Enterprise Storage, Business Continuity, Data Warehousing
CS257
Chris Pollett
Nov 4, 2020
Outline
Enterprise Storage Subsystem Classification
Business Continuity
In-Class Exercise
Data Warehousing
Enterprise Storage Subsystems
These systems arise because it is often the case that the cost of managing storage hardware is greater than the cost of the hardware itself.
There is also a trend away from purely centralized data centers to more distributed architectures which can be centrally managed.
Being distributed, Enterprise Storage Subsystems often involve networked storage connected to high-end servers by means of fast interconnects.
So some goals of these systems are:
accommodate for high performance data storage;
cater for scalability, and in particular independent scaling of storage capacity and server capacity;
support data distribution and location transparency;
support interoperability and data sharing between heterogeneous systems
and users;
reliability and near continuous availability;
protection against hardware and software malfunctions and data loss, as well as abusive users and hackers;
improve manageability and reduce management cost through centralized management of storage facilities, which may themselves be distributed.
Classifying Enterprise Storage Systems
Enterprise Storage subsystem are typically classified by:
connectivity - how storage devices are connected to processors/server:
Direct attach refers to storage devices with a one-to-one connection between server and storage device.
Network attach refers to storage devices in a many-to-many connection with the corresponding servers by means of network technology.
medium - refers to the physical cabling and low-level protocol used to realize connectivety. Examples include:
SCSI (Small Computer Systems Interface): This tends to be higher performance than Serial Advanced Tecnology Atatcment (SATA) used in consumer devices. SCSI defines both a command set protocol for commmunication over a cable and a low-level protocol and cabling. The latter corresponds to the medium.
Ethernet This is a well-established common standard medium for local area networks.
Fibre Cannel (FC) This is a newer medium, developed specifically to connect high-end storage systems to servers. It was originally deployed over optical fiber but can be used over copper.
I/O protocol This refers to the command set to communicate with the storage device and protocols are usually classified as either:
block-level - requests and responses are for storage blocks. Example: SCSI I/O.
file-level - requests and responses are for whole files. Examples: NFS (Netowrk File System), CIFS (Common Internet File System) (aka SMB - Server Message Block).
Examples of Enterprise Storage With Respect to these Classifications
DAS stands for Direct Attached Storage and consists of hard drives, SSD, or tape directly connected to a server, typically via a SCSI cable, using SCSI I/O commands.
SAN stands for Storage Area Network. It uses a collection of storage devices connected to a dedicated network which is connected in an any-to-any fashion to a collection of servers. It typically uses fibre channel which is faster for backups than similar communication over a LAN.
NAS stands for Network Attached Storage. It consists of a device attached to a LAN that has an integrated minimal processor, OS, and a set of hard drives. It is typically cheaper than a full blown server. It usually supports some file level I/O protocol such as SIFS, NFS, FTP, or HTTP.
NAS Gateway device is similar to a NAS device except rather than containing the hard drives, external hard drives are connected to it.
iSCSI stands for internet SCSI. It is also known as storage over IP. It involves a set-up similar to a SAN but instead of using Fibre Channel, Ethernet is used as the medium. SCSI block-level I/O commands are sent over a TCP/IP network.
Business Continuity
Business Continuity is an organization's ability to guarantee its uninterrupted functioning, despite possible planned or unplanned down time of the hardware and software supporting its database functionality.
A contingency plan is used by a business to quantify recovery objectives for a particular kind of down time such as backups, maintenance, upgrades, software or hardware malfunctions, hhuman or natural disasters, etc.
Quantification may be done by making:
recovery time objectives (RTOs) (i.e., setting an amount of down time before the system needs to be back running). This can be affected by how fast can get data back from back up.
recovery point objectives (RPOs) (i.e., setting the degree to which data loss is acceptable after a calamity). This can be affected by the amount of redundancy in the system and frequency of backups.
Different organizations have different tolerances for RTOs and RPOs. For example, a weather observatory might emphasize RTO over RPO, so as to start reporting weather data again, but a school might be more tolerant on RTO to achieve a lower RPO (don't lose anyones grades).
One key point in a contingency plan is to determine points of failure: for a database this might be: availability and accessibility of storage devices, availability of database functionality, and availibility of data themselves.
The idea in coming up with a plan is to ensure there is a level of reduncancy for each point of failure so that one failure for that category doesn't take the system down (single point of failure).
Business Continuity with Respect to Databases
Availability and accessibility of storage devices can be achieved by using the RAID techniques we discussed last day. Choice of RAID level and number of storage devices can affect achievability of RTOs and RPOs.
For availability of database functionality, we can take a variety of approaches such as:
manual failover - have a spare server around to manually launch in case that usual server dies.
Using a cluster - where we have some kind of reduncancy in the nodes so in case one fails we can automatically serve the result from a different node. For clusters with redundancy, we can reduce planned downtime by using rolling upgrades.
Availibility of data can be had by various methods such as:
tape backup
hard disk backup
electronic vaulting (storing backups to safe additional locations)
Replication and Mirroring of Data
Using a dedicated seperate network to restore data from backups for disaster tolerance
Transaction Recovery (via logging)
In-Class Exercise
Suppose we are using RAID level 5 with 5 hard drives where the mean time to failure of a hard drive is 10 years.
Suppose we have an RTO for a disk failure of 5 hours.
Give concrete parameters about the hard drives and their connections that this might affect.
What is the effect of this RTO on the RPO of mean time to data loss? I.e., compute the mean time to data loss.
In considering DBMS, one usually start by considering what is the best way to store data that needs to be stored for the day to day operation of some business.
Given that we have stored this data, it is natural to ask how it can be used from a business perspective and allow corporations to make decisions.
For these kinds of decisions it often convenient to reorganize the data for the purposes of analytics.
A data warehouse (Inmon 1996) is a subject-oriented (focused say on customers rather than transactions), integrated (all sources in the company), time-variant (time series data), and nonvolatile collection (once in system read-only) of data in support of management's decision-making process.
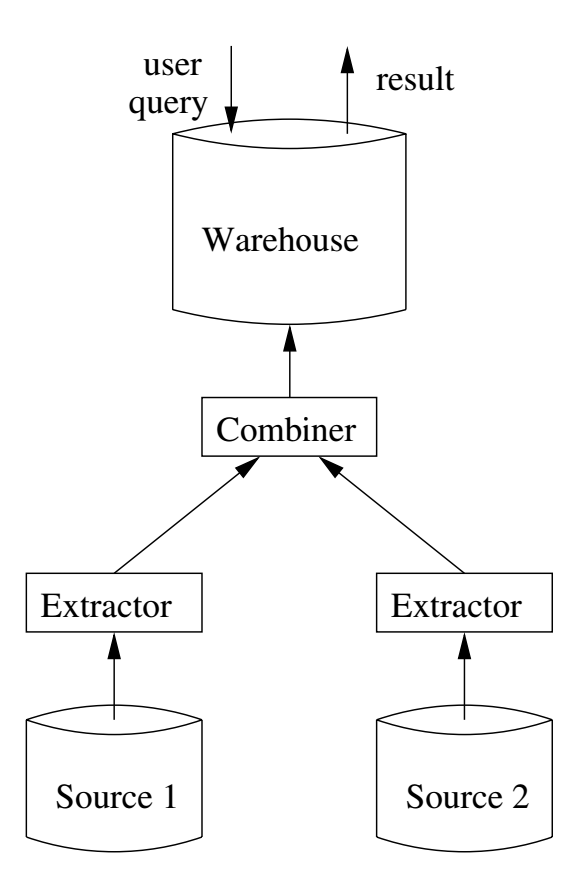
In a data warehouse, data from several sources are extracted, combined, and inserted into a single global schema.
Once the data is in the warehouse, it can be queried by a user in exactly the same way as any database.
Two common approaches to constructing a warehouse are:
Close the warehouse periodically, reconstruct the warehouse from the current data sources. This is perhaps the easiest and most common approach, and might be done once a night.
Update the warehouse periodically based on changes since the last update. This is called incremental updating. This typically involves communicating less data. The drawback is computing the change in the data can be complex, especially if there are several sources.
Online Analytical Processing
OLAP (Online Analytical processing) is the examination of data in a database for patterns or trends.
It generally involves complex queries (called decision support queries) that use one or more aggregations.
These queries might only return a small number of rows in their results, but touch every row in a table or collection tables.
On the other hand, the transactions we have mainly been considering this semester only touch a few rows at a time. The study of these short transactions is called OLTP (Online Transaction Processing).
OLAP applications often take place in a data warehouse which is either a separate copy of a master database or which is a collection of materialized views calculated from several data sources.
Having a separate, periodically updated data warehouse, allows the OLAP system to run long queries which might have difficulty running in the presence of shorter transactions.
Example OLAP Application
Aardvark Automobile Co might build a data warehouse to analyze the sales of its cars.
An example decision support query might examines sales on or after April 1, 2006 to see how the average price per vehicle varies by state:
SELECT state, AVG(price)
FROM Sales, Dealers
WHERE Sales.dealer = Dealers.name
AND date >= '2006-1-04';
This this query touches much of the database.
A typical OLTP query might be "find the price at which the auto with serial number 123 was sold." This query only touches one row.
Multi Dimensional View of OLAP data
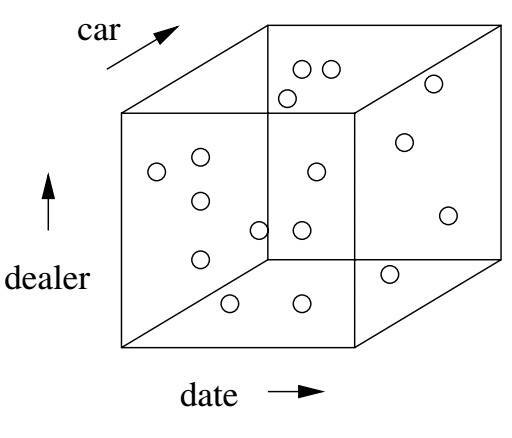
Many OLAP applications make use of a fact table, a central relation or collection of data.
A fact table represents events or objects of interest, for example, sales.
We can think of this fact table as being arranged in multidimensional space as a "cube" or "hyper-cube".
For example, in the above picture, each point represents a sale and its position in the cube is determined by which dealer, what date, and what kind of car.
The data space above is often referred to as the raw data cube.
To facilitate decision support queries, this cube is often augmented to make a formal data cube by adding:
Aggregates of the data in all subsets of dimensions, as well as the data itself.
Points in the formal cube may represent an initial aggregation of points in the raw-data cube. For example, instead of the "car" dimension representing each individual car, that dimension might be aggregated by model only.
Approaches to OLAP
The distinction between raw-data cube and formal data cube shows up in the two common approaches to making system that support OLAP:
ROLAP, or Relational OLAP. In this approach data is stored in relations with a specialized structure called a "star schema". One of these relations is a "fact table" which contains the raw, unaggregated data corresponding to the raw-data cube. Other relations give info about the values along each dimension.
MOLAP, or Multidimensional OLAP. In this set-up, a specialized structure corresponding to the formal data cube is used to hold the data, including aggregates. Nonrelational operators may be implemented to support queries on this structure.