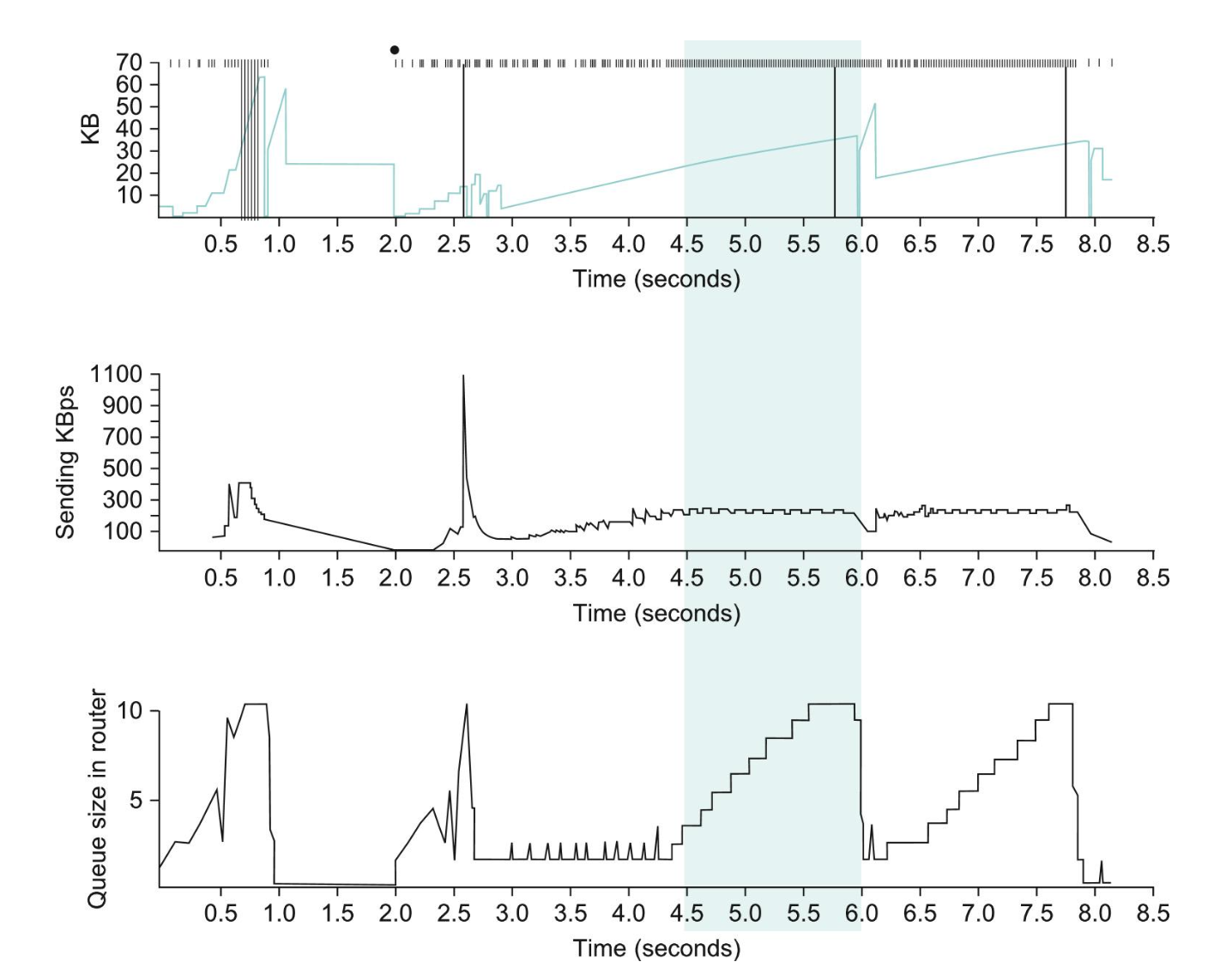
More Congestion Avoidance
CS158a
Chris Pollett
April 19, 2023
CS158a
Chris Pollett
April 19, 2023
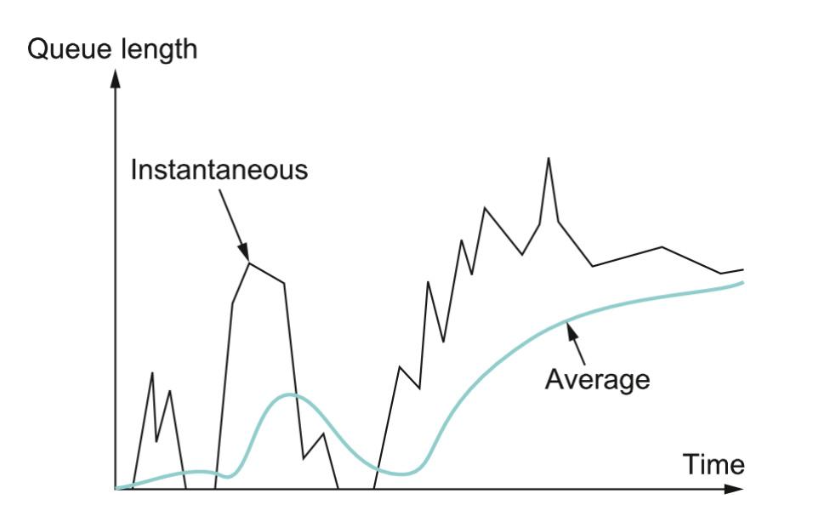
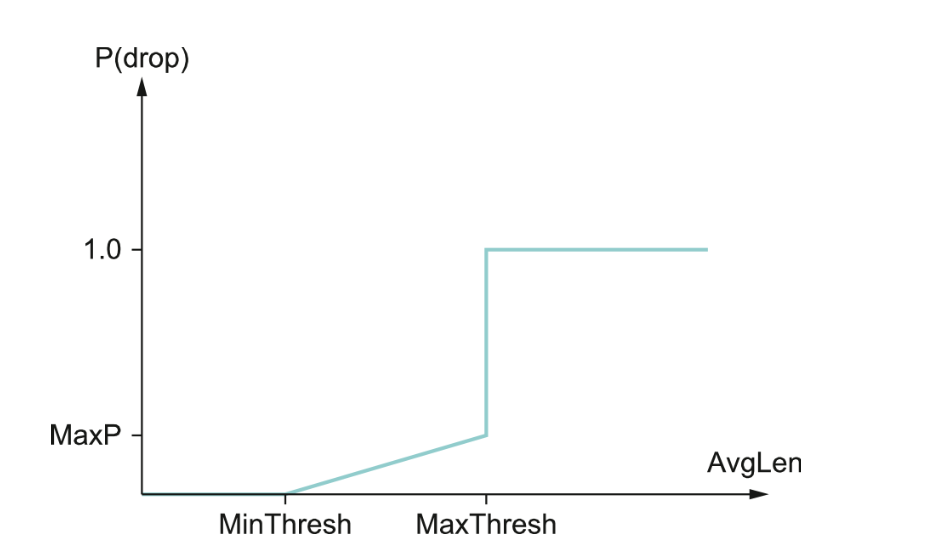
if AvgLen ≤ MinThreshold queue the packet if MinThreshold < AvgLen < MaxThreshold calculate probability P drop the arriving packet with probability P if MaxThreshold ≤ AvgLen drop the arriving packet