Outline
- Concurrency Control and Recoverability
- In-Class Exercise
- Deadlock Detection
- Long Duration Transactions
Transaction Management
- We have now talked about recovery and about serializability,
but we haven't said how to get these two components of the DBMS to work together.
- Our logging mechanisms make no mention of serializability and there is no guarantee
when we do a recovery that the consistent state we get to corresponds to something that
might have been produced by a serializable schedule.
- On the other hand, there is nothing about two phase locking that prevents a transaction
from writing into the database uncommitted data.
- We begin today with an example situation where logging and concurrency interact.
Cascading Rollbacks
- Consider the schedule:
- `L_1(A)`, `R_1(A)`, `W_1(A)`, `L_1(B)`, `U_1(A)`, `L_2(A)`, `R_2(A)`, `W_2(A)`, `L_2(B)` denied,
`R_1(B)`, `A_1`, `U_1(B)`, `L_2(B)`, `U_2(A)`, `R_2(B)`, `W_2(B)`, `U_2(B)`.
- If we are using timestamping with a commit bit the above schedule
without the locks couldn't happen, but it is a legal 2PL schedule.
- This is because `T_2` would have been delayed based on the commit bit for `A`, rather than allowed to read the value for `A`
that the uncommitted transaction `T_1` wrote.
- Now, however, `T_2`'s value for `A` is dirty so we should rollback `T_2` when `T_1` aborts.
This kind of rollback that causes another transaction to also rollback is called a cascading rollback.
- To avoid this problem, a transaction must not release any write locks
until it either commits or aborts and the commit or abort log record is flushed to disk.
This locking protocol is called strict 2PL (we mentioned it last day when talking about the repeatable read isolation level).
Recoverable Schedules
- For a logging method to allow for recovery, the set of transactions that are regarded as committed after recovery must be consistent.
- So if `T_1` is regarded as committed after recovery, and `T_1` read from `T_2`, then after recovery `T_2` must also be committed.
- This idea leads to the following definition:
- A schedule is recoverable if each transaction commits only after each transaction from which it has read commits.
- Here are some examples illustrating the interplay between serializability and recoverability:
- A serializable schedule that is recoverable:
`W_1(A)`, `W_1(B)`, `W_2(A)`, `R_2(B)`, `C_1`, `C_2`
`T_2` reads from `T_1` and commits after, so recoverable.
This schedule is equivalent to `T_1`, `T_2`, so serializable.
- A recoverable but not serializable schedule:
`W_2(A)`, `W_1(B)`, `W_1(A)`, `R_2(B)`, `C_1`, `C_2`
`T_2` reads from `T_1` and commits after `T_1` so recoverable. However, this schedule has
`A` written to by `T_1` after `T_2`, and `B` read by `T_2` after written by `T_1`, so not serializable.
- Serializable but not recoverable:
`W_1(A)`, `W_1(B)`, `W_2(A)`, `R_2(B)`, `C_2`,`C_1`,
This is equivalent to `T_1` followed by `T_2`, so serializable. Notice, though, if `C_2` had committed,
and there was a crash before `C_1` committed, then `T_2` would be committed after recovery and
`T_1` wouldn't have, but `T_2` has read from `T_1`, so this schedule is not recoverable.
In-Class Exercise
- Give a serializable but not recoverable schedule in which the last two operations are not both commits.
- Post your solution to the Apr 22 In-Class Exercise thread.
Schedules That Avoid Cascading Rollbacks
- A cascading rollback occurs when a transaction reads from another transaction that later aborts.
- A slightly tighter notion than recoverable can be used to guarantee both recoverability and prevents cascading rollbacks:
A schedule avoids cascading rollbacks (ACR) if transactions may read only values written by committed transactions.
- From our definitions, an ACR schedule will be recoverable.
- The schedules of the previous slide are not ACR, however, the following is:
`W_1(A)`, `W_1(B)`, `W_2(A)`, `C_1`, `R_2(B)`, `C_2`
Notice `T_1` commits before `T_2` tries to read the value of `B` written by `T_1`.
Relationships Serializability versus Recoverability
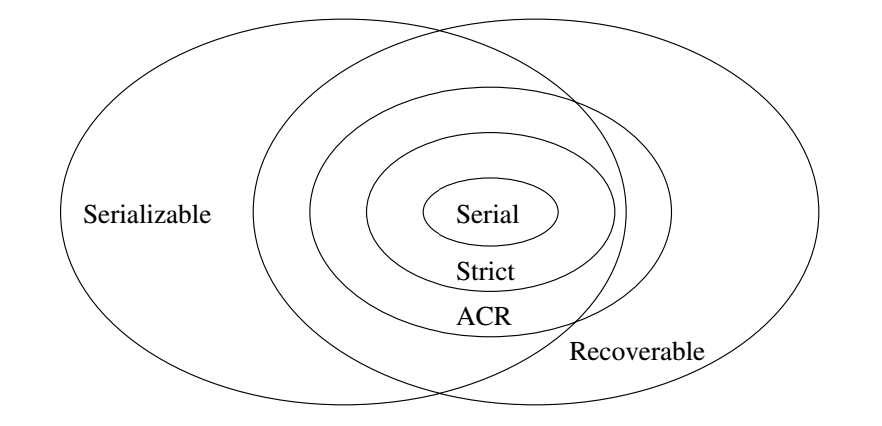
- Strict in the above is strict 2PL.
Why Strict 2PL ensures ACR and Serializability
- Every strict 2PL schedule is ACR as a transaction `T_2` can't read a value `X` written by `T_1` until after `T_1`
releases any exclusive lock. This release under strict 2PL won't happen until after `T_1` commits and the commit is flushed to disk.
- Every strict 2PL schedule is serializable as its schedule will be equivalent to the serial schedule given by the order of the
commits.
Handling Rollbacks for Database Elements
- Blocks:
- A quick trick when blocks are locked rather than rows
-- that does not require interaction with the log --
is to require blocks written (and locked) by uncommitted transaction be pinned in main memory
until the transaction commits or aborts.
- If a transaction aborts, as the changes are only in memory not disk,
its contents are ignored, and the block is put in the available buffer list.
- If we are using multiversioning rather than locking, if a transaction involving a
block `A` is aborted, then we just delete the version of block `A`
corresponding to that transaction.
- Rows and other sub-block elements: Several techniques might be used for these kinds of elements
- We can read the original value of `A` from disk, modifying the buffer in ram accordingly.
- If we have an undo log or undo/redo log, we can use it to revert the value.
- We can use a RAM based undo log which is kept only for the duration of the transaction.
Dealing with Deadlocks
- A deadlock occurs when every element `x` in a set `S` of at least two transactions is waiting for a lock resource held by some other element
`y in S` where `x ne y`.
- Deadlocking can occur even if we are using 2PL using shared, upgrade, and exclusive locks:
`SL_1(A)`, `R_1(A)`, `UL_2(A)`, `R_2(A)`,`SL_2(B)`, `R_2(B)`, `UL_1(B)`, `R_1(B)`, `XL_1(B)` denied, `XL_2(A)` denied
- Some common ways to deal with deadlocks are:
- Use a timeout: a transaction waits for a certain period for the lock and if it doesn't get it, it aborts and rolls back. Other waiting transactions might now have a chance to complete before their timeouts.
- Use a wait-for graph: A wait-for graph has as its nodes the active transactions and we have a edge from `T_i` to `T_j` if `T_j` has a lock on an item that prevents `T_i` from getting the lock it needs. If this graph has a cycle, then we are in a deadlock situation. To avoid deadlocks, if a transaction requests a lock that would make the wait-for graph have a cycle, we roll it back.
- Order the DB elements: We assume the database elements are ordered in some fixed order `X_1, X_2, ..., X_n`. We then require that all transactions must get locks on elements starting from the element with the lowest number they need to the element with the highest number they need. For example, `T` is allowed to request a lock on `X_3` then request a lock on `X_5` as `3 lt 5`, but it wouldn't then be allowed to request a lock on `X_1` as `3 gt 1`.
- Use Timestamps: Give each transaction a deadlock timestamp corresponding to when it started. If a transaction is rolled back and restarted, the deadlock timestamp is not changed. We then use one of the following two policies for all transactions:
- Wait-Die: If `T` is older than `U` and needs a lock held by `U`, then `T` is allowed to wait. On the other hand, if `U` is older than `T`, then `T` is rolled back.
- Wound-Wait: If `T` is older than `U`, then unless `U` has already finished and released its locks, we force `U` to be rolled back. On the other hand, if `U` is older than `T`, then `T` waits for the locks held by `U`.
Comparing Deadlock Handling Methods
- Using either timeouts or timestamps tends to be the easiest to implement.
- Using Wait-for graphs minimizes the number of rolled back transactions.
- Timestamps get us the closest to this property of wait-for graphs amongst the remaining options.
Long Duration Transactions
- A long transaction is a transaction that takes too long to be allowed to hold locks that another transaction needs.
- Depending on the context, a long transaction might take seconds, minutes, hours, or even days to complete.
- Some example application that might have long transactions are:
- Conventional DBMS Applications. For example, most banking transactions are short (withdraw ATM). However, you might need to have the occasional long transaction that does something such as examine all accounts to verify a total balance is correct.
- Design Systems. We might be using a database as a version control system for a CAD application like the design of a car. Users can check out components, modify them, and check them back in. We wouldn't want check outs to be equivalent to getting an exclusive lock, as it might take a while for someone to modify a part, and during this time no one could access it.
- Workflow Systems. These systems involve a collection of processes, many executed by software alone, but with some requiring human interaction. These transactions can involve things like billing which might require various office paperwork and can take days to complete. We wouldn't want other transactions to be locked out while these operations were ongoing.
Example Workflow
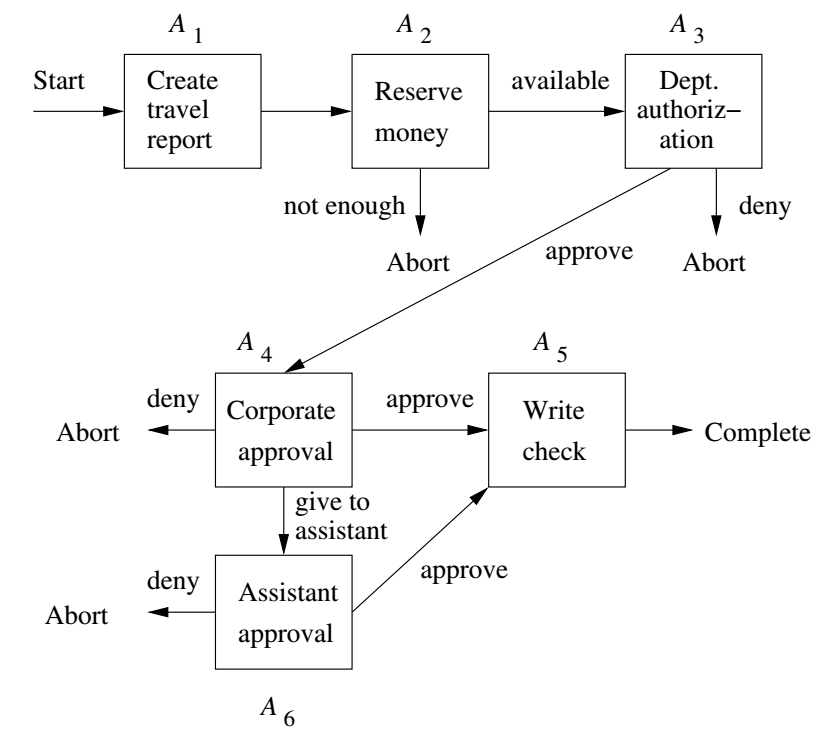
- Notice each of the operations above could involve action where data is stored in a database.
- Some of the operations involve humans and may be slow, so we wouldn't want to use exclusive locks for the duration of the whole transaction.
Sagas
- The example of the last slide suggests one way to handle long-duration transactions called sagas.
- A saga is a collection of actions that taken together form a long-duration transaction. More specifically, it consists of:
- A collection of actions
- A directed graph whose nodes are either actions or the terminal nodes Abort and Complete.
- A start node which is the action that begins the transaction.
- The graph on the previous slide would be example saga. The path `A_1A_2` is an example abort path. The path `A_1A_2A_3A_4A_6A_5` is an example of a complete path where the transaction succeeds.
Concurrency Control for Sagas
- Two facilities manage concurrency control for sagas:
- We view each action as a short transaction and use conventional currency control techniques to implement it.
- The overall transaction, which can mean any path from the start node to an abort or commit, is managed by using "compensating transactions".
For each action `A`, we insist there is an action `A^{-1}` which we can use to undo that action in the event that whole long-duration
transaction needs to be aborted. Here `A^{-1}` is called a compensating transaction.










