










Enterprise Search, Data Governance, Big Data
CS257
Chris Pollett
Nov 30, 2020
CS257
Chris Pollett
Nov 30, 2020
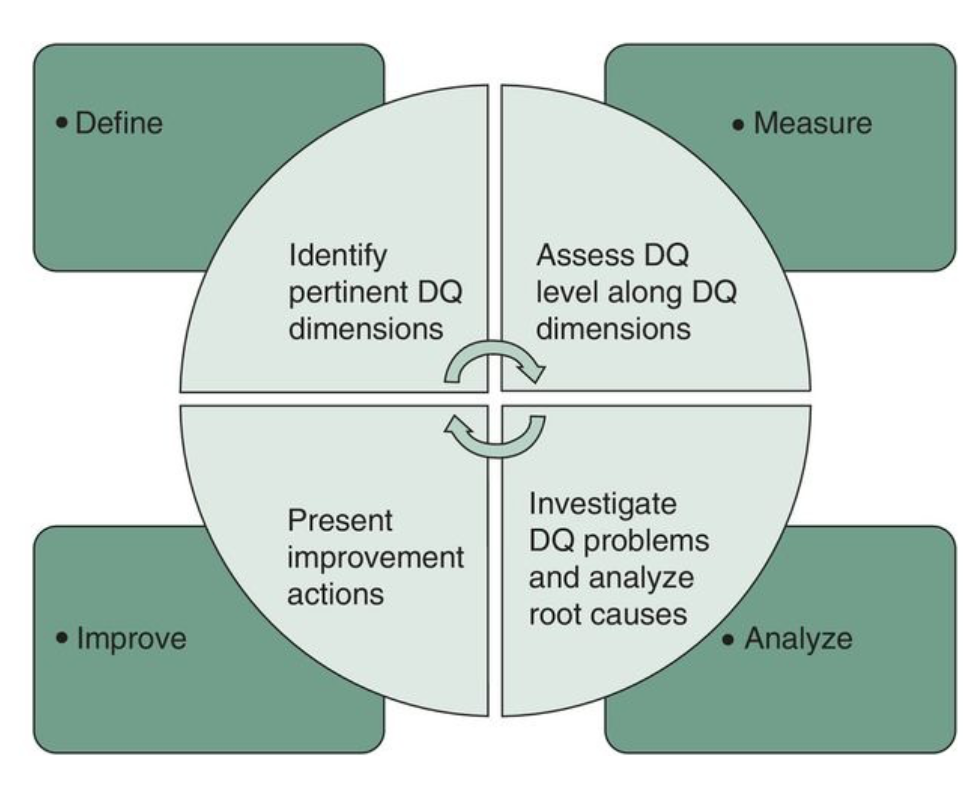
Which of the following is true?
brew install hadoopto install Hadoop on my laptop.
hadoop some-command argsFor example, if some command is jar then it runs the map-reduce job given by the arguments.
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount
{
/* This inner class is used for our Map job
First two params to Mapper are types of KeyIn ValueIn
last two are types of KeyOut, ValueOut
*/
public static class WCMapper extends Mapper<Object,Text,Text,IntWritable>
{
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException
{
// normalize document case, get rid of non word chars
String document = value.toString().toLowerCase()
.replaceAll("[^a-z\\s]", "");
String[] words = document.split(" ");
for (String word : words) {
Text textWord = new Text(word);
IntWritable one = new IntWritable(1);
context.write(textWord, one);
}
}
}
/* This inner class is used for our Reducer job
First two params to Reducer are types of KeyIn ValueIn
last two are types of KeyOut, ValueOut
*/
public static class WCReducer extends Reducer<Text, IntWritable,
Text, IntWritable>
{
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException
{
int sum = 0;
IntWritable result = new IntWritable();
for (IntWritable val: values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main (String[] args) throws Exception
{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "wordcount");
job.setJarByClass(WordCount.class);
job.setMapperClass(WCMapper.class);
job.setReducerClass(WCReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
TextInputFormat.addInputPath(job, new Path(args[0]));
Path outputDir = new Path(args[1]);
FileOutputFormat.setOutputPath(job, outputDir);
FileSystem fs = FileSystem.get(conf);
fs.delete(outputDir, true);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
javac -classpath `yarn classpath` -d . WordCount.java
jar -cf WordCount.jar WordCount.class 'WordCount$WCMapper.class' 'WordCount$WCReducer.class'
hadoop jar WordCount.jar WordCount /Users/cpollett/tmp.txt /Users/cpollett/output
hadoop fs -ls /Users/cpollett/output/
hadoop fs -cat /Users/cpollett/output/part-r-00000
2018-12-05 11:28:01,201 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 1 foo 2 la 3
start-hbase.sh
hbase shell
//Making a table user with columns name and email
// In general, columns have the format
// families:qualifiers such as name:first, name:last
create 'users', 'name', 'email'
//list the tables we have in our system
list
// or for a particular
list 'users'
// to see details about how the table is contructed one can do:
describe 'users'
//To add data to a column of a particular user, I could do
put 'users', 'seppe', 'name:last', 'vanden Broucke'
//or
put 'users', 'seppe', 'email', 'seppe.vandenbroucke@kuleuven.be'
// To see what's stored I can do:
get 'users', 'seppe'
// To delete some column info can do:
delete 'users', 'seppe', 'name:first'
// hbase supports versioning so can have expression like:
alter 'users', {NAME => 'email', VERSIONS => 3}
get 'users', 'seppe', {COLUMNS => ['email'], VERSIONS => 2}
// To get rid of everything related to a particular row can do:
deleteall 'users', 'seppe'
//to get rid of a table
disable 'users'
drop 'users'
lines = spark.textFile("hdfs://...")
errors = lines.filter(_.startsWith("ERROR"))
errors.persist() // make the errors available in RAM
errors.count()
// find MySQL errors
errors.filter(_.contains("MySQL")).count()
// Return the time fields of errors mentioning
// HDFS as an array (assuming time is field
// number 3 in a tab-separated format):
errors.filter(_.contains("HDFS"))
.map(_.split('\t')(3))
.collect()