try {
Class c =
Class.forName(noteType); // find
& load a class
Note note = (Note)
c.newInstance();
note.play();
} catch (Exception e) {
// handle e here
}
}
}
Internally, the play() method first converts the name of the class, noteType, into an object representing the class itself, using the static forName() method. For example, if noteType is the string "HornNote", then forName() searches for a file named HornNote.class (this is the conventional name for the file containing the binary definition of the HornNote class), dynamically loads the file into the Java virtual machine, then creates and returns a Class object representing the HornNote class.
From the Class object, c, the newInstance() method is invoked. This creates an instance of the class represented by c. Of course this is returned as an Object, so in our example we perform an explicit downcast to the Note class, then call the play() method.
After creating a universal instrument, our test driver calls the play() method twice. The first time the string "ViolinNote" is the argument. The second time the string "HornNote" is the argument:
UniversalInstrument inst = new UniversalInstrument();
String noteType;
noteType = "ViolinNote";
inst.play(noteType);
noteType = "HornNote";
inst.play(noteType);
Here's the output produced:
Playing a violin note
Playing a horn note
Of course if we wanted to create and play a HornNote followed by a ViolinNote, why not simply do it directly:
note = new HornNote();
note.play();
note = new ViolinNote();
note.play();
To see why, suppose instead of hardwiring the "ViolinNote" and "HornNote" strings into our test program, we allow the user to specify the strings:
System.out.print("enter a type of note: ");
noteType = MyTools.stdin.readLine();
inst.play(noteType);
We don't know what the user will enter, so we don't know what type of notes to make.
5.5
Runtime
Type Information in C++
Recently, type_info, a meta-class that provides a limited amount of somewhat unreliable runtime type information, was added to the standard C++ library. The type_info class includes member functions for discovering the name of the type (name and raw_name), for comparing types (== and !=), and for determining the order of types in collating sequences (collating sequences are used by objects representing locales):
class type_info
{
public:
virtual ~type_info();
int operator==(const type_info&
rhs) const;
int operator!=(const type_info&
rhs) const;
int before(const type_info& rhs)
const;
const char* name() const;
const char* raw_name() const;
private:
...
};
The standard C++ library also provides a global operator named typeid() that expects any expression as input and returns a constant reference to a type_info object representing the expression's type:
const type_info& typeid(exp);
For example, assume we define the C++ version of our Note class:
class Note
{
public:
Note()
{
frequency = 60;
duration = 300;
}
virtual void play()
{
cout << "playing a
generic note" << endl;
}
private:
int frequency; // in Hz
int duration; // in millisecs
};
As in our Java version, HornNote and ViolinNote are defined as subclasses:
class HornNote: public Note
{
public:
void play()
{
cout << "playing a horn
note" << endl;
}
};
class ViolinNote: public Note
{
public:
void play()
{
cout << "playing a violin
note" << endl;
}
};
For testing purposes, we introduce a global function that displays the name of the type of note pointed at by its parameter:
void displayType(Note* note)
{
const type_info& tp = typeid(*note);
cout << "type = "
<< tp.name() << endl;
}
Notice that the value returned by typeid() must be stored in a constant reference variable.
Our test driver, main(), passes the same note pointer to displayType() three times. However, each time the pointer points to a different type of Note object:
Note* note = new Note();
displayType(note);
note = new HornNote();
displayType(note);
note = new ViolinNote();
displayType(note);
To get main() and displayType() to compile, we need the following include directives:
#include <typeinfo>
#include <iostream>
using namespace std;
Some compilers generate the necessary type information by default. To save space, other compilers, such as VC++, require programmers to set special compiler options before the necessary type information will be generated.[1]
It should also be mentioned that distinct type information for a subclass is generated by the typeid() operator only if the base class is polymorphic (i.e., contains at least one virtual function). Otherwise, the typeid() operator simply produces the type_info object of the base class.
Unfortunately, the output produced by the test program is compiler-dependent. The output produced by DJGPP, a GNU compiler for Windows, prefaces the type names by their lengths:
type = 4Note
type = 8HornNote
type = 10ViolinNote
The output produced by VC++ prefaces type names with the string "class":
type = class Note
type = class HornNote
type = class ViolinNote
The typeid() operator can also convert a type expression into its associated type_info object.
const type_info& typeid(type-exp);
We can compare this object to the type_info object of an expression using the == operator. This could be used to perform safe downcasts. For example, assume we add a special honk() function to our HornNote class:
class HornNote: public Note
{
public:
void honk()
{
cout << "HONK,
HONK!\n";
}
// etc.
};
Assume a test program uses a generic Note pointer to point at a HornNote object:
Note* note = 0;
// and later:
note = new HornNote();
Now assume we want to call the honk() function. An explicit downcast will be required, but we want to be sure note points to a HornNote before proceeding. Here's one way to do this:
if (typeid(*note) == typeid(HornNote))
((HornNote*)note)->honk();
else
cerr << "Error: unexpected
type\n";
Of course this is exactly what the dynamic_cast<> operator does:
HornNote* hornNote = dynamic_cast<HornNote*>(note);
if (hornNote)
hornNote->honk();
else
cerr << "Error: unexpected
type\n";
5.6
Reflection
in MFC
Of course we could try to imitate Java in C++ by introducing our own meta classes. In fact, we can find meta classes in several proprietary C++ libraries, including Microsoft Foundation Classes (MFC), which is a framework for developing Windows applications in C++. Almost all MFC classes derive from the CObject[2] base class, which is roughly similar in purpose to Java's Object base class:
class CObject
{
public:
virtual CRuntimeClass*
GetRuntimeClass() const;
bool IsKindOf(const CRuntimeClass*
pClass) const;
// etc.
};
Any CObject-derived class, A, will redefine the virtual GetRuntimeClass() function, which returns an instance of CRuntimeClass that represents A. MFC's CRuntimeClass is roughly similar to Java's Class class:
class CRuntimeClass
{
public:
char* m_lpszClassName; // = class name
CObject* CreateObject();
bool IsDerivedFrom(const CRuntimeClass*
pBaseClass) const;
// etc.
};
5.6.1 Example
class Note: public CObject
{
public:
DECLARE_DYNCREATE( Note )
Note()
{
frequency = 60;
duration = 300;
}
virtual void play()
{
cout << "playing a
generic note" << endl;
}
private:
int frequency; // in Hz
int duration; // in millisecs
};
DECLARE_DYNCREATE is one of many macros provided by MFC. This one expands into the declarations of the member functions needed to support reflection. The macro must also appear in the subclasses of Note:
class HornNote: public Note
{
public:
DECLARE_DYNCREATE( HornNote )
void play()
{
cout << "playing a horn
note" << endl;
}
};
class ViolinNote: public Note
{
public:
DECLARE_DYNCREATE( ViolinNote )
void play()
{
cout << "playing a violin
note" << endl;
}
};
We place the macros that expand into the implementations of these member functions in the corresponding implementation file (e.g., note.cpp):
IMPLEMENT_DYNCREATE( Note, CObject )
IMPLEMENT_DYNCREATE( HornNote, Note )
IMPLEMENT_DYNCREATE( ViolinNote, Note )
Here are some of the include directives we will need:
#include <afx.h> // MFC library
#include <iostream>
using namespace std;
We will also need to tell the linker to link the MFC library with our program.[3] (Of course the MFC library is only available in certain integrated development environments such as Visual C++.)
Our test driver, main(), begins by creating a Note object, then printing the name of its class:
Note* note = new Note();
CRuntimeClass *rtclass = note->GetRuntimeClass();
cout << "class = " << rtclass->m_lpszClassName
<< endl;
Here's the output produced:
class = Note
Next, we point the note pointer at two other notes and print the class name:
note = new HornNote();
rtclass = note->GetRuntimeClass();
cout << "class = " << rtclass->m_lpszClassName
<< endl;
note = new ViolinNote();
rtclass = note->GetRuntimeClass();
cout << "class = " << rtclass->m_lpszClassName
<< endl;
Here's the output produced:
class = HornNote
class = ViolinNote
We can also ask if an object belongs to other classes. We form these classes using the RUNTIME_CLASS macro:
cout << "Is CObject? = ";
cout << note->IsKindOf(RUNTIME_CLASS(CObject)) << endl;
cout << "Is HornNote? = ";
cout << note->IsKindOf(RUNTIME_CLASS(HornNote)) << endl;
Here's the output produced:
Is CObject? = 1
Is HornNote? = 0
Reflection in MFC goes beyond runtime type identification. For example, we can dynamically create objects from meta objects.
rtclass = RUNTIME_CLASS(HornNote);
note = (Note*)rtclass->CreateObject();
cout << "class = " << rtclass->m_lpszClassName
<< endl;
Here's the output produced:
class = HornNote
5.7
Dynamic
Instantiation in C++ (The Prototype Pattern)
Unfortunately, C++ doesn't have built-in support for dynamic instantiation, but the prototype pattern provides a standard way to add this feature to C++ programs:
Prototype [Go4]
Problem
A "factory" class can't anticipate the type of "product" objects it must create.
Solution
Derive all product classes from an abstract Product base class that declares a pure virtual clone() method. The Product base class also functions as the product factory by providing a static factory method called makeProduct(). This function uses a type description parameter to locate a prototype in a static prototype table maintained by the Product base class. The prototype clones itself, and the clone is returned to the caller.
5.7.1 Static Structure
We saw that Java and MFC both required some common base class for all classes that can be dynamically instantiated: Object in Java and CObject in MFC. The Prototype Pattern also requires a common base class, which we call Product. In addition to serving as the base class for all products, the Product class maintains a static table that holds associations between names of Product-derived classes ("Product1" for example) and a corresponding prototypical instance of the class. It also provides a static function for adding new associations to the prototype table (addPrototype), and a static factory method for creating products (makeProduct). Finally, Product is an abstract class because it contains a pure virtual clone() method. The following diagram shows the Product class with three Product-derived classes.
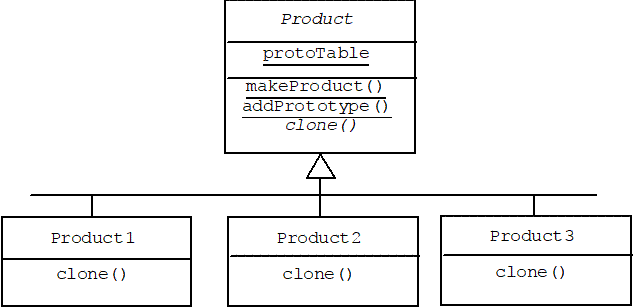
5.7.2 Test Program
Before describing the implementation, let's look at a test program. Our test driver, main(), begins by displaying the prototype table. It then enters a perpetual loop that prompts the user for the name of a product type, uses a static factory method to instantiate the type entered, then uses the RTTI feature of C++ to display the type of product created:
int main()
{
string description;
Product* p = 0;
cout << "Prototype
Table:\n";
cout << Product::protoTable
<< endl;
while(true)
{
cout << "Enter the type
of product to create: ";
cin >> description;
p =
Product::makeProduct(description);
cout << "Type of product
created = " ;
cout << typeid(*p).name()
<< endl;
delete p;
}
return 0;
}
5.7.3 Program Output
Curiously, the test program produces output before main() is called:
adding prototype for Product1
done
adding prototype for Product2
done
adding prototype for Product3
done
Apparently, prototypes of three product classes have been added to the prototype table. This is confirmed when the prototype table is displayed at the beginning of main(). It shows pairs consisting of the product name and the address of the corresponding prototype:
Prototype Table:
{
(Product1, 0xba1cc)
(Product2, 0xba1dc)
(Product3, 0xba1ec)
}
Now the loop begins. The user creates instances of each of the product classes, as confirmed by runtime type identification. (We are using the DJGPP compiler in this example.) When the user attempts to create an instance of an unknown class, an error message is displayed and the program terminates:
Enter the type of product to create: Product1
Type of product created = 8Product1
Enter the type of product to create: Product2
Type of product created = 8Product2
Enter the type of product to create: Product3
Type of product created = 8Product3
Enter the type of product to create: Product4
Error, prototype not found!
5.7.4 The Product Base Class
The main job of the Product base class is to maintain the prototype table. Since the prototype table contains associations between type names (string) and the addresses of corresponding prototypes (Product*), we declare it as a static map of type:
map<string, Product*>
The Product base class also provides a static factory method for dynamically creating products (makeProduct) and a static method for adding prototypes to the prototype table (addPrototype). Lastly, the Prototype Pattern requires that each product knows how to clone itself. This can be enforced by placing a pure virtual clone method in the Product base class (this idea is related to the Virtual Body Pattern in Chapter 4). Here's the declaration:
class Product
{
public:
virtual ~Product() {}
virtual Product* clone() const = 0;
static Product* makeProduct(string
type);
static Product* addPrototype(string
type, Product* p);
static map<string, Product*>
protoTable;
};
Recall that the declaration of a static class variable, like protoTable, is a pure declaration that simply binds a name (protoTable) to a type (map<>). No variable is actually created. Instead, this must be done with a separate variable definition. Assuming the Product class is declared in a file called product.h, we might want to place the definition of the prototype variable at the top of the file product.cpp:
// product.cpp
#include "product.h"
map<string, Product*> Product::protoTable;
Our product.cpp implementation file also contains the definitions of the makeProduct() factory method and the addPrototype() function.
The makeProduct() factory method uses the global find() function defined in util.h (which is listed in Appendix 3 and should be included at the top of product.h) to search the prototype table. The error() function defined in util.h is used to handle the error if the search fails. Otherwise, the prototype located by the search is cloned, and the clone is returned to the caller:
Product* Product::makeProduct(string type)
{
Product* proto;
if (!find(type, proto, protoTable))
error("prototype not
found");
return proto->clone();
}
The addPrototype() function has two parameters representing the name of a Product-derived class ("Product1" for example) and a pointer to a prototypical instance of that class. The function simply adds a new association to the prototype table. For debugging purposes, the statement is sandwiched between diagnostic messages. If for some reason we fail to add a particular prototype to the prototype table, we will know exactly which one caused problems. (More on this later.) Finally, notice that the prototype pointer is returned. The purpose of this return statement will also be explained later.
Product* Product::addPrototype(string type, Product* p)
{
cout << "adding prototype
for " << type << endl;
protoTable[type] = p;
cout << "done\n";
return p; // handy
}
5.7.5 Creating Product-Derived
Classes
One measure of quality for a framework is how easy it is to customize. Frameworks with heavy overhead (i.e., that require customizers to write hundreds of lines of code beyond what they already have to write) are often very unpopular. How much extra work is it to derive a class from our Product base class? Only four extra lines of code are required.
Assume we want to declare a class named Product1 in a file named product1.h. We want to be able to dynamically instantiate Product1, so we must derive it from the Product base class. The bold face lines show the overhead imposed by the Product base class:
// product1.h
#include "product.h"
class Product1: public Product
{
public:
IMPLEMENT_CLONE(Product1)
// etc.
};
Assume the Product1 class is implemented in a file named product1.cpp. We must add a single line to that file, too:
// product1.cpp
#include "product1.h"
MAKE_PROTOTYPE(Product1)
// etc.
5.7.6 Macros
IMPLEMENT_CLONE() and MAKE_PROTOTYPE() are macros defined in product.h. Recall that macro calls are expanded by the C pre-processor before compilation begins. For example, if a programmer defines the following macro:
#define PI 3.1416
All calls or occurrences of PI in a program are replaced by the value 3.1416.
Macros can also have parameters. In this case an argument is specified when the macro is called, and the expansion process automatically substitutes the argument for all occurrences of the corresponding parameter in the macro's body.
For example, each Product-derived class must implement the pure virtual clone() function specified in the Product base class. In fact, the implementations are simple and won't vary much from one class to the next. There is a risk, however, that programmers might get too creative and come up with an implementation that's too complex or just plain wrong.
To reduce this risk, we provide the IMPLEMENT_CLONE() macro, which is parameterized by the type of product to clone. The macro body is the inline implementation of the required clone function:
#define IMPLEMENT_CLONE(TYPE) \
Product* clone() const { return new
TYPE(*this); }
(Notice that macro definitions the span multiple lines use a backslash character as a line terminator.)
We placed a call to this macro in the declaration of the Product1 class:
class Product1: public Product
{
public:
IMPLEMENT_CLONE(Product1)
// etc.
};
After pre-processor expands this call the declaration of Product1 will look like this:
class Product1: public Product
{
public:
Product* clone() const {return new Product1(*this);
}
// etc.
};
Notice that the TYPE parameter in the macro body has been replaced by the Product1 argument, forming a call to the Product1 copy constructor. Readers should verify that the implementation correctly returns a clone of the implicit parameter.
5.7.7 Creating Prototypes
The output produced by our test program showed three prototypes were created and added to the prototype table before main() was called. How was that done? In general, how can programmers arrange to have code executed before main()? Isn't main() the first function called when a C++ program starts?
Actually, we can arrange to have any function called before main(), provided that function has a return value. For example, the function:
int hello()
{
cout << "Hello,
World\n";
return 0; // a bogus return value
}
will be called before main() if we use its return value to initialize a global variable:
int x = hello(); // x = a bogus global
This can be verified by placing a diagnostic message at the beginning of main() and observing that the "Hello, World" message appears first.
Recall that the addPrototype() function returned a pointer to the prototype. If we use this return value to initialize a bogus global Product pointer variable:
Product* Product1_myPrototype =
Product::addPrototype("Product1",
new Product1());
then the call to addPrototype() will precede the call to main(). In principle, we can build the entire prototype table before main() is called.
Our MAKE_PROTOTYPE() macro expands into definitions like the one above:
#define MAKE_PROTOTYPE(TYPE) \
Product* TYPE ## _myProtoype = \
Product::addPrototype(#TYPE, new
TYPE());
During expansion, the macro parameter, TYPE, will be replaced by the macro argument, Product1 for example, in three places. First, the ## operator is used to concatenate the type name with _myPrototype. In our example this produces Product1_myPrototype, a (hopefully) unique name for a global variable.
Second, the # operator is used to stringify the argument. If the argument is Product1, #TYPE will be replaced by "Product1", the string name of the type.
Finally, the last occurrence of the TYPE parameter will be replaced by a call to the default constructor specified by the argument.
5.7.8 Linker Issues
Adding entries to the prototype table before main() is called is risky. Recall that the definition of the prototype table occurs in product.cpp, while the calls to the MAKE_PROTOTYPE() macro occur in the files product1.cpp, product2.cpp, and product3.cpp. These files will compile into the object files product.o, product1.o, product2.o, and product3.o, respectively, which will be linked with main.o by the linker (ld). The actual link command might look like this:
ld demo main.o product.o product1.o product2.o product3.o
Suppose the order of object file arguments passed to the linker is modified:
ld demo main.o product1.o product.o product2.o product3.o
In the executable image produced by the linker, the declaration:
Product* Product1_myPrototype =
Product::addPrototype("Product1",
new Product1());
contained in product1.o may precede the creation of the prototype table contained in product.o:
map<string, Product*> Product::protoTable;
Since the call to addPrototype() attempts to install a pair into the prototype table, this will result in a mysterious program crash that defines most debuggers, because the problem occurs before main() is called. (In our case this bug will be easy to catch thanks to the diagnostic messages printed by addPrototype.)
The problem is easily rectified if we abandon the idea of adding entries to the prototype table before main() is called. In this case the macro calls would be made at the top of main():
int main()
{
MAKE_PROTOTYPE(Product1)
MAKE_PROTOTYPE(Product2)
MAKE_PROTOTYPE(Product3)
// etc.
}
5.7.9 Ken’s Idea
typedef map<string, Product*> PTTYPE;
PTTYPE& Product::getProtoTable() {
static PTTYPE protoTable;
return protoTable;
}
Product* Product::addPrototype(string type, Product* p)
{
cout << "adding prototype
for " << type << endl;
getProtoTable()[type] = p;
cout << "done\n";
return p; // handy
}
5.8
Persistence
Persistent objects can be saved to and restored from files or databases. Transient objects can't be saved or restored. Transient objects simply disappear when the application that created them terminates, if not before. We can extend these ideas to classes in the usual way: a class is persistent if its instances are persistent, and transient if its instances are transient. By default, all C++ and Java classes are transient. Usually, programmers must write extra code to declare persistent classes.
Objects representing important entities or events in an application domain generally need to be persistent. For example, business domain objects such as accounts, invoices, and transactions should be persistent; health care domain objects such as records of patients, treatments, and test results need to be persistent; and engineering domain objects such as part models, reports, and workflows ought to be persistent.
Not all objects need to be persistent, however. For example, it would be a waste of secondary memory to store user interface objects such as windows, control panels, message handlers, and message dispatchers. It's more efficient to create new instances of these objects each time the application restarts. These objects tend to be transient.
5.8.1 Object-Oriented Databases
In an ideal world, persistent objects would be stored in object-oriented databases: databases specifically designed to store objects in a language-neutral format. When, for example, a C++ program references an object stored in such a database, an object fault occurs: the database manager automatically fetches the object, translates it into a C++ object, and loads it into the program's address space. If our C++ program updates this object, then the modified object is automatically translated back into a language-neutral object that replaces the original object in the database. Later, a Java program can reference and update the same object. The sequence of events is identical except this time the translation is between Java and the language-neutral format.
Because the object-oriented database manager automates the movement of objects between databases and programs, the line between primary and secondary memory becomes transparent; programmers no longer need to explicitly save and restore persistent objects. Naturally, the database manager also provides search functions and maintains the consistency of the database by preventing synchronization problems. Object-oriented databases are discussed further in Programming Note 5.12.2.
5.8.2 Relational Databases
In the real world successful object-oriented applications need to be able to save and restore persistent objects using relational databases. Relational databases predate the object-oriented paradigm, which, among other things, means they are far more entrenched in the market place.
Relational databases store tables, not objects. Instances of a class, C, would be stored in a relational database as rows of a table, TC, with columns that correspond to an attributes of C. For example, assume a persistent Student class has been declared as follows:
class Student
{
public:
Student(string ln, string fn, float
avg,
Course* p1, Course* p2,
Course* p3);
// etc.
private:
string lastName, firstName;
float gpa; // grade point average
// current course schedule:
Course *period1, *period2, *period3;
};
Assume three instances of this class have been created and are subsequently saved to the "Student" table in the "School" database:
Student
s1("Anderson",
"Mary", 3.14, &physics2, &math2, &chem2),
s2("Jones", "Mark",
2.9, &physics2, &math1, &chem2),
s3("Smith", "Bob",
3.4, &physics1, &math1, &chem1);
save("School", "Student", s1);
save("School", "Student", s2);
save("School", "Student", s3);
These objects appear as rows in the Student table (TStudent):
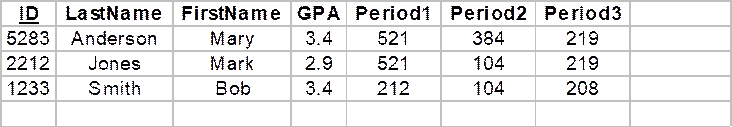
The first column of this table holds a unique identification number automatically assigned to each object by the database manager. In a sense, this identification number can be thought of as the object's "address" within the database. (Of course the usual concept of address doesn't make sense in secondary memory.) Instead of storing the pointer to the course a student takes during a given period, which wouldn't make sense either, we store the identification number of a row in the School database's Course table. Relational databases are discussed further in Programming Note 5.12.1.
Unfortunately, translating between objects and rows in a table isn't automatically done by a relational database manager. Programmers must explicitly read and write each field of an object to the database using special library functions provided by the database vendor. This is sometimes referred to as impedance mismatch: the mismatch between data formats commonly used in main memory (e.g., objects) and data formats commonly used in secondary memory (e.g., table rows). It has been estimated that 30% of both implementation time and execution time is devoted to translating between data formats.
5.9
Serialization
Assume we must implement persistent objects, but no database is available, neither relational nor object oriented. We could simply require all classes of persistent objects to provide a member function that inserts each member variable into a given file stream[4] (this process is called serialization) and a member function that extracts data from a given file stream and puts it into the corresponding member variable (this process is called deserialization.) We can force everyone to use the names serialize() and deserialize() for these member functions by creating an abstract base class for all persistent objects:
class Persistent
{
public:
virtual void serialize(fstream& f)
= 0;
virtual void deserialize(fstream&
f) = 0;
// etc.
};
Implementing serialize() and deserialize() seems simple: serialize() writes each member variable to a file stream, and deserialize() reads each member variable from a file stream, in the same order they were written. For example:
class Person: public Persistent
{
public:
void serialize(fstream& f)
{
f << name << endl;
f << gender << endl;
f << age << endl;
}
void deserialize(fstream& f)
{
f >> name;
f >> gender;
f >> age;
}
// etc.
private:
string name;
char gender; // 'M' = male, 'F' =
female, 'U' = unknown
int age;
};
To save a Person object, a writer program creates a file stream for output, then calls the object's serialize() member function:
fstream fs("employees", ios::out);
Person smith("Smith", 'F', 42);
smith.serialize(fs);
We can peek at the employees file using an ordinary text editor:
Smith
F
42
A reader program can restore this object by creating a file stream for input, creating a Person object to hold the data, then calling the deserialize member function:
fstream fs("employees", ios::in);
Person x; // create memory for data
x.deserialize(fs);
Although the member variables of x initially hold default values, after deserialization these values are replaced by Smith's data. Even object member variables can be easily saved and restored, as long as they too provide serialize() and deserialize() functions. For example, assume mailing addresses are persistent:
class Address: public Persistent
{
public:
void serialize(fstream& f)
{
f << building << endl;
f << street << endl;
f << city << endl;
f << state << endl;
}
void deserialize(fstream& f)
{
f >> building;
f >> street;
f >> city;
f >> state;
}
// etc.
private:
int building;
string street, city, state;
};
If we add an Address member variable to our Person class, then we only need to add a call to Address::serialize() in Person::serialize() and a call to Address::deserialize() in Person::deserialize():
class Person: public Persistent
{
public:
void serialize(fstream& f)
{
f << name << endl;
f << gender << endl;
f << age << endl
address.serialize(f);
}
void deserialize(fstream& f)
{
f >> name;
f >> gender;
f >> age;
address.deserialize(f);
}
// etc.
private:
string name;
char gender; // 'M' = male, 'F' =
female, 'U' = unknown
int age;
Address address; // = mailing
address
};
As long as the implementer of Person knows that the Address class is derived from the Persistent base class, then he doesn't need to know the details of how to serialize or deserialize Address objects.
5.9.1 Pointer Problems
Unfortunately, our simple plan runs into problems if the address member variable holds a pointer to an Address object instead of an Address object (which would make sense, because several people might share the same address):
class Person: public Persistent
{
// etc.
private:
string name;
char gender; // = 'M', 'F', or 'U'
int age;
Address* address; // points to
mailing address
};
There are three problems:
Problem 1:
Restoring Pointers
Of course we can write a pointer into a file, and we can read it back:
Address *x = new Address(...), *y;
fs << x;
fs >> y; // same as y = x
But what do we do with a pointer we have read from a file that was put there by another program or by a previous activation of the same program? Although the pointer may have been valid in the address space of the writer program, it certainly isn't going to be valid in the address space of the reader program.[5]
Problem 2:
Allocating Memory for Hidden Objects
Obviously we will have to abandon pointers when an object is serialized, and we will have to create new pointers to freshly created objects when an object is deserialized:
fstream fs("employees", ios::in);
Person x; // allocate memory for x
x.address = new Address(); // allocate memory for x.address
x.deserialize(fs); // calls (x.address)->deserialize(fs);
Although the author of the reader program may know that the employees file contains data for a Person object, and therefore that he must create a Person object, x, to receive this data, it seems unreasonable to demand that he also know about the associated Address object. In effect, the author of a reader program would need to know almost the entire implementation of any object that he intended to deserialize. It's more likely that the types of objects linked to a deserialized object would only be discovered while the reader program was running, long after it was written. Unfortunately, C++ doesn't have the built-in flexibility to create objects from type information at runtime.
Problem 3: Avoiding
Unwanted Duplications
Assume Problems 1 and 2 can be solved. We must remember that an object might contain many pointers to other objects, and these objects may contain pointers to still other objects. When we save an object, a, we are really saving an entire network of objects rooted at a and linked by pointers. This network is called the transitive closure of a.
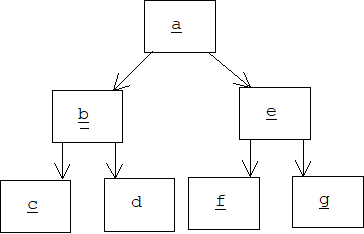
The transitive closure of an object is a directed graph, so we can use a depth-first traversal algorithm to ensure that any object that can be reached from a will be serialized, but what happens if there are two paths to the same object, or worse, if the graph contains a loop:
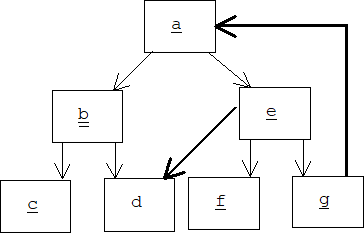
If we are not careful, then d will be serialized twice, once by b and again by e, which will result in two copies of d after deserialization. Actually, d will be serialized an infinite number of times because serializing a causes g to be serialized, and serializing g causes a to be serialized!
5.9.2 A Framework for Persistence
Let's develop a framework that solves these problems and that can be reused for implementing persistent objects. As with all frameworks, an important goal is to minimize the amount of work programmers who customize the framework must do.
Before we describe the framework internals, let's see how it is used. Returning to our earlier example, suppose that we kept declarations of business classes such as Person and Address in a file called bus.h:
// bus.h
#ifndef BUS_H
#define BUS_H
#include "obstream.h" // persistence framework
#include <cstring> // same as
<string.h>
class Address { ... };
class Person { ... };
// etc.
#endif
Here's the declaration of the Address class. To make things more transparent, our initial version uses C strings instead of C++ strings:
class Address: public Persistent
{
public:
Address();
Address(int b, char* s, char* c, char*
st);
IMPLEMENT_CLONE(Address)
void serialize(ObjectStream& os)
;
void deserialize(ObjectStream& os);
friend ostream& operator<<(ostream&
os, const Address& addr);
// etc.
private:
int bldg;
char *street, *city, *state;
};
Clearly the serialize() and deserialize() functions implement pure virtual functions inherited from the Persistent base class. We declare a variant of the global insertion operator, operator<<(), as a friend to provide some ability to display the private data of an Address object. This will be used primarily for testing purposes.
Because the street, city, and state attributes are pointers, it might have been a good idea to employ the Canonical Form Pattern from Chapter 4. We hide this code to simplify our demonstration.
Finally, notice the call to the IMPLEMENT_CLONE() macro. This suggests we are employing the Prototype Pattern. Further evidence of this can be found in the implementation file, bus.cpp, where a call to the MAKE_PROTOYPE() macro can be found:
MAKE_PROTOTYPE(Address)
We also find implementations of the serialize() and deserialize() functions in bus.cpp:
void Address::serialize(ObjectStream& os)
{
::serialize(os, bldg);
::serialize(os, street);
::serialize(os, city);
::serialize(os, state);
}
void Address::deserialize(ObjectStream& os)
{
::deserialize(os, bldg);
::deserialize(os, street);
::deserialize(os, city);
::deserialize(os, state);
}
There are two things to notice about these implementations. First, the parameters are no longer simple file streams. Instead, something called ObjectStreams are used. Second, both functions call global serialize() and deserialize() functions to serialize and deserialize their fields. Apparently these functions are provided by the persistence framework (obstream.h).
Returning to bus.h, the declaration of the Person class, which now contains a pointer to an Address instance, follows the same pattern as the Address declaration:
class Person: public Persistent
{
public:
Person();
Person(char *nm , char gen, int a,
Address* addr);
IMPLEMENT_CLONE(Person)
void serialize(ObjectStream& os) ;
void deserialize(ObjectStream& os);
friend ostream&
operator<<(ostream& os, const Person& per);
private:
char* name;
int age;
char gender; // 'M' = male, 'F' =
female, 'U' = unknown
Address* address;
};
The implementation file, bus.cpp, applies the MAKE_PROTOYPE() macro to the Person class:
MAKE_PROTOTYPE(Person)
The implementations of the serialize() and deserialize() functions use global serialize() and deserialize() functions to serialize and deserialize member variables, including the Address pointer:
void Person::serialize(ObjectStream& os)
{
::serialize(os, name);
::serialize(os, age);
::serialize(os, gender);
::serialize(os, address);
}
void Person::deserialize(ObjectStream& os)
{
::deserialize(os, name);
::deserialize(os, age);
::deserialize(os, gender);
::deserialize(os, (Persistent*) address);
}
Implementations of the insertion operators are left as an exercise to the reader.
5.9.3 Test Program
Our test driver functions as both the writer and the reader program. This isn't cheating because the reader half doesn't use any of the objects created by the writer half. The writer half creates three Person objects. Two share an address:

Assume the test program is called main.exe and is invoked from the command line as follows:
main people
Before main() is called, we notice several messages displayed in the console window:
adding prototype for type = 7Address
done
adding prototype for type = 6Person
done
Clearly this is the work of the CREATE_PROTOTYPE() macro at work.
Main() begins by checking for the command line argument:
int main(int argc, char* argv[])
{
if (argc != 2)
{
cerr << "usage: "
<< argv[0] << " FILE\n";
exit(1);
}
Next, main() attempts to create and open an object stream for output. This creates a new file with the name stored in argv[1], which should be the string, "people":
ObjectStream os;
os.open(argv[1], ios::out);
if (!os)
{
cerr << "can't open write
file\n";
exit(1);
}
If all goes well, two Address objects and three Person objects are created:
Address a(123,
"Sesame St.", "New York City", "NY");
Address b(100, "Detroit
Ave.", "San Francisco", "CA");
Person p("Bill Jones", 'M',
42, &a);
Person q("Ed Smith", 'U', 33,
&b);
Person r("Sue Jones", 'F',
45, &a);
For diagnostic purposes, we print the three Person objects:
cout << p <<
'\n';
cout << q << '\n';
cout << r << '\n';
Here is the output produced:
(type = 6Person, location = 0xa0bf04, OID = 504)
Mr. Bill Jones
age = 42
(type = 7Address, location = 0xa0bf34, OID = 502)
123 Sesame St.
New York City, NY
(type = 6Person, location = 0xa0beec, OID = 505)
Ed Smith
age = 33
(type = 7Address, location = 0xa0bf1c, OID = 503)
100 Detroit Ave.
San Francisco, CA
(type = 6Person, location = 0xa0bed4, OID = 506)
Ms. Sue Jones
age = 45
(type = 7Address, location = 0xa0bf34, OID = 502)
123 Sesame St.
New York City, NY
Notice that Bill and Sue Jones both have pointers to the same Address object.
All three Person objects are serialized into the object stream, os, and the stream is closed:
p.serialize(os);
q.serialize(os);
r.serialize(os);
os.close();
We now enter the reader half of main(), which could just as easily have been implemented as a separate program. It begins by opening a second object stream for input using "people", the name still stored in argv[1]:
ObjectStream os2;
os2.open(argv[1], ios::in);
if (!os2)
{
cerr << "can't open read
file\n";
exit(1);
}
If all goes well, memory is allocated for three person objects, but no memory is allocated for the corresponding addresses. Presumably this is done dynamically, when the object stream is deserialized:
Person p2, q2, r2;
p2.deserialize(os2);
q2.deserialize(os2);
r2.deserialize(os2);
To confirm the deserialization process, we display the new Person objects and quit:
cout << p2 <<
'\n';
cout << q2 << '\n';
cout << r2 << '\n';
return 0;
}
Here is the output produced:
(type = 6Person, location = 0xa0be28, OID = 507)
Mr. Bill Jones
age = 42
(type = 7Address, location = 0x50980, OID = 502)
123 Sesame St.
New York City, NY
(type = 6Person, location = 0xa0be10, OID = 508)
Ed Smith
age = 33
(type = 7Address, location = 0x509f8, OID = 503)
100 Detroit Ave.
San Francisco, CA
(type = 6Person, location = 0xa0bdf8, OID = 509)
Ms. Sue Jones
age = 45
(type = 7Address, location = 0x50980, OID = 502)
123 Sesame St.
New York City, NY
Notice that the correct Address objects have been created. Also notice that Bill and Sue Jones share an address object, although the location of this object is different from the location of the original Address object. The deserialization mechanism preserved the object identifiers (OIDs) of the Address objects, but not the OIDs of the Person objects. This is because our program explicitly created new Person objects.
As it turns out, people, the file containing the serialized objects, is an ordinary text file that can be read by an ordinary text editor. Here is what it contains:
(10)Bill Jones
42
M
502 7Address
123
(10)Sesame St.
(13)New York City
(2)NY
(8)Ed Smith
33
U
503 7Address
100
(12)Detroit Ave.
(13)San Francisco
(2)CA
(9)Sue Jones
45
F
502
Notice that each field appears on a separate line. This makes reading the file easy. Each string field is preceded by the length of the string in parenthesis. The Address pointers have been translated into an object identifier followed by the type name. For example:
502 7Address
This is followed by the Address object itself. The only exception is the pointer to Sue Jones' address, which is simply the object identifier, 502. Presumably this is because the actual Address object occurs earlier in the file, after the entry for Bill Jones.
5.9.4 Implementing the Framework
The persistence framework consists of four parts: the Persistence base class, several macros, the ObjectStream class, and a collection of global functions for serializing and deserializing primitive data. Most of these definitions are contained in a file named obstream.h:
// obstream.h
#ifndef OBSTREAM_H
#define OBSTREAM_H
#include "..\util\util.h"
class ObjectStream; // forward reference
class Persistent { ... };
class ObjectStream: public fstream { ... };
// macros:
#define MAKE_PROTOTYPE(TYPE) ...
#define IMPLEMENT_CLONE(TYPE) ...
// global serialization & deserialization utilities:
void serialize(ObjectStream& os, Persistent* obj);
void deserialize(ObjectStream& os, Persistent*& obj);
void deserialize(ObjectStream& os, char& x);
void serialize(ObjectStream& os, const char* x);
void deserialize(ObjectStream& os, char*& x);
// etc.
#endif
The Persistent class follows the Prototype Pattern discussed earlier. It maintains a static prototype table, provides a function for adding entries to the table (addPrototype), and a factory method for dynamically creating new Persistent objects (makePersistent). In fact, the implementations of these functions are nearly identical to the implementations given in the Prototype Pattern (except we replace Product by Persistent).
The Persistent class declares three pure virtual functions that must be implemented by derived classes: clone(), serialize(), and deserialize(). The clone() function is required by the Prototype Pattern. It will be implemented using the IMPLEMENT_CLONE() macro exactly as before. Our test program gave examples of how the serialize() and deserialize() functions might be implemented by derived classes.
Finally, the Persistent class automatically assigns a brand new object identifier (OID) to every Persistent object. Here's a listing of the declaration:
class Persistent
{
public:
Persistent() { OID = nextOID++; }
Persistent(const Persistent& p) {
OID = nextOID++; }
virtual ~Persistent() {}
int getOID() const { return OID; }
void setOID(int id) { OID = id; }
string getType() const { return
typeid(*this).name(); }
// overridables:
virtual Persistent* clone() const = 0;
virtual void
serialize(ObjectStream& os) = 0;
virtual void
deserialize(ObjectStream& os) = 0;
// prototype support:
static Persistent*
makePersistent(string type);
static Persistent* addPrototype(string
type, Persistent* p);
private:
static map<string, Persistent*>
protoTable;
static int nextOID;
int OID; // object identifier for
this object
};
Of course we must remember to define an initialize the static class variables in obstream.cpp:
map<string, Persistent*> Persistent::protoTable;
int Persistent::nextOID = 500; // make OIDs impressively large
We make a minor modification to the MAKE_PROTOYPE() macro. Instead of stringifying the TYPE parameter to generate the type name argument for the call to addPrototype(), we use the global typeid() function to generate the type name from the parameter:
#define MAKE_PROTOTYPE(TYPE) \
Persistent* TYPE ## _myProtoype = \
Persistent::addPrototype(typeid(TYPE).name(),
new TYPE());
This is done because typeid() is called by the getType() member function, which in turn is called by the framework to provide the type names that will be written to files when pointers are serialized. It's important that this type name matches the type name that the pointer deserialization function will find in the prototype table. (Of course there are other ways to accomplish this.)
5.9.5 Pointer Swizzling and Object
Streams
As we have seen, the biggest problem our framework faces is how to serialize and deserialize pointers to persistent objects. The standard trick for solving this problem is called pointer swizzling: each time a pointer, p, to a Persistent object needs to be serialized, the OID and type name of the object *p is written to the file instead of p. When a pointer is deserialized, the type name is read from the file and used by the Prototype Pattern to dynamically create a new object.
How do we avoid unnecessary duplications? This is where the object identifiers come in. Every object stream maintains two tables. The save table stores associations between serialized pointers and object identifiers:
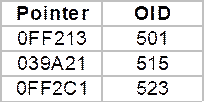
Save Table
The load table stores inverse associations between object identifiers and deserialized pointers:

Load Table
Each time a pointer is serialized, a new entry is created in the save table. When a pointer is about to be serialized, the save table is consulted to determine if the same pointer has previously been serialized. If so, then only the corresponding OID is written to the file.
Each time a pointer is deserialized, an entry is made in the load table. Before a pointer is deserialized, the OID is read from the file and the load table is searched to determine if the pointer has already been deserialized.
The ObjectStream class inherits file I/O machinery from the fstream class. It adds the save and load tables as well as functions for searching these tables. Since the functions that serialize and deserialize pointers will need to access these tables, they are declared as friends:
class ObjectStream: public fstream
{
public:
Persistent* find(int oid); // searches
load table
int find(Persistent* obj); // searches
save table
friend void serialize(ObjectStream&
os, Persistent* obj);
friend void
deserialize(ObjectStream& os, Persistent*& obj);
private:
// for pointer swizzling:
map<int, Persistent*> loadTable;
map<Persistent*, int> saveTable;
};
5.9.6 Global Serializing and
Deserializing Utilities
5.9.6.1
Serializing
and Deserializing Primitive Values
Serializing primitive values is easy: the insertion operator is used to write the value and a terminator to the file stream. In most cases the extraction operator can be used to extract data from the file and into the provided reference parameter. For efficiency, the functions are made inline, which means they must be placed in obstream.h. For example:
inline void serialize(ObjectStream& os, const int x)
{
os << x << TERMINATOR;
}
inline void deserialize(ObjectStream& os, int& x)
{
os >> x;
}
Here we assume a macro defines TERMINATOR as a name for the newline character:
#define TERMINATOR '\n';
It's risky to deserialize characters using the extraction operator, because it skips over all white space characters, not just newline characters (the terminator). Our implementation only skips terminators. Because it contains an iteration, it would be unwise to make it an inline function:
void deserialize(ObjectStream& os, char& x)
{
do { os.get(x); }
while (os && x == TERMINATOR);
// skip newlines
}
5.9.6.2
Serializing
and Deserializing C Strings
When we serialize a C string, we also write its length to the object stream:
void serialize(ObjectStream& os, const char* x)
{
int n = strlen(x);
os << '(' << n <<
')';
for(int i = 0; i < n; i++)
os.put(x[i]);
os << TERMINATOR;
}
When a C string is deserialized, first its length is read from the file. The length is used to allocate enough memory to hold the string, then the characters are read into the array:
void deserialize(ObjectStream& os, char*& x)
{
int n; // = string length
char lparen, rparen; // storage for '('
and ')'
os >> lparen >> n >>
rparen;
x = new char[n + 1];
for(int i = 0; i < n; i++)
x[i] = os.get();
x[n] = 0; // add null terminator
}
5.9.6.3
Serializing
and Deserializing Pointers
We only provide pseudo code for serializing and deserializing pointers to persistent objects. (Note: pointers to anything else won't be serialized.) The algorithms follow the general strategy outlined earlier. The complete implementations are left as an exercise.
void serialize(ObjectStream& os, Persistent* x)
{
if (x is the null pointer?)
write 0 to os
else if (x already in saveTable?)
write associated OID to os
else
{
1. get type of *x
2. get OID of *x
3. update saveTable
4. write OID, type, & TERMINATOR
to os
5. serialize *x
}
}
void deserialize(ObjectStream& os, Persistent*& x)
{
1. read OID from os
if (OID == 0)
x = the null pointer
else if (OID already in loadTable)
x = associated pointer
else
{
2. read type from os
3. x = dynamically instantiate from
type
4. update loadTable
5. set OID of *x
6. deserialize *x
}
}
Our persistence framework will be combined with the application frameworks we will develop in Chapter 7.
5.10
Persistence
in MFC
Declaring a class to be persistent in MFC extends the mechanism used to declare a class to be dynamically instantiable, which was simply a matter of declaring the class to be derived from MFC's CObject base class, and placing calls to the DECLARE_DYNCREATE() and IMPLEMENT_DYNCREATE() macros at strategic points.
Let's modify the Address and Person classes from our previous example so that they work with MFC. Here are some of the include directives we will need at the top of our bus.h file:
// bus.h
#include <afx.h> // mfc framework
#include <iostream>
using namespace std;
As in our previous MFC example, we will also need to instruct the linker to link the MFC library with our project.
The Address class derives from MFC's CObject class, which plays the role of our Persistent class. The DECLARE_DYNCREATE() macro is replaced by another MFC macro, DECLARE_SERIAL(). Both serialization and deserialization are handled by a single function named Serialize() in MFC. The argument to this function is of type CArchive, an MFC class analogous to our ObjectStream class. Finally, we declare street, city, and state to be instances of MFC's CString class, which is analogous to the string class in the standard C++ library:
class Address: public CObject
{
public:
Address();
Address(int b, CString s, CString c,
CString st);
DECLARE_SERIAL(Address)
void Serialize(CArchive& ar);
friend ostream&
operator<<(ostream& os, Address& addr);
// etc.
private:
int bldg;
CString street, city, state;
};
The Person class follows the same pattern as the Address class. Note that as before, a person's address is simply a pointer to an Address object:
class Person: public CObject
{
public:
Person();
Person(CString nm , char gen, int a,
Address* addr);
DECLARE_SERIAL(Person)
void Serialize(CArchive& ar);
friend ostream&
operator<<(ostream& os, Person& per);
private:
CString name;
int age;
char gender; // 'M' = male, 'F' =
female, 'U' = unknown
Address* address;
};
At the top of bus.cpp, our implementation file, we place calls to MFC'sIMPLEMENT_SERIAL() macro:
// bus.cpp
#include "bus.h"
IMPLEMENT_SERIAL(Address, CObject, 1)
IMPLEMENT_SERIAL(Person, CObject, 1)
Unlike the IMPLEMENT_DYNCREATE() macro, the IMPLEMENT_SERIAL() macro has an additional integer parameter. This is the program version number. This prevents version 2 of the program from reading obsolete objects archived by version 1.
MFC's CArchive class is similar to our ObjectStream class. In particular, we can use the insertion and extraction operators to write and read to a CArchive. In addition, a flag accessed by the IsStoring() member function tells us if a CArchive object is open for reading or writing. We use this flag to determine if we are deserializing or serializing. Here's the implementation for Address::Serialize():
void Address::Serialize(CArchive& ar)
{
if (ar.IsStoring())
{
ar << bldg;
ar << street;
ar << city;
ar << state;
}
else
{
ar >> bldg;
ar >> street;
ar >> city;
ar >> state;
}
}
The implementation for Person::Serialize() follows the same pattern. Notice that memory for the object pointed at by the address field is automatically allocated:
void Person::Serialize(CArchive& ar)
{
if (ar.IsStoring())
{
ar << name;
ar << age;
ar << gender;
ar << address;
}
else
{
ar >> name;
ar >> age;
ar >> gender;
ar >> address; //
memory will be allocated
}
}
Our test harness, main(), begins by checking for a command line argument:
int main(int argc, char* argv[])
{
if (argc != 2)
{
cerr << "usage: "
<< argv[0] << " FILE\n";
return 1;
}
If present, the command line argument is construed as the name of a file. Creating a CArchive is a bit complicated. Forst we must create an MFC object of type CFile that represents the file:
UINT outFlags =
CFile::modeCreate | CFile::modeWrite |
CFile:: shareDenyNone;
CFile outFile(argv[1],
outFlags);
CArchive archive1(&outFile,
CArchive::store);
Next we create a few Address and Person objects:
Address a(123,
"Sesame St.", "New York City", "NY");
Address b(100, "Detroit
Ave.", "San Francisco", "CA");
Person p("Bill Jones", 'M',
62, &a);
Person q("Ed Smith", 'U', 39,
&b);
Person r("Sue Jones", 'F',
21, &a); // Sue & Bill are married
We print out the Person objects:
cout << p <<
endl;
cout << q << endl;
cout << r << endl;
Here's the output produced:
Mr. Bill Jones
123 Sesame St.
New York City, NY
(location = 0064FDB4)
Ed Smith
100 Detroit Ave.
San Francisco, CA
(location = 0064FDA0)
Ms. Sue Jones
123 Sesame St.
New York City, NY
(location = 0064FDB4)
Our Address printing function (implementation not shown) displays the memory location of its argument. As before, notice that Bill and Sue Jones contain pointers to the same Address object.
Next, the three Person objects are serialized in the archive, and the archive is closed:
p.Serialize(archive1);
q.Serialize(archive1);
r.Serialize(archive1);
archive1.Close();
In a separate test program or, in our case, later in the original test program (it doesn't matter which way), we create three new Person objects, but no Address objects:
Person p1, q1, r1;
A new archive is created from the same file name, argv[1]. This archive is open for loading:
UINT inFlags =
CFile::modeCreate | CFile::modeNoTruncate |
CFile::modeRead |
CFile:: shareDenyNone;
CFile inFile(argv[1], inFlags);
CArchive archive2(&inFile,
CArchive::load);
The contents of the archive are now deserialized into the new Person objects:
p1.Serialize(archive2);
q1.Serialize(archive2);
r1.Serialize(archive2);
The test program ends by printing the three new Person objects:
cout << p1 <<
endl;
cout << q1 << endl;
cout << r1 << endl;
archive2.Close();
return 0;
}
Here's the output produced. Notice that Bill and Sue Jones still share the same address, but its physical location in memory has changed:
Mr. Bill Jones
123 Sesame St.
New York City, NY
(location = 007718A0)
Ed Smith
100 Detroit Ave.
San Francisco, CA
(location = 00771BB0)
Ms. Sue Jones
123 Sesame St.
New York City, NY
(location = 007718A0)
5.11
Persistence
in Java
Java provides object output and input streams. Any object that implements Java's Serializable interface can be written to an object output stream and read from an object input stream:
class Address implements Serializable { ... }
class Person implements Serializable { ... }
The amusing thing is that the Serializable interface is empty:
interface Serializable {}
There's nothing for the programmer to implement! Thanks to reflection, once Java knows the class of an object, it can dynamically create an instance of that class. What's more, Java can learn the number and types of member variables the newly created object has. Java can use this information to automatically generate serialize() and deserialize() functions for the class.
5.12
Programming
Notes
5.12.1 Relational Databases
The most common type of databases are relational databases. Conceptually, a relational database is organized into tables or relations. The rows of a table, also called records, represent objects in some application domain class, the columns of a table represent attributes. For example, our school database might consist of three tables representing the classes Student, Teacher, and Course. Assume each student takes exactly three courses per term, and each teacher teaches exactly three courses per term:
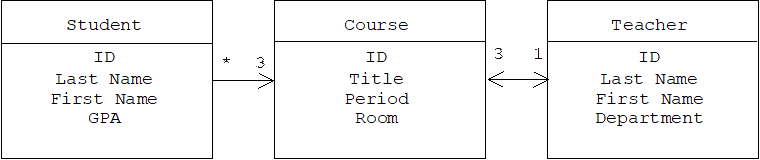
Rows in the student table represent students, columns represent student attributes such as identification number, last name, first name, grade point average, first period course, second period course, third period course, etc. An entry in a given row and column is called an attribute value:
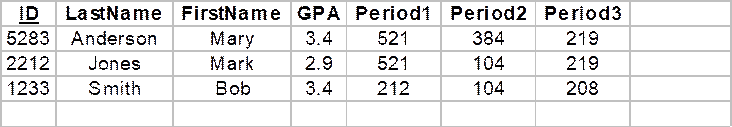
An attribute that is unique for each record is called a candidate key. For identification purposes there must be at least one candidate key for each table. In our example the ID attribute is a candidate key. One candidate key is selected as the primary key. The numbers in the "Period 1", "Period 2", and "Period 3" columns are foreign keys. A foreign key is a candidate key in another table. Foreign keys allow us to express links between records, hence associations between classes. In our example the foreign keys represent the ID numbers of courses in the Courses table:

The entries in the Instructor column are foreign keys that represent the ID numbers of teachers in the Teacher table:

5.12.1.1
SQL
Structured Query Language or SQL is the ISO standard language for defining and manipulating relational databases. The basic data manipulation commands are:
SELECT ... To query data in
a database
INSERT ... To insert rows into a table
UPDATE ... To update rows in a table
DELETE ... To delete rows from a table
Select is the most common command. Its basic format is:
SELECT column, column, ...
FROM table, table, ...
WHERE condition
For example, the query:
"What are the names of all students who have at least a 2.0 grade point averange and who take calculus during first period?"
can be expressed in SQL by:
SELECT LastName, FirstName
FROM Students
WHERE Period1.Title = "Calculus" AND 2.0 <= GPA
The result of executing a select command is a new table created from the tables listed in the FROM clause. The columns of the result table are those listed in the SELECT clause. The rows of the result table are those meeting the condition specified in the WHERE clause. If there is no WHERE clause, then no rows are filtered from the result table.
From the user's perspective, the result table appears to be one of the tables in the database, but in fact, the result table is often not explicitly stored in the database. Tables that are explicitly stored in the database are called base tables. Tables constructed from executing queries are called virtual tables or views. The tables listed in the FROM clause might be base tables or virtual tables.
5.12.1.2
Interfaces
to Relational Databases
Humans normally use browsers with graphical user interfaces to interactively query and update databases. But how do applications query and update databases? For example, how do browsers query and update databases? Many database management systems include an API (Application Programmer Interface). This is a library of functions that perform the most common types of database operations and that can be called from an application. Unfortunately, there is no ISO standard governing these APIs, so a program might need to be altered if the DBMS is changed. Open Database Connectivity (ODBC) is a standard RDBMS API being proposed by Microsoft. To implement ODBC, RDBMS vendors provide a driver in the form of a DLL (Dynamic Link Library) that interfaces with the RDBMS API and interprets ODBC function calls.
Another way DBMS vendor-dependency can be eliminated is by using embedded SQL. Embedded SQL allows programmers to embed SQL statements directly into their source code. Subsequently, a preprocessor replaces them with calls to vendor-specific API functions that directly access the RDBMS.
5.12.2 Object Oriented Databases and
ODMG 2.0
The correspondence between records in a relational database and C++ objects is not as close as one would hope. (For example, C++ concepts like pointer, member function, and derived class don't have obvious RDBMS counterparts.) The rows of a table must still be converted into objects, and this can be a lot of work for the programmer and the CPU. In fact, it has been estimated that as much as 30% of programming effort and code space is devoted to converting data from database or file formats into and out of program-internal formats such as objects [ATK]. The gap between database formats and program-internal formats is called impedance mismatch.
In contrast to relational databases, object databases are collections of objects organized into classes that are related by association and specialization. But what type of objects? C++ objects? Java objects? Smalltalk objects? If an object database contains C++ objects, then impedance mismatch is eliminated between the database and C++ client programs, but not between the database and Java or Smalltalk programs. To resolve this problem a consortium of companies has formed the Object Database Management Group[6] (ODMG) to define standards for object oriented database management systems (OODBMS). Version 2 of the standard (ODMG 2.0) appeared in 1997.
ODMG 2.0 includes specifications of an object model[7] (i.e., language-independent definitions of object oriented concepts such as object, class, inheritance, attribute, method, etc.); OQL, the Object Query Language (a language with SQL-like syntax for searching object oriented databases); and language bindings for C++, Java, and Smalltalk. GemStone, Itasca, Objectivity/DB, Object Store, Ontos, O2, PoetT, and Versant are examples of ODMG 2.0-compliant OODBMSs.
Using an object database[8], a C++ (or Java or Smalltalk) program may refer to objects without worrying if they are in main memory or secondary memory. If the requested object is in secondary memory, an object fault occurs, and the OODBMS transparently locates the requested object using the object's unique object identifier number (OID), translates the object into a C++ (or Java or Smalltalk) object, then loads the object into main memory. If the program updates an object (and commits to the update), the procedure is reversed: the ODBMS translates the C++ (or Java or Smalltalk) object into an ODMG object, then writes the translated object back to the database.[9]
5.12.3 The Transitive Closure of a
Class
Some authors define the transitive closure of class C, TC(C) as follows:
i. C is in TC(C).
ii. If C depends of class D, then TC(D) is a subset of TC(C).
C depends on D if:
C inherits from D or
C has a member variable of type D or
some C member function depends on D
D is a friend of C or
C depends on D*, D&, or a template instance T<D>
A C member function, f, can depend on class D in many ways:
f may have a class D parameter or
f may have a class D local variable or
f may create a class D object or
f may refer to a class D global variable
The size of the transitive closure of C, |TC(C)|, is a rough measure of its reusability. Obviously, a class with transitive dependencies on many other classes can only be reused in another program if the other classes in its transitive closure are imported into the program.
5.13
Problems
5.13.1 Problem
The UML meta-model is a class diagram that shows the relationships between the following concepts: class, method, attribute, association, role, generalization, aggregation, and composition. Draw this class diagram. Be sure to include each of the items listed above as a class. also show any attributes and operations you can think of for these classes.
5.13.2 Problem
What would be the output produced by the following Java code:
Class c1 = Class.forName("Class");
c1 = c1.getClass();
System.out.println("c1 = " + c1.getName());
c1 = c1.getSuperClass();
System.out.println("now c1 = " + c1.getName());
5.13.3 Problem
Complete the definitions of the Product class and its three subclasses (Product1, Product2, and Product3) that were sketched in our demonstration of the Prototype Pattern. Test your implementations using the test program given.
5.13.4 Problem
Complete the Persistence Framework. Test your implementation by completing the test program described earlier (i.e., bus.h, bus.cpp, and main.cpp).
5.13.5 Problem
Copy the trick used to serialize and deserialize C strings to implement serialize() and deserialize() functions for pointers to integer, bool, and double arrays. Of course the length of the array will have to be supplied as a parameter to serialize().
void serialize(ObjectStream& os, const int* x, int len = 1) {
??? }
void deserialize(ObjectStream& os, int*& x) { ??? }
// etc.
By using 1 as a default argument, these functions can be used to serialize and deserialize pointers to single variables.
Why must the second parameter of the deserialize() function be a reference to a pointer? Isn't it enough simply to pass a pointer? Create template functions that serialize and deserialize arrays:
template <typename Data>
void serialize(ObjectStream& os, const Data x[], int n);
template <typename Data>
void deserialize(ObjectStream& os, Data x[]);
5.13.6 Problem: Serializing and
Deserializing C++ Strings
Provide functions for serializing and deserializing C++ strings:
void serialize(ObjectStream& os, string x) { ??? }
void deserialize(ObjectStream& os, string& x) { ??? }
5.13.7 Problem: Serializing and
Deserializing Vectors
Provide function templates for serializing and deserializing STL vectors:
template <typename Data>
void serialize(ObjectStream& os, const vector<Data> x) { ??? }
template <typename Data>
void deserialize(ObjectStream& os, vector<Data>& x) { ??? }
5.13.8 Problem
Although the pointers to the Address objects retained their OIDs after deserialization, the Person objects got new OIDs when they were deserialized. How could we guarantee that all objects retain their original OIDs?
5.13.9 Problem
In the writer part of the test harness for our object stream framework, three Person objects were created: Bill (OID = 505), Ed (OID = 506), and Sue (OID = 507), and two Address objects were created: New York (OID = 503) and San Francisco (OID = 504). But the framework initialized Persistent::nextOID to 500. What happened to OIDs 501 and 502?
5.13.10 Problem
How would you force the function:
void hello()
{
cout << "Hello, World\n";
// no return value!
}
to be executed before main() without altering it?
5.13.11 Problem
Our Persistence Framework produces object streams. An object stream is a sequence of serialized values representing persistent objects, pointers to persistent objects, integers, floats, characters, Booleans, and strings. Since serialized values are strings, it makes sense to describe the structure of an object stream using an EBNF grammar. Here is how such a grammar might begin:
OBSTREAM ::= SERIALIZED*
SERIALIZED ::=
PERSISTENT | POINTER | INT | FLOAT |
CHAR | BOOL | STRING
Complete this grammar.
5.13.12 Problem
Programmers can decouple their applications from the persistent storage interface by using the Persistent Data manager pattern:
Persistent Data Manager
[ROG]
Problem
Changes to the database can propagate to the rest of the application if there are numerous places in our program where objects are serialized and deserialized.
Solution
A persistent data manager serves as the interfaces with the database system and the rest of the application.
Static Structure

A data manager encapsulates an object stream or database connection (in this problem we will use object streams). A data manager also maintains a list of all persistent objects that are currently in memory (possibly excluding itself).
When a user wants to create a new persistent object, he must use the makePersistent() factory method provided by the data manager, which expects the name of a class derived from Persistent as its argument. For example, assume the following declarations have been made:
DataManager dm("objects");
class Boat: public Persistent { ... };
Here's how a new boat object is created:
Boat* p = dm.makePersistent("Boat");
Removing the object from memory is done using the deletePersistent() member function:
dm.deletePersistent(p);
All persistent objects can be serialized into the object stream encapsulated by the data manager by simply calling the saveAll() member function:
dm.saveAll();
Objects can be read from the stream using the restoreAll() member function:
dm.restoreAll();
We can print a list of the OID's and types of all persistent objects by inserting the data manager into an output stream:
cout << dm << endl;
Build and test a reusable data manager.