Outline
- Effectiveness Measures
- Building a Test Collection
- In-Class Exercise
- Efficiency Measures
- Punctuation and Capitalization
- Stemming
Measuring Retrieval Effectiveness
- Measuring the effectiveness of a retrieval method depends on human assessments of relevance.
- TREC experiments often use binary relevance judgements by humans. i.e., someone says, document X is or is not relevant
to the topic A.
- A document is typically judged relevant if any part of it is relevant.
- For example, for TREC topic 426, a user might formulate the Boolean query:
(("law" AND "enforcement") OR "police") AND ("dog" OR "dogs").
- Using the TREC45, (disk 4 and disk 5 of a TREC dataset of newspaper articles), this query produces 881 documents of the 500,000 or so in the collection.
Recall and Precision
- In order to determine the effectiveness of a Boolean Query, we compare (1) the set of documents returned by the query, Res, and (2) the set of relevant documents for the topic contained in the collection, Rel.
- From these two sets we can compute two common standard measures of effectiveness, recall and precision.
`mbox(recall) = frac(|Rel cap Res|)(|Rel|)`
`mbox(precision) = frac(|Rel cap Res|)(|Res|)`
- Recall indicates the fraction of relevant documents that appear in the result set, precision indicates the fraction of the result set that is relevant.
- According to NIST there are `202` relevant documents for topic 426. The above Boolean query only returns `167` of these. So the precision is `0.190`, and the recall is `0.827`.
F-measures
- Sometimes recall and precision are combined into one number known as an F-measure.
- The simplest F-measure, the `F_1`-measure, takes the harmonic mean of recall and precision:
`F_1 = frac(2)(frac(1)(R) + frac(1)(P)) = frac(2 cdot R cdot P)(R+P)`.
- Unlike, the arithmetic mean `frac(R+P)(2)`, the harmonic mean enforces a balance between precision and recall.
- For example, we return the whole data set in response to a query.
- The recall will be 1 and for a large data set the precision will be close to 0, so the arithmetic mean will be about 0.5.
- In constrast, the harmonic mean gives a value of `frac(2P)(1+P)` which will be close `0`.
- A common generalization of the `F_1`-measure is the weighted measure:
`F_(beta) = frac((beta^2 + 1) cdot R cdot P)(beta^2 cdot R + P)`
- Notice if `beta = 1` this corresponds to the harmonic mean, if `beta = 0` one gets just the recall, and if `beta = infty` one gets just the precision.
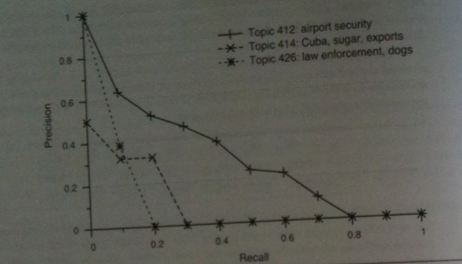
Measures for the first `k` results
- For an ordered set `X`, we use `X[1..k]` to denote its first `k` elements.
- Often for search, we are interested in the first 10, 20, 50, or 100 results.
- We can modify precision and recall to the first `k` results as:
`mbox(recall@k) = frac(|Rel cap Res[1..k]|)(|Rel|)`
`mbox(precision@k) = frac(|Rel cap Res[1..k]|)(|Res[1..k]|)`
- We write `mbox(P@k)` for `mbox(precision@k)`.
- By definition, `mbox(recall@k)` will increase with `k`. On the other hand, `mbox(P@k)` will tend to decrease with `k`.
- An IR experiment typically looks at `k` over a range of values to try to find out how `mbox(recall@k)` and `mbox(P@k)`
trade-off against each other. One may then make a recall-precision plot.
- In such a plot, one puts the on x-axis, the recall values between 0 and 100%. Given such a recall value x, we look for the maximum
precision achieved at this recall value or higher (this is called interpolated precision).
Average Precision
- It is also possible to compute an average precision across the full range of recall values:
`frac(1)(|Rel|)cdot sum_(i=1)^(k) (mbox(relevant)(i) times mbox(P@i))`
Here `mbox(relevant)(i)` is 1 if the `i`th result is relevant and `0` otherwise.
- This roughly represents the area under a non-interpolated recall-precision curve.
- Choosing `k` larger than the index of the last relevant result does not change the value of average precision.
- To get one number for how the IR system performs across a range of topics, one typically takes the arithmetic mean of
the average precision of the system for each topic.
- This number is called the mean average precision or MAP.
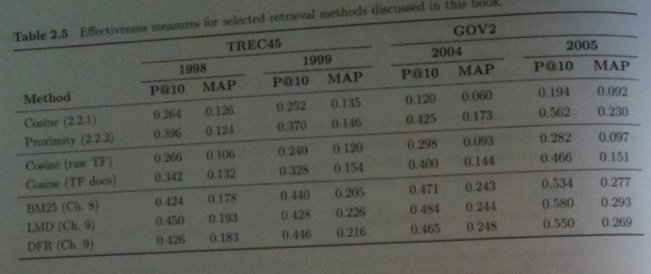
- The most common measures to give when trying to present the effectiveness of your IR system are to give its
average `mbox(P@10)` across topics and to give its MAP score. The former is more intuitive, the latter probably better means the complete performance of the IR system.
- The above images of a table from the book gives some `mbox(P@10)` and MAP scores for the TREC45 and GOV2 data sets for some of the ranking methods we will consider this semester.
- We will talk about BM25, LMD (language modeling), DFR (divergence from randomness) later in the semester.
- Usually one doesn't compute such scores by hand, but instead uses some piece of well-tested software such as trec_eval.
In-Class Exercise
- Consider the query "mean person behaviour".
- Spend a moment and write down why you might enter such a query into a search engine.
- Pick a search engine. Using what you wrote above as your metric to judge relevance, compute the
P@10.
- Think up some way you could estimate |Rel| and write that down.
- Post your results to the Sep 18 In-Class Exercise Thread on the discussion board.
Building a Test Collection
- In a simple set-up, given a topic we go through each document in our collection and either score it as 1 relevant or 0 not.
- At 10 seconds/document, for the 0.5 million document TREC45 collection, this would take about a year for one person to judge one topic.
- For the 25 million document GOV2 collection, someone would have to spend the whole career to just judge one topic.
- TREC instead typically uses a system of pooling:
- One or more experimental runs from each group participating in an adhoc task is accepted.
- Each run consists of the top 1000 or 10,000 documents for each topic.
- The top 100 or so from each run are then pooled for that topic.
- These are then presented to assessors in random order for judging. This takes about a week.
- One group might rank a document 50 and another group 150, if its in the top 100 for any group it will be judged. This
is called the pool depth.
- Unjudged documents are treated as not relevant.
- `mbox(P@10)`, `mbox(recall@k)`, and MAP scores are then calculated.
Efficiency Measures
- In addition to evaluating a system's retrieval effectiveness, one also wants to evaluate how efficiently it returns results.
- That is, things like the cost of running the system, and how quickly it gets results to its users.
- User's are typically interested in response time, the time between entering the query and receiving results.
- Another important measure is the throughput, the average number of queries processed in a given amount of time.
- Typically, response time is measured by taking a measure of the OS time before executing a set of queries, executing those queries, and then measuring the time again. An average is then taken over the number of queries in the set to give the average response time.
Token and Terms
- So far we have viewed tokens as sequences of alphanumeric text separated by nonalphanumeric text.
- We have further case normalized these tokens by converting each of their letters to lower case.
- We have also treated XML tags as tokens.
- In practice, more complex tokenization is usually done.
- For example, under the above scheme "didn't" would be two tokens "didn" and "t" and neither would match "did" "not".
- 10, 000, 000 would be three tokens and would not match 10000000, but might match "10".
- UTF-8 characters of other languages are ignored.
- For the next couple of days, we will examine some of these issues in detail.
Punctuation and Capitalization
- We've already mentioned that apostrophes can cause problems. For contractions it might make sense to tokenize them as separate words. For instance, "did" "not" for "didn't".
- For other uses, of apostrophe such as in possessives it might makes sense to tokenize things like "Bill's" as "bill" and "bill's", the latter with the apostrophe as part of token.
- Periods usually end sentences, and for such occurrences can be safely dropped. However, they also appear in acronyms such as "I.B.M." and somehow this token should map to the same things as "IBM".
- If we case normalize some acronyms such as "US" we lose their meaning.
- Sometimes text is written in ALL CAPS which could further confuse the issue.
- We also don't want to drop the special characters from some terms; otherwise, one has things like "C#" and "C++" become "C".
- Typically, the solution to these problems is a rule based approach, and each rule in the system would be need to be evaluated for its impact on results.
Stemming
- Stemming allows a query term such as "orienteering" to match an occurrence of "orienteers" or "runs" to match "running".
- Stemming thus considers the morphology or internal structure of terms, where the goal for an IR system is to reduce each term to its root form.
- The program/function that does this is called a stemmer.
- A related concept from linguistics is lemmatization.
- This is the process whereby a term is reduced to a lexeme, which roughly corresponds to a word in the sense of a dictionary entry.
- For each lexeme a particular form of the word, or a lemma, is chosen to represent it. For example, "run" for "running" and "ran".
- One common stemmer is the Porter Stemmer developed by Martin Porter in the 1970s. This has been ported to many languages. His website also has stemmers for other languages.










