On Monday, we reviewed database development going as a three staged process from conceptual design to logical design to physical design and then
to how the data is actually internally represented.
We said we were going to look at some aspects of this internal representation this week.
We then looked at record formats, and techniques for organizing records into files.
In particular, we looked at primary file organization methods of heap files, sequential files, and random files.
Today, we begin by looking at another file organization method known as indexed sequential files.
Indexed Sequential File Organization
Random Access files are good for retrieving/updating/inserting records by search key value, but are not good for retrieving records according to a certain order.
For example, find all employees whose last name begin with Mac in ascending alphabetical order.
Sequential files are good at this task provided that the ordering is the ordering that was used to store the data.
They are slower though for operations like retrieving/updating/inserting records by search key value.
Indexed sequential file organization tries to improve sequential file performance by combining sequential file organization with the use of one or more indexes.
To do this, the file is split into different intervals or partitions.
Each interval is represented by an index entry in a index file which contains the search key value of the first record in the interval as well as either a block pointer or record pointer (block pointer, record offset pair) of the interval.
With an indexed sequential file organization, both sequential access based on the physical order of the records and random access based on the index are supported.
ISAM
One early example of an indexed sequential file format was IBM's ISAM (Indexed Sequential Access Model) format developed for the IMS database system as part of the Apollo program in 1966.
The basic idea of ISAM was to organize the data records in a sequential file according to key.
On top of this we have a two level index: the top layer being a sparse index on (key,cylinder), then beneath this, for a particular cylinder, we would have an index on (key, block) that would map into the sequential file.
Descendents of ISAM include the MyISAM storage format that was the original default storage engine for MySQL (it now uses InnoDB).
You can still create files with this format using a syntax like:
CREATE TABLE TEST(I INT) ENGINE = MYISAM;
MyISAM tables are stored in three files that begin with the table name:
A .frm file gives the schema format for the table
A .MYD file holds the actual data as a sequential file.
A .MYI is used to store an index into the data file.
InnoDB simplifies tables to two files: a .frm and a .idb file, with the latter having the data.
Basic Indexes
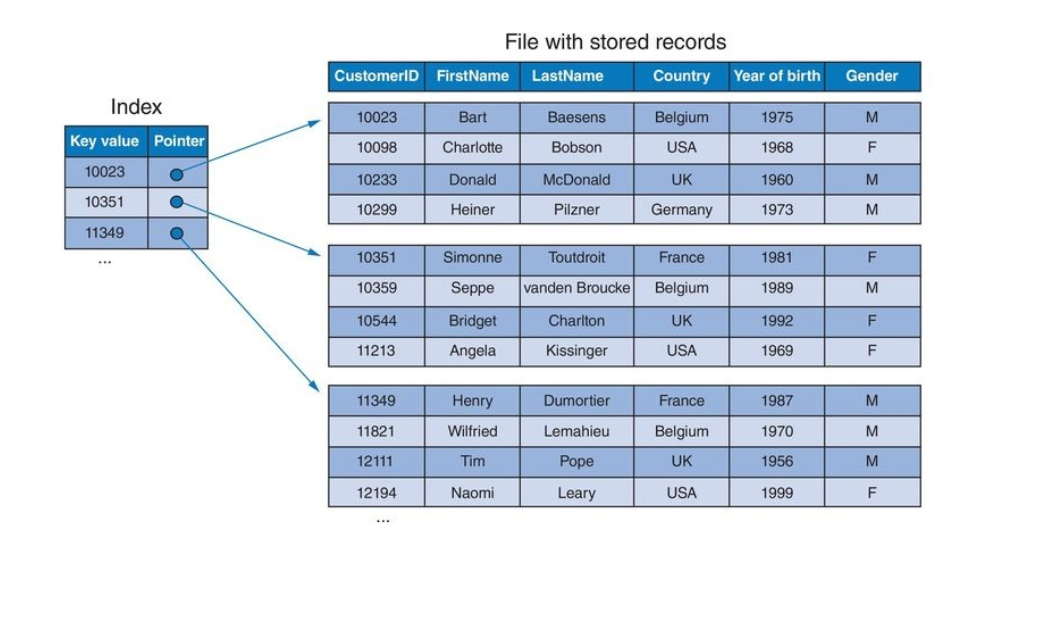
An index file is a file containing (index key, pointer) pairs as records.
An index key usually consists of one or more column values that are found in the relation, and the pointer points to a record which has those column values.
A given relation might have several index files.
Since an index file only has two presumably small columns it will typically be much smaller and faster to search such than a data file.
We now look at some different ways of characterizing indexes:
A dense index is an index where we have one index entry per record:
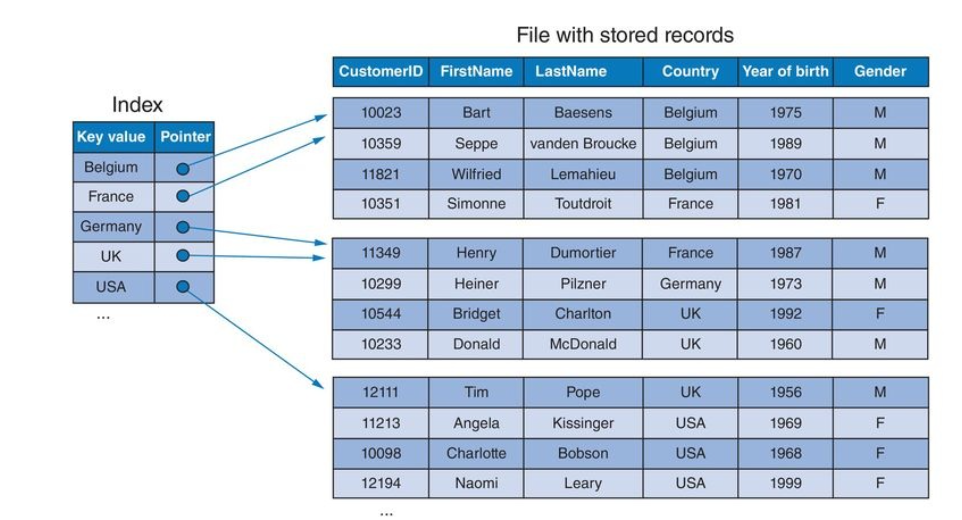
A sparse index is an index where we have one entry per block of the original file:
In-Class Exercise
Suppose `R` had 1,000,000 tuples and 5 fit into a block of 4096 bytes.
How many blocks and bytes does R take to store?
If the key is 20 bytes long and the record pointer 8 bytes long, approximately how many index records can fit in a block?
If we have a dense index on `R`, how many blocks and bytes would the index file take?
If we use binary search to do look ups how many block accesses would we need with and without the index?
A primary index file organization organizes a data file on a unique key and an index is defined over the unique key.
Notice this organization is more general than indexed sequential file organization in that the underlying data might be a heap or random access file.
In the case were we are using a sequential data file, this index can be sparse:
A clustered index file organization organizes a data file on a non-key attribute. As the searc key is non-unique we might get several pointers to the same block,
and we might skip blocks of the underlying file:
Since a sparse index itself can still take several blocks, one could imagine using a sparse index on a sparse index to look up the data.
Set-ups with indexes on top of other indexes are called multi-level indexes.
Multi-level indexes are fast, but can be a pain to update.
List Data Organization
A list is an ordered set of elements.
If each such element has exactly one successor, except for the last element, we call it a linear list; otherwise, is called a nonlinear list.
For example, (a,b,c) is a linear list (a, (b,c), d) is not because a as b and c as successors.
Lists can be used to represent sequential and tree data structures.
Ordering can be represented by either physical contiguity or by means of pointers.
Types of Linear Lists
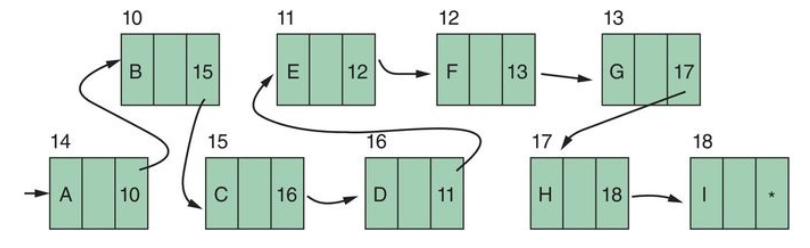
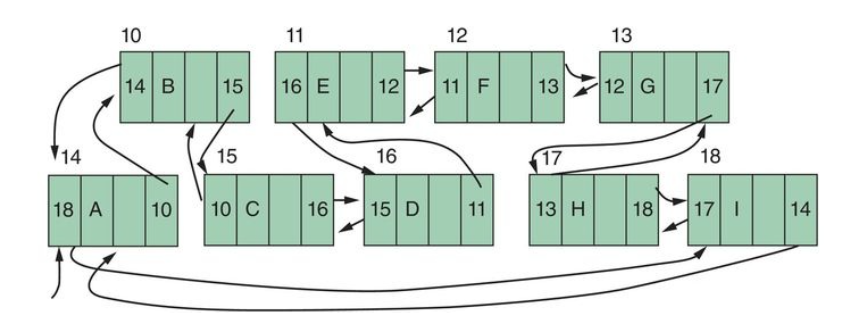
If a linear list's ordering is represented by physical contiguity we get a sequential file, if it is represented by pointers we get a linked list.
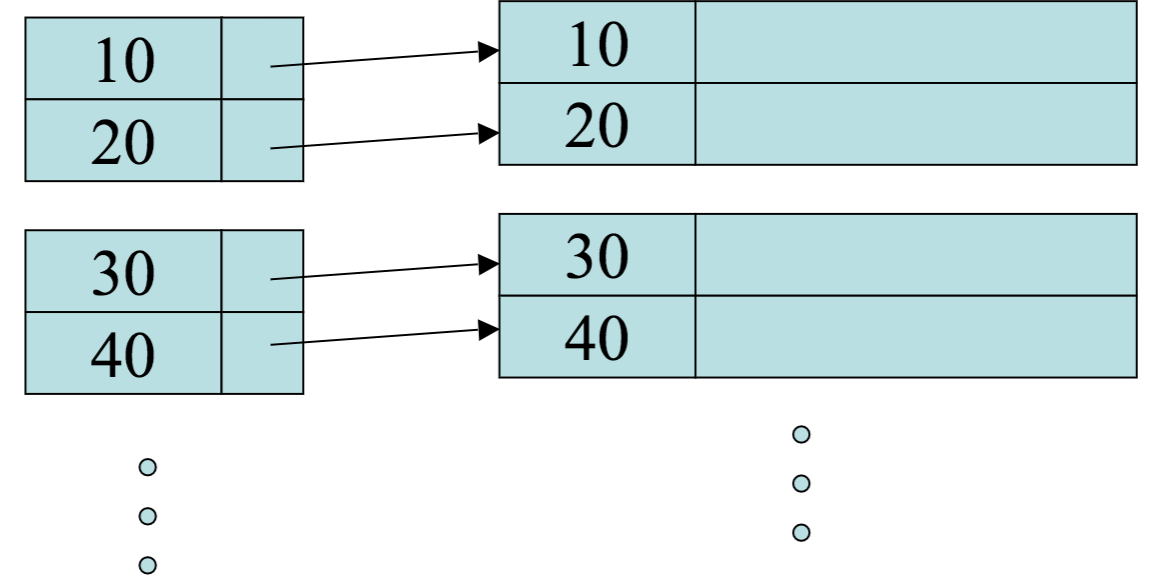
A linked list with only next pointers is (* used to indicate end of list) a one-way linked list:
A linked list with next and previous pointers is (* used to indicate end of list) a two-way linked list:
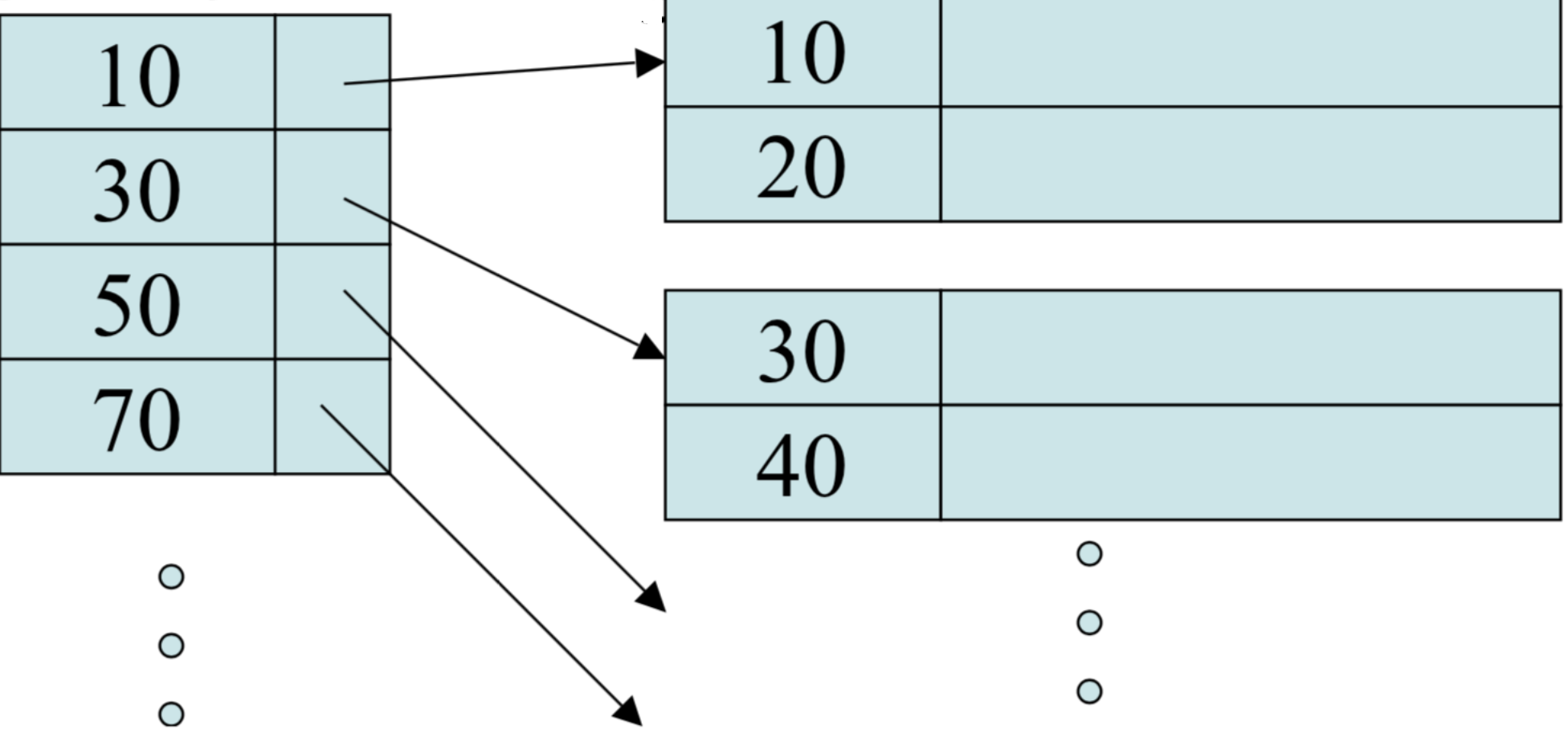
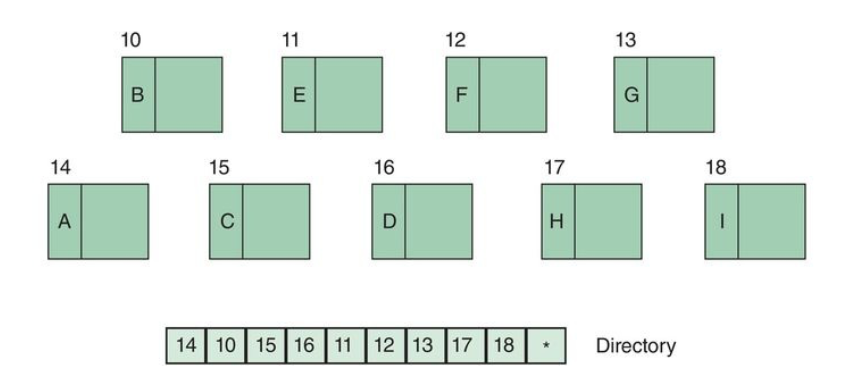
Rather than store all the links in the records themselves we can store the pointers in a separate file called a directory:
Tree Data Structures
Recall a tree is a set of nodes and edges with the following properties:
There is exactly one root node.
Every node, except for the root, has exactly one parent node.
Every node has zero, one, or more children or child nodes.
Nodes with the same parent node are called siblings.
All children, children-of-children, etc. of a node are called the node's descendants.
A node without children is called a leaf node.
The tree structure consisting of a non-root node and all of its descendants is called a subtree of the original tree.
The nodes are distributed in levels, representing the distance from the root.
The root node has level 0; the level of a child node is equal to the level of its parent plus 1.
All siblings have the same level.
A tree where all leaf nodes are at the same level is called balanced.
In that case, the path from the root node to any leaf node has the same length.
If leaf nodes occur at different levels, the tree is said to be unbalanced.
We will use different types of trees as index structures for our data files to quickly look up key value pairs.
Such trees are called search trees.
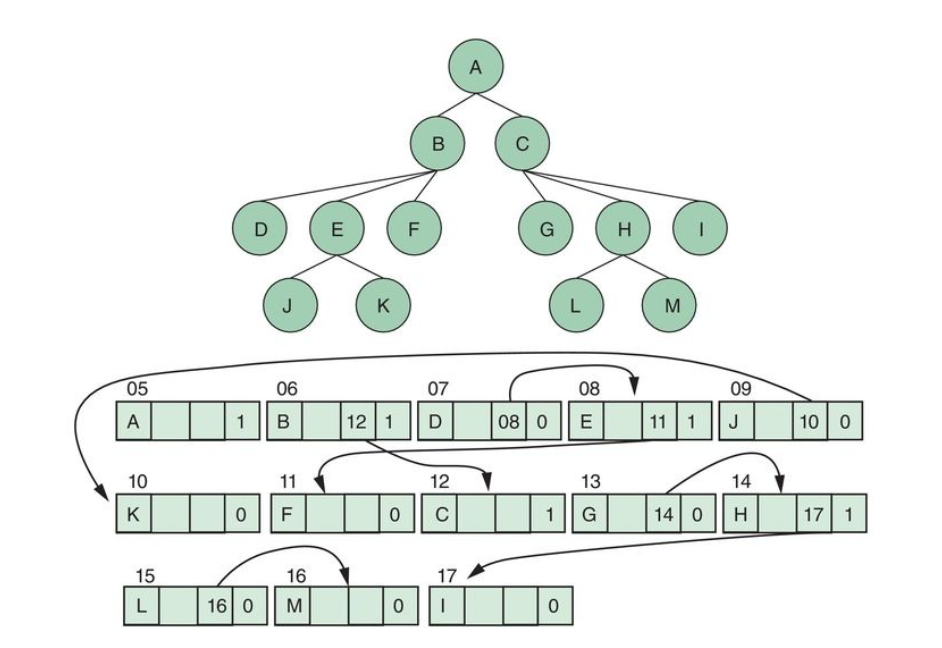
Tree Implementation
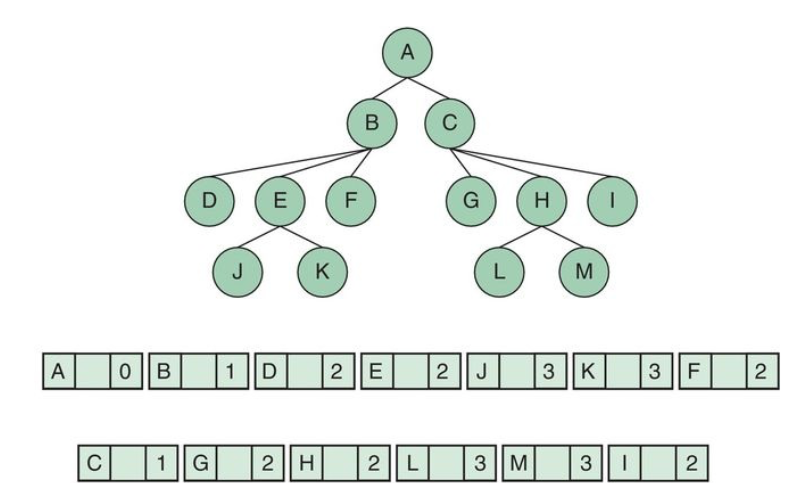
Trees can be implemented using list...
...and so can be represented as contiguous lists:
Notice order levels left to write, use an int in a node to indicate level.
...or represented as linked lists:
Notice use a final bit to indicate whether leaf or not.