Finish Indexes, Query Execution
CS157b
Chris Pollett
Feb 26, 2018
CS157b
Chris Pollett
Feb 26, 2018
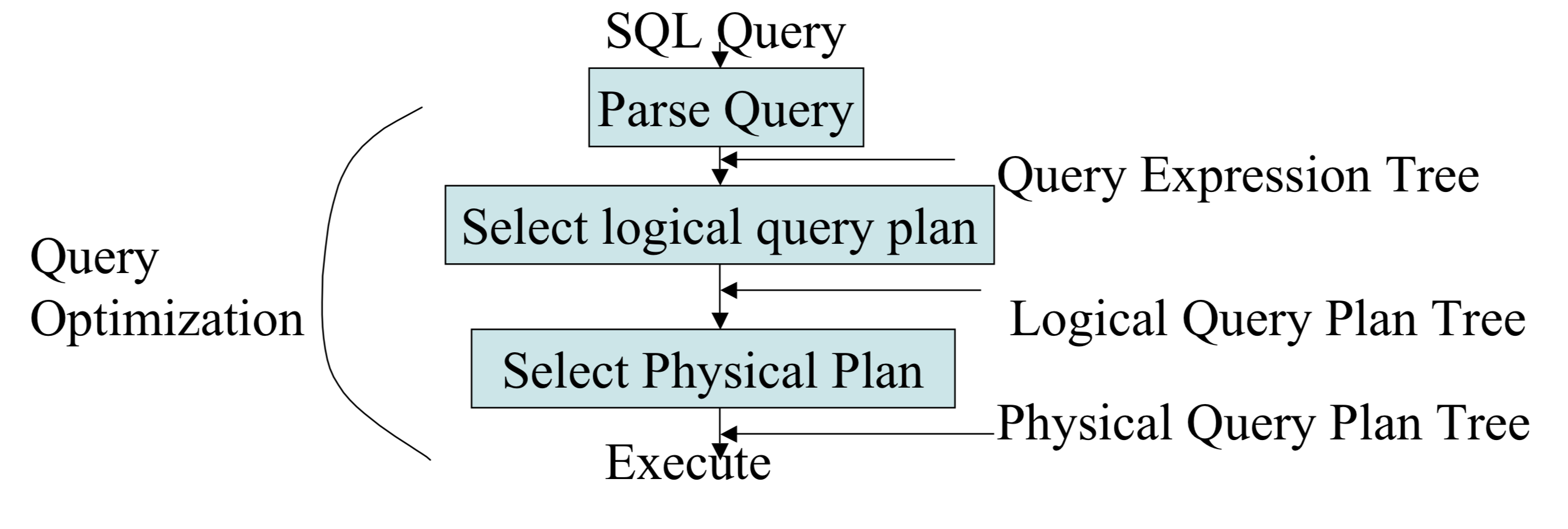
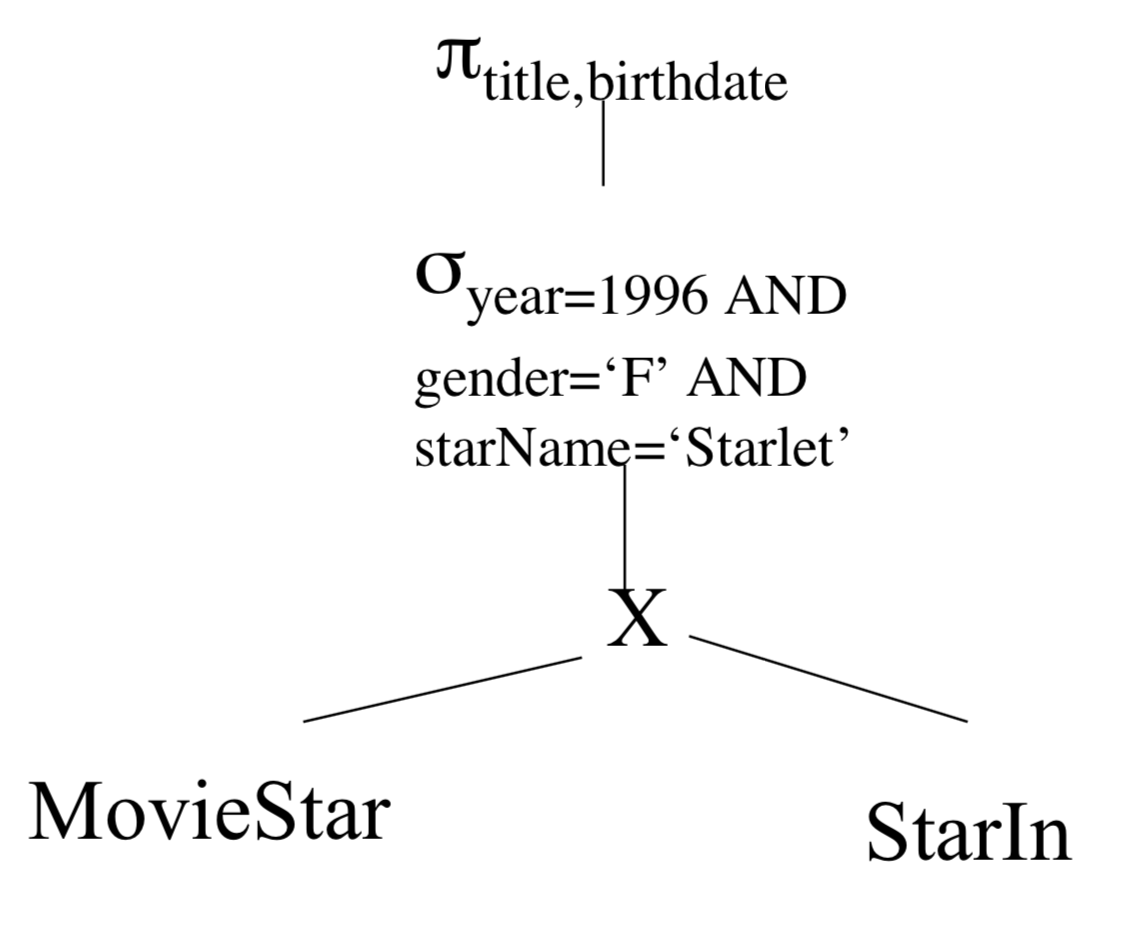
SELECT title, birthdate FROM MovieStar, StarsIn WHERE year =1996 AND gender='F' AND starName = 'Starlet'