Outline
- Distributed Query Processing
- In-Class Exercise
- Distributed Commits
- Distributed Locking
Introduction
- On Monday, we began talk about parallel and distributed databases.
- We said one of the key differences between these systems is whether we think
communication cost will play or won't play a significant amount in data processing on multiple machines.
- After talking about different kinds of parallel DB architectures (shared memory, shared disk, shared nothing),
we said how to implement tuple at a time and full relation, relational algebra operations in the parallel shared nothing
set-up.
- We then talked about the map reduce model of parallelism.
- Finally, we started talking about distributed databases.
- We gave three example situation where we might have a distributed database set-up: a bank, a department store chain, and a digital library.
- Today, we begin by looking at how transaction processing needs to be modified in a distributed database setting.
Distributed Query Processing
- We have already said how to do query processing in the parallel shared nothing architecture setting.
- Recall one step in computing a join was for each machine to send each of the other machines, its fraction of the join. If the network is relatively low-capacity this might be very slow.
- To fix a simple example suppose we want to compute $R(X,Y) \bowtie S(Y, Z)$.
- A naive way to compute the join might be:
- Determine who has the smaller table.
- Send a copy of the smaller table to the other site, then compute the join there.
- Ideally, we'd like to send only the relevant part of the query to the other site.
Semi-join Reductions
- Assume `R` is the smaller table
- To facilitate only sending data needed to compute the join,
we introduce the notion of a semi-join, $R \ltimes S := R \bowtie (\pi_Y(S))$.
- Notice the project of `\pi_Y(S)` will return precisely those values of `Y` which might join with $R$ in $R(X,Y) \bowtie S(Y, Z)$.
- To minimize the communication between the two sites, we can then do
the following steps to compute the join:
- The machine with `S` computes `\pi_Y(S)` sends it the machine with `R`.
- The machine with `R` computes $R \ltimes S$ sends it to the machine with `S`.
- The machine with `S` uses $R \ltimes S$ to compute $R(X,Y) \bowtie S(Y, Z)$.
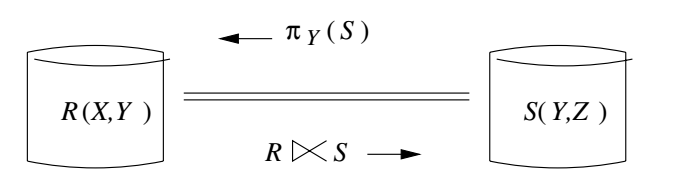
- For this to be an improvement over the naive algorithm, it should be the case that $R \ltimes S$ is smaller than `R`.
- That is, `R` contains many tuples which are dangling (don't join with `S`).
- In the case of joins of many relations, it becomes important to identify which semi-joins to compute and in what order. The book gives algorithms for this that we will skip.
- Hopefully, though, the above example gives a flavor of how query processing might change in the distributed setting.
In-Class Exercise
- Let `R` and `S` be the following two tables:
| A | B | C |
|---|
| a1 | b1 | c1 |
| a2 | b2 | c2 |
| a3 | b3 | c3 |
| a4 | b4 | c4 |
- Show for these tables how a join would be computed in the distributed setting. Compare the costs if we sent all of `S` versus the approach of the previous slide using semi-joins.
- Please post your solution to the Apr 29 In-Class Exercise Thread.
Distributed Commit
- A distributed transaction might have components that live at a variety of sites.
- Nevertheless, we want our transactions to operate atomically and serializably.
- For example, consider the department store chain setting.
- Suppose we want to find the inventory of toothbrushes at each site, and issue instructions to move toothbrushes from store to store in order to balance inventory.
- This operation could be coordinated by a single global transaction `T` that has components `T_i` at the `i`th store and component `T_0` at the office where the manager is.
- T might do:
- Create `T_0` at manager site.
- For store `i`, have `T_0` send message to Store `i` to create `T_i`.
- Each `T_i` executes a query to compute the number of toothbrushes at Store `i` and sends the result back to `T_0`.
- `T_0` computes what shipments of toothbrushes are desired. `T_0` sends messages to the stores of the form: "Store i send X toothbrushes to Store j".
- Stores receive messages, update their inventory and perform shipments.
What Might Go Wrong
- Atomicity of `T` could get broken if some of its actions get executed but not others.
- We will assume that each site has logging and recovery for its database.
- This assures that each `T_i` will execute atomically, but not that the whole transaction will.
- Suppose a bug in the distribution algorithm tells Store 10 to send out more toothbrushes then it has. This cause `T_10` to abort. On the other hand, `T_7` never detects a problem for its portion of the transaction so commits.
- So the whole transaction won't have executed atomically and the database will be in an inconsistent state.
- Another source of problems is one of the sites might go down while the transaction is in progress.
- This might affect whether the transaction can ever commit and it also leads to the question of what should the machine do when it comes back alive?
Two Phase Commit - Prerequisites
- One of the building blocks that is used to solve the problems we just raised is the two phase commit protocol. (This is something entirely different than two-phase locking)
- The two phase commit protocol needs the following prerequisites:
- Each site needs to log actions for that site. There is no global log.
- One site, called the coordinator, gets to determine if the transaction has committed or not. (In our previous example, this could be `T_0`.)
- When messages are sent, the sender logs the message that was sent to aid in recovery if necessary.
Two Phase Commit - Phase 1
- During this phase, the coordinator decides when to attempt to commit or abort transaction `T`. If the coordinator is running `T_0` then this should be after `T_0` is ready to commit or abort.
- To make this decision the coordinator and other sites do the following:
- The coordinator places a log record `langle Prepare\ T rangle` on the log at its site.
- The coordinator sends to each component's site, the message prepare T.
- Each site receiving this message, decides whether to commit or abort its `T_i`. The site is allowed to delay if it is not yet done, but must eventually respond.
- A site that wants to commit, enters a precommitted state. In this state, it is not allowed to abort unless it gets a message from the coordinator saying it can abort. Becoming precommitted involves:
- Ensuring all actions of `T_i` are done and their log records have been written, so they would be redone in recovery.
- `langle Ready\ T rangle` has been written to the log.
- A message ready T is sent to the coordinator.
- If a transaction doesn't want to commit, it writes `langle Don't\ commit\ T rangle` to its log and sends don't commit T to the coordinator. At that point it aborts the transaction.
Two Phase Commit - Phase 2
- Once each site has sent its ready T or don't commit T messages
to the coordinator Phase 2 can begin.
- If a message isn't received by the coordinator within some time out period, it is treated as a don't commit message.
- To complete the transaction, the following operations are done in Phase 2:
- If the coordinator receives ready T from all of the components, then it decides to commit `T`. It logs `langle Commit\ T rangle` at its site and sends a commit T message to all the other sites.
- If the coordinator receives any don't commit T from any of the components, then it logs `langle A\b\o\rt\ T rangle` at its site and sends a abort T message to all the other sites.
- If a site receives a commit T message, it commits the component of `T` at its site by writing a `langle Commit\ T rangle`.
- If a site receives an abort T message, it aborts the component of `T` at its site by writing a `langle A\b\o\rt\ T rangle`.
Two Phase Commit - Recovery
- If a database needs to be restarted in our two phase commit setting,
then we can do the following to restore our copy of the database to a consistent state:
- If there are no log records relating to the two-phase commit, the machine can abort `T` and send this message to the coordinator.
- If we see for a transaction `T` a commit record in the log, then we redo it (we're assuming either redo or undo/redo logging).
- If we see for a transaction `T` a ready record in the log, without a later commit or abort, then we redo it. The machine then tries to communicate with first the coordinator, if it is up, or some other site distributed DB if it is not, to see if there were any commit T or abort T messages. If so it then does the appropriate action. If no such messages exist or the machine cannot reach anyone, then it leaves the transaction live and tries again periodically to contact other machines.
- If we see for a transaction `T`'s don't commit or an abort, we undo its actions on the database.
- An additional wrinkle in the above set-up may happen if it is the coordinator that fails and needs to be recovered, as all of the other participants then need to wait until the coordinator finished recovery.
- In some situations, it might make sense to support electing a new coordinator. One technique to do this is for all machines that can be a coordinator to broadcast their IP and then do a Byzantine Agreement protocol amongst the machines over the lowest address that each machine heard to choose who is the leader.
Distributed Locking
- We assume each site has its own lock manager which is responsible locking elements on its component of a transaction.
- We also assume components of a transaction can only request locks on elements at its site.
- If we have multiple copies of the same data element `X` (i.e., we replicate `X`),
we need to ensure that all copies of `X` are changed in the same way by each transaction.
- We distinguish locking the logical database element `X` from locking one or more of its copies.
Centralized Locking
- In centralized locking, we maintain a lock site.
- This site has a lock table for logical elements, whether or not the lock site has copies of these elements at its site.
- When a transaction wants a lock on logical element `X`, it sends a request to the lock site, which grants it as appropriate.
- The cost of locking is then three messages per lock (request, grant, release).
- Some drawbacks of centralized locking are:
- The lock site can become a bottleneck to the throughput of the system.
- If the lock site goes down, no transactions can be processed.
Using a Lock Coordinator
- Let's now consider the setting where there is no replication, and each site has its own locking mechanisms for the elements that it has.
- A distributed transaction might need locks on several database items `X`, `Y`, and `Z` that don't live all on the same site.
- Component parts of the transaction at different sites need to at least exchange messages to determine if all the necessary locks for the transaction have been obtained before proceeding.
- To simplify this process, we assume one component of every transaction acts as a lock coordinator for that transaction.
- It is responsible for gathering all the locks needed for the transaction.
- For locks needed on its own site, the lock coordinator doesn't need any messages to do locking.
- To lock `X` on a different site `S`, the following messages need to occur:
- A message to `S` requesting the lock for `X`.
- A reply message granting the lock or a denial message (assume lock will eventually be granted by a later message).
- A message to `S` releasing the lock on `X`.
- For a given transaction, we typically choose the lock manager to be the site of the component of the transaction that needs the most locks.
Locking with Replication -- the Problem
- Suppose we don't have a global lock table, but we do have replicated database elements `X`.
- What we don't want is to have two copies of logical element `X` on different sites, say `X_1` and `X_2`, and for transaction `T_1` to get the lock on `X_1` and at the same time `T_2` to get the lock on `X_2` and each change the value of their copy, but because they don't have the lock, be unable to change the other copy.
- The database in this bad scenario might end up in an inconsistent state, and we might not be able to serialize `T_1` and `T_2`.
- To assure serializability, we need transactions to take global locks on the logical elements, even though these don't exist physically (only the copies exist physically).
- We next look at a scheme for turning local locks into global locks which have the property:
- A logical element `X` can have either one exclusive lock and no shared lock, or any number of shared locks and no exclusive lock.
Primary-Copy Locking
- In the primary-copy lock method, each logical element `X` has one of its copies designated the "primary copy".
- Different database elements `X`, `Y` might have their primary copies on different sites.
- In order to get a lock on a logical element `X`, a transaction sends a request to the site of the primary copy of `X`.
- This site has a lock table with `X` in it and can appropriately grant or deny the request.
Distributed Deadlocks
- As in the non-distributed setting, it is quite possible in the distributed setting to get deadlocks.
- It is often harder, however, to detect them.
- For this reason, rather than use wait-for graphs or timestamping, in the distributed setting most systems use timeouts.
- If a transaction has not complete after an appropriate amount of time, it is assumed to have deadlocks, and is rolled back.










