Last week, we were discussing networks which support Quality of Service (QoS) - different levels of service for different flows.
We gave a taxonomy of service requirements different applications might have.
We looked at the per-flow/fine-grained QoS of Integrated Services and the category of flow type/coarse grained approach of Differentiated Services.
For IntServ, we said that typically we choose between guaranteed and controlled-load services when we want some higher level of service.
We went over how to specify the RSpec (requested service spec) and TSpec (traffic spec).
We went over admission control and resource reservation -- the latter using RSVP.
We went over how packet scheduling might be done using a variant of weighted fair queuing.
We said scalability might be a problem for IntServ, and so DiffServ is often used (especially for IP phone services).
For differentiated services (DiffServ), we classify packets into different levels of service (i.e., because a company paid more for service, etc.), typically at an administrative boundary.
Given a packet classification, the IETF has defined different 6-bit per-hop behaviors (PHBs) that can be specified using the IP TOS header field.
On Wednesday, we described what the Expedited Forwarding PHB indicates a router should do (forward by the packet with minimal delay and loss) and how it can be implemented (how to ensure EF packets never arrive too fast for a port to handle).
Today, we begin by looking at the Assured Forwarding PHB.
Assured Forwarding (AF) PHB
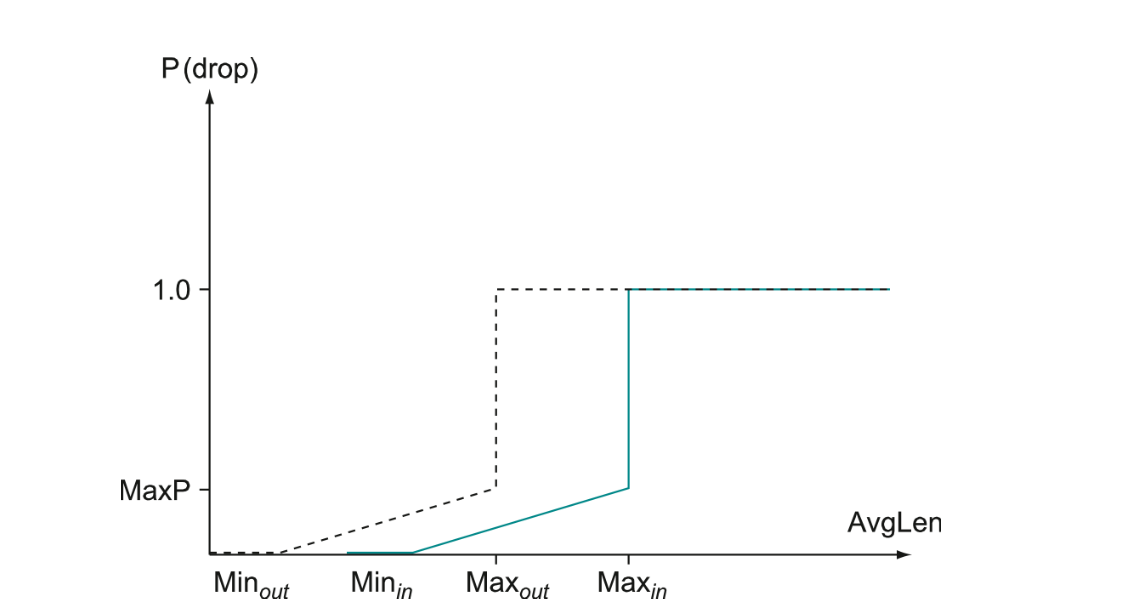
The handling of packets marked with the Assured Forward PHB is done using the RIO (RED in out) variant of the RED (Random Early Detection) protocol.
As with EF PHBs, we assume packet marking is done at edge routers of the administrative domain.
In this case, packets are marked as either being "in" profile or "out" of profile.
What an "in" or "out" profile is depends on the ISP. For example, it might be something like "customer `X` is allowed to send up to `y` Mbps of assured traffic." In this case, as long as the customer sends less than `y` Mbps of assured traffic, all packets are marked "in"; additional traffic above this is marked "out".
Once marked as "in" or "out", routers run the RIO variant of RED: If a packet is marked "in", then it gets dropped according to the "in" RED curve (more favorable), and if it is marked "out", it gets dropped according to the "out" RED curve.
If the majority of packets are "out" packets, then it should usually be the case that the RIO mechanism will act to keep congestion low enough that "in" packets are rarely dropped.
RIO can be generalized to more than just two classes of traffic, say `n` different levels, in an approach called WRED (weighted RED).
In WRED, the value of the DCSP (DiffServ Code Point, i.e., the 6 bits used to say per-hop behavior) is used to select which curve to use.
Differentiated Services via Weighted Fair Queuing
Rather than use WRED, another possibility is to use the value of the DCSP to determine which queue in a Weighted Fair Queuing scheme to put a packet in.
One can actually decide the number of queues to use up to `2^6` many.
So, for example, for a two-level service, one might have a code point one uses for the best-effort queue and another code point for the premium queue.
We then choose the weight for the premium queue that makes the premium packets get better service than the best-effort packets.
This value will depend on the load of the premium packets.
For example, suppose we weight the premium queue 1 and the best effort queue 4, then the bandwidth available to premium packets will be:
`B_{mbox(premium)} = W_{mbox{premium}}/(W_{mbox(premium)} + W_{mbox(best-effort)}) = 1/(1+4) = 0.2`.
So if the load of premium traffic is significantly less than this, say 0.1, the premium packets will be routed as if they are in a relatively lightly loaded network.
Equation-Based Congestion Control
Recall in host-based TCP congestion control, we adjust the sender's congestion window based in response to ACK timeouts.
This complements the QoS mechanism, we have been looking at because:
Applications can use host-based solutions without depending on router support.
Even with DiffServ fully deployed, router queues can be oversubscribed, so we'd like real-time applications to behave in a reasonable way.
Very often, real-time applications are built-on a UDP not TCP (as we often want to relax reliability), so they don't use sliding window at all, so don't have a notion of a congestion window.
So at the hosts ,there isn't a mechanism to detect congestion for these applications.
If a lot of the traffic on a network is real-time UDP flows, then these flows can be getting an unfair share of the bandwidth as compared to TCP flows because of this.
To handle this problem, several TCP-friendly congestion control mechanism have been proposed for such traffic.
Perhaps the simplest are equation-based congestion control methods.
For example, one can model the transmission rate of a TCP-friendly flow as:
`\mbox(Rate) \propto (1/(\mbox{RTT} \times \sqrt{\rho}))`
where `\rho` is the square root of the packet loss.
A real-time UDP flow implementation host-based congestion control, would then at the receiver end of the flow periodically, say every 100 packets, report back to the sender the rate at which packets are dropped. This packet could also acknowledge this 100th packet to allow the sender to calculate an RTT.
The sender could then adapt the rate it sends packets accordingly.
Quiz
Which of the following is true?
In DCTCP, no ECN mechanism is used.
In RSVP, the sender sends its TSpec as part of its PATH message to receivers.
In IPv4, the FlowLabel field might be used to do packet classification in IntServ.
Presentation Layer
At the transport layer we are reliably sending messages or stream bytes from one application on some host to another application on a potentially different host.
The receiver of the data typically wants to parse out integers, dates, images, etc. according to the format agreed upon by the sender and receiver.
This is the job of the presentation layer.
We now consider common encodings used for traditional computer data such as integers, float, etc.
Then we look at formats for well-established multimedia data such as images and video.
To send data efficiently, some kind of compression scheme is often used so we will also consider compression schemes as they effect our networks sensitivity to lost or delayed data.
Note unlike the layers we have considered so far where the non-header contents of packets were not looked at, formatting and compression are data manipulation functions which potential operate on each byte of a message or stream's content.
Presentation Formatting
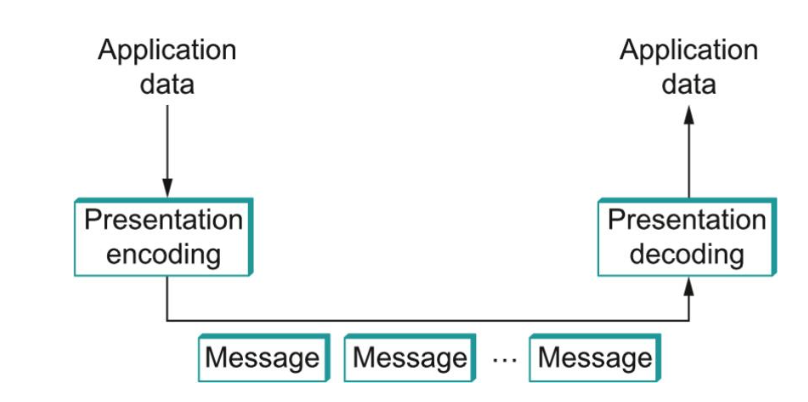
Presentation formatting is the transformation of data from the representation used by the application program into a format suitable for network transmission and vice versa.
The process of mapping from application representation to network representation is called encoding.
The reverse process, mapping from network representation to application representation, is called decoding.
The picture above illustrates encoding and decoding.
In the context of remote procedure calls, one often hears the terminology marshalling/de-marshalling or serialization/de-serialization for the same processes.
Several issues can make this a challenge.
Different computers and computer languages often represent data differently:
For example, there are several different formats for floats, of which, IEEE 754 is the most popular for 32 bit floats. There are several formats for characters: ASCII, EBCDIC, UTF-8, BIG-5, etc.
Two hosts might store integers differently, maybe one (a PowerPC processor machines) uses big-endian (most significant bit in the byte with highest address), another (an Intel x86 machine) uses little endian (most significant bit in the byte with lowest address).
Another issue is that the different programs that need to communicate might be using different languages or compilers. So the data alignment of the different data components might be different. For example, making a Pascal call using arguments coming from C in very old Macs was a pain.
Taxonomy of Presentation Design Choices 1 - Types
What data types is the system going to support?
What are the allowed base types such as ints, floats, characters, etc? How are they represented?
What are the allowed flat types such as structs and arrays that can be built from the base types? How are they represented? (Typically, one has some packing/unpacking mechanism to represent them without padding even though the compiler might pad.)
What are the allowed complex types? Typically, structures like trees, dags, linked-lists, etc., that are built with pointers or references. Need some mechanism to
flatten these into a string.
Taxonomy of Presentation Design Choices 2 - Conversion Strategy
Once the type system is established, the next question is what conversion strategy the argument marshaler should use.
The two most common are:
Canonical Intermediate Form - both the sender and receiver agree on an external representation for each type. The sender translates its data from its format into this
representation and the receiver translates from this representation to its format.
Receiver-makes-right - the sender transmits data in its own format. It doesn't convert base types, but does pack and flatten more complex data structures. The receiver then does the translation of this into its own format. This is an awkward N-to-N architecture: Each of N machine architectures needs to be able to handle each of the other N architectures.
Which of these is chosen often depends on whether the creator of a particular application thought N would be large or not.
Taxonomy of Presentation Design Choices 3 - Tags
Another important marshaling issue is how does the receiver know the kind of data contained in the message it receives?
Two approaches are: tagged data and untagged data.
Here a tag is any additional information included in the message -- beyond the concrete representation of the base types -- that
helps the receiver decode the message.
For example, each data item might be augmented with a type tag to say if it was an int, float, etc.
A character string or array might be augmented with a length tag.
An architecture tag might specify the architecture on which the data was generated for example 32 bit versus 64 bit.
So a 32 bit int might be encoded as TYPE LEN VALUE ( INT 4 417892, for example).
Taxonomy of Presentation Design Choices 4 - Stubs
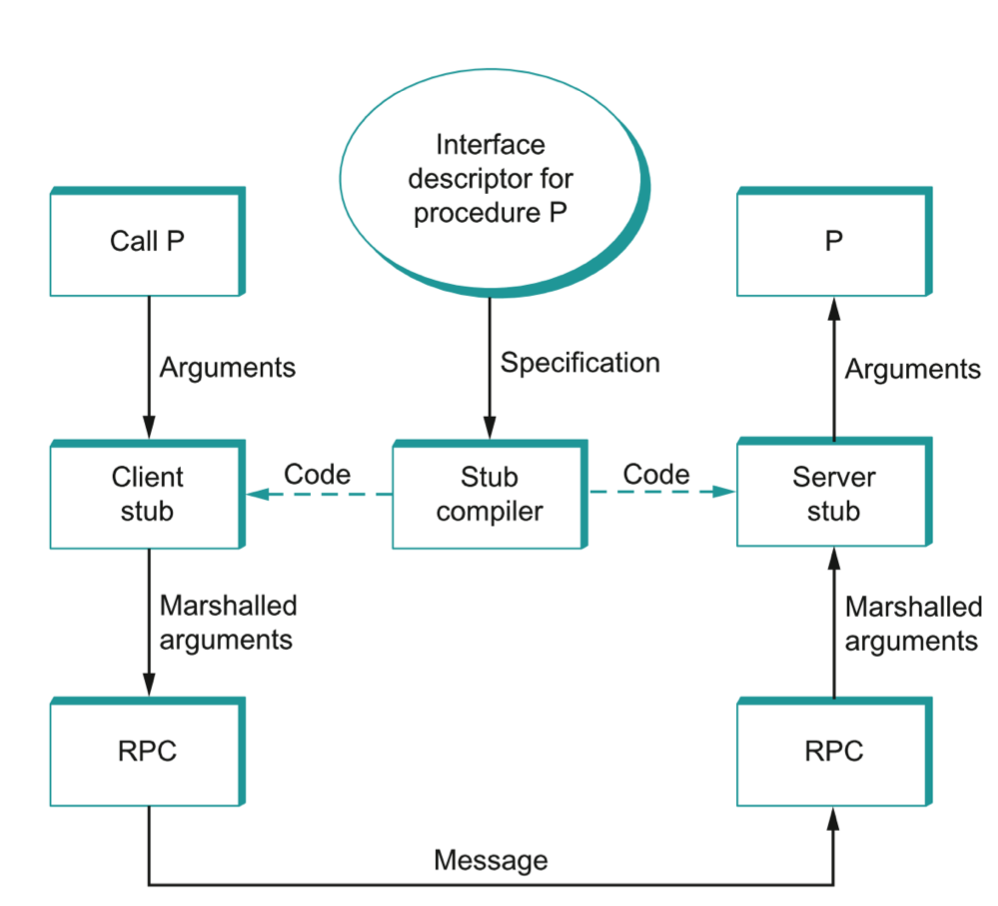
A stub is a piece of code that implements argument marshaling.
Stubs are typically used to support RPC.
On the client, the stub marshals the procedure arguments into a message that can be transmitted by means of the RPC protocol.
On the server, the stub converts the message back into a set of variables that can be used as arguments to call the remote procedure.
Stubs can be either interpreted or compiled. (In Java, we saw the program rmic for compiling stubs.)
Example Network Data Representations - XDR
We now look at four popular network data representations in terms of our taxonomy.
We start with the External Data Representation format (XDR).
This format was used with SUN-RPC.
In terms of our taxonomy:
It supports the entire C-type system with the exception of function pointers.
It defines a canonical intermediate form.
It does not use tags.
It does use compile stubs.
Some example portions of this intermediate format are:
A C int is represented as XDR integer, a 32 bit two complement integer with the most significant byte in the first byte (big endian).
An array is specified as an unsigned int flowed by that many elements of the appropriate type.
Structures are encoded in the order of their declaration.