We have been talking about how data files, indexes, and records are implemented.
We then looked more specifically on their implementation for each of the popular DBMS systems from the dawn of time to the present.
All indexes considered so far are on one field. Say salary.
We now consider indexes and file structures for more than one field. Say first name, last name.
There are several techniques for such indexes and files that we will consider:
grid-files
partitioned hash functions
multiple key indexes
kd-trees
quad trees
R-trees.
Application Needing Multidimensional Data
Geographics Information Systems
Store maps. Might include objects like points, houses, roads, etc...Or instead of maps, might store circuit layouts...
Types of queries:
Partial match query - ask for all points matching a certain values in some specified dimensions
Range query - ask for all points between range of values
Nearest neighbor queries -- closest point to a given point
Where am I query -- given a point, what object am I in?
More Applications
DataCube
These are often used by decision support applications where they are used to analyze information to better understand a companies operations.
For example, a chain of stores might collect with each sale: the date and time, the store of purchase, the item, the color, and the size.
This information could be viewed as a point in a mulitdimensional space and one might want to quickly answer aggregating queries like:
number of red ties sold in each store in each month of 2005.
SQL for Multidimensional Queries
Suppose we have a table of Points with `x` and `y` attributes.
A query might to look for the closest point to `(10,20)` would be:
SELECT * FROM Points p WHERE NOT EXISTS(
SELECT * FROM Points q
WHERE (q.x-10.0)*(q.x-10.0) + (q.y-20.0)*(q.y-20.0) <
(p.x-10.0)*(p.x-10.0) + (p.y-20.0)*(p.y-20.0)
);
Another possible query we might want to do is: Given a table of Rectangle's, find all tuples containing a point.
Using Conventional Indexes
To do a range query like find all points between `300 lt x lt 400` and `500 lt y lt 600`, we could have a B-tree index on `x` and `y`.
Suppose 1/10 of records satisfy the above condition on `x` and 1/10 satisfy the condition on `y`.
So 1/100 of points are in the rectangle.
Suppose 100 is the number of records that can be held in a block. If the original file had 1,000,000 records, then it would fit in 10,000 blocks
We could do a range query on x to retrieve records pointers for x in desired range and do the same for y.
We can then intersect these lists of pointers... And look up each record.
Unfortunately, each record is likely to be on a different block.
So we'd have to look up (`1/100 times mbox(# of records)`) blocks to do this. i.e., 10,000 blocks.
But this is the size of the whole file
...so doing a range query on `x` or `y` hasn't saved us anything over a table scan.
Quiz
Which of the following statements is true?
Data in a full-text index is always stored in a B-tree.
B-trees support range queries in a relatively straightforward fashion.
A linear hash table for a DBMS is the standard kind of hash table presented in CS146.
Hash-Like Structures for Multidimensional Data and Indexes
Grid Files
Partitioned hashing
Grid Files
A grid file is a index structure on more than one attribute.
We split each attribute dimension by a set of grid lines.
For Points table example might have lines `x= 100, 200, 300, 400, ...` and `y=100, 200, 300, 400...`.
To implement the grids lines, we could imagine we have two functions: xgrids(x) and ygrids(y).
xgrids(x) (ygrids(y) operates in a similar fashion) given a value `x` returns the three grid lines
satisfying `x_{i-1} lt x_i le x lt x_{i+1}`.
These two functions are specified at index creation time.
Given xgrids(x) and ygrids(y) we then have a hash function `h(x,y)` which first computes `(x_i, y_j)`.
This gives a rectangle that (x,y) belongs to: `(x_i,x_{i+1}] times (y_j,y_{j+1}]`.
The hash function then computes based on `(x_i,y_j)` a single block number in the table.
We can extend this idea in a similar fashion if have more than two dimensions.
Each bucket has a set of pointers to records of Points in that rectangle.
If a bucket is too full, we use overflow blocks.
So to look up a point, we compute `h(x,y)` to get a block number, then looks for the record in this bucket.
To insert into a grid file, we just determine the rectangle the Point to be inserted belongs to,
and add a pointer to the corresponding bucket.
Note we can implement neighborhood lookup by using xgrids and ygrids to find a set of rectangles that cover the
neighborhood we want, then search through all the points in that neighborhood.
Partitioned Hash Files
A Partitioned Hash Table is a hash table on several attribute `A_1, A_2, ...`;
however, we use a special kind of hash function such that the first `k_1` bits output
determined by `A_1` only, the next `k_2` bits by `A_2` only, ...
The buckets mapped to by the hash function are such that they are laid out by dimensions. So if we fix say `k_1=a`, we can easily compute
all the hash blocks that have `k_1 = a`.
Unlike a grid-file nearby points might be hashed to completely different buckets, so can't do nearest neighbor style queries.
The data in a partitioned hash table will tend to be more uniformly dispersed and so we are less likely to need overflow buckets.
Partitioned hash table are useful if we only care about partial match lookups (specify some attributes, leave others unspecified).
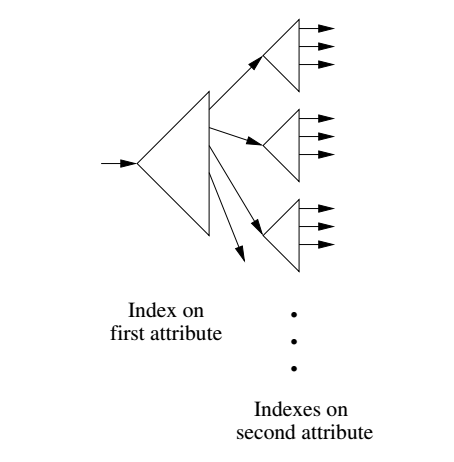
Multiple Key Indexes
Multiple key index is a kind of index on more than one attribute.
We will consider the two attribute case -- the more than two attribute case is implemented in a similar way.
In two key index, we first make a tree index on the first attribute.
The leaves of this tree are possible values for this attribute.
The pointer followed from this value points to a tree index on the second attribute.
Uses of Multiple-Key Indexes
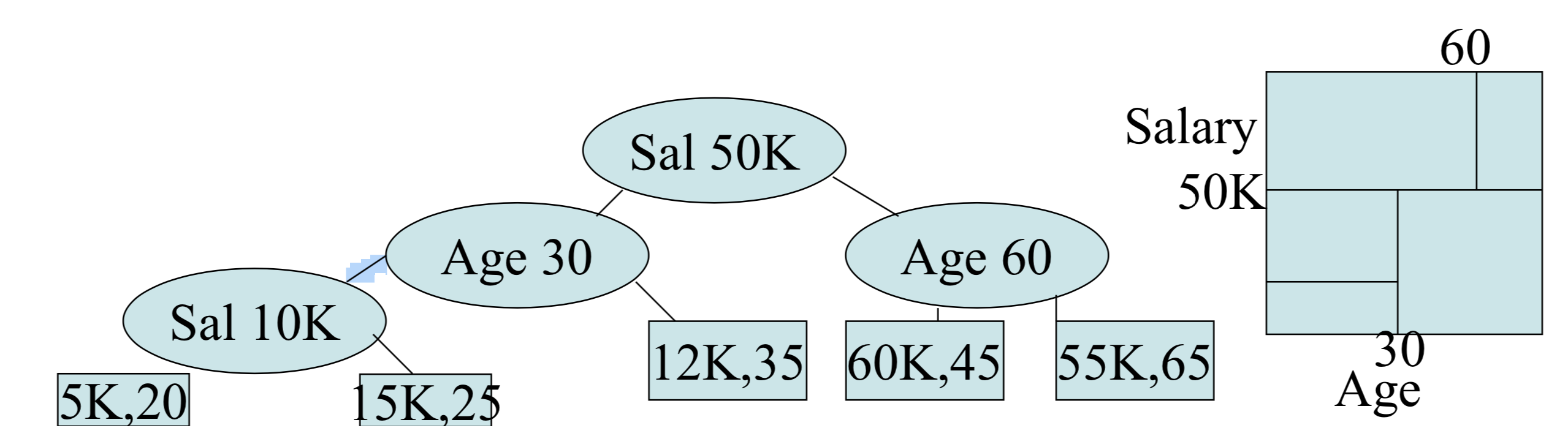
Supposed we have such an index on Age and Salary.
If, in a query, we specify both a fixed Age value (say 35) and a fixed Salary (say 20K), the results can be fast.
However if we wanted all Age's for a given Salary, such an index would be slow if Age was the first top index.
Multiple key indexes work well for range queries and nearest neighbor queries. (Treat nearest neighbor as a range query)
kd-trees
kd-trees are a generalization of binary search trees.
Each non-leaf node has some attribute `A` and some value `V`.
Leaf nodes contain record pointers to actual records.
The tree satisfies that beneath a non-leaf node on attribute `A` with check `V`, the records to the left of the node are less than `V`,
those to the right are greater than or equal to `V`.
Operations on kd-trees
Basic search in a kd-tree is to follow the nodes down the tree, following the branch on an attribute by choosing the side that matches the
record we are searching for.
Partial match search involves following both paths out of a node if do not know its value.
Similarly, for a range query, if the range straddles a query we have to follow both branches.
Nearest neighbor search is treated as a special kind of range query.
To do an insertion:
We first do a basic lookup search to find the leaf node the record should be inserted into.
If this node is not full, we add the record there.
If not, we choose the attribute that has the most possible values amongst those in the leaf node.
We then split the node in two based on the median value of this attribute and create a new interior node using this attribute and value.
To optimize kd-trees for disk rather than main memory,
rather than split on one value `V` at a node, split `n` ways based on block size.
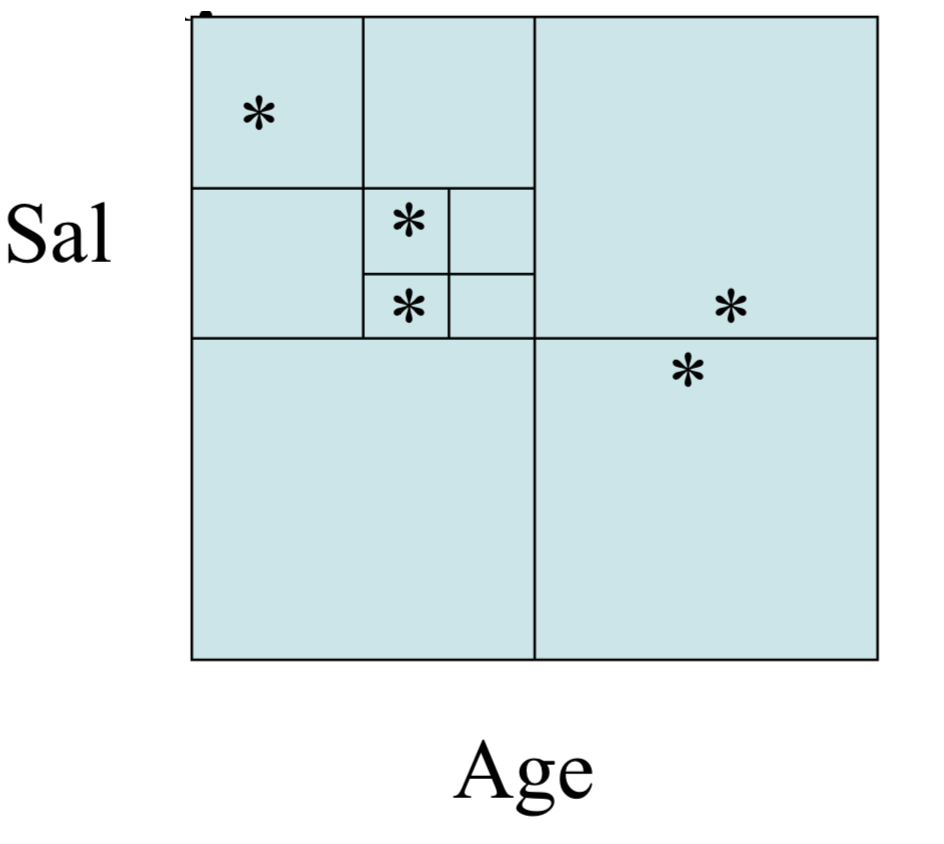
Quad-trees
Quad-trees are a kind of two attribute index.
To keep things simple, call these attributes x, and y.
Leaf nodes contain record pointers.
Non leaf nodes store for each attribute the highest and lowest value that might appear in the whole tree for that attribute.
Let `mid_x = (low_x + high_x)/2` and `mid_y = (low_y + high_y)/2`.
Non leaf nodes also store four child node pointers for each quadrant given by the four rectangles ((`low_x, low_y`), (`mid_x, mid_y`)),
((`mid_x, low_y`), (`high_x, mid_y`)), ((`low_x, mid_y`), (`low_x, high_y`)), and ((`mid_x, mid_y`), (`high_x, high_y`)).
Quad-tree operations are similar to kd-trees.
For search down a tree, we follow the appropriate choice of one of the four child node pointers based on the record we are searching for.
To insert, we search to a leaf block and insert there, if possible.
If not, we split the node into four subregions and a parent node (percolating this up the tree).
In the above a * indicates one blocks worth of data.
Quad-tree can be generalized if have keys on more than two attributes.