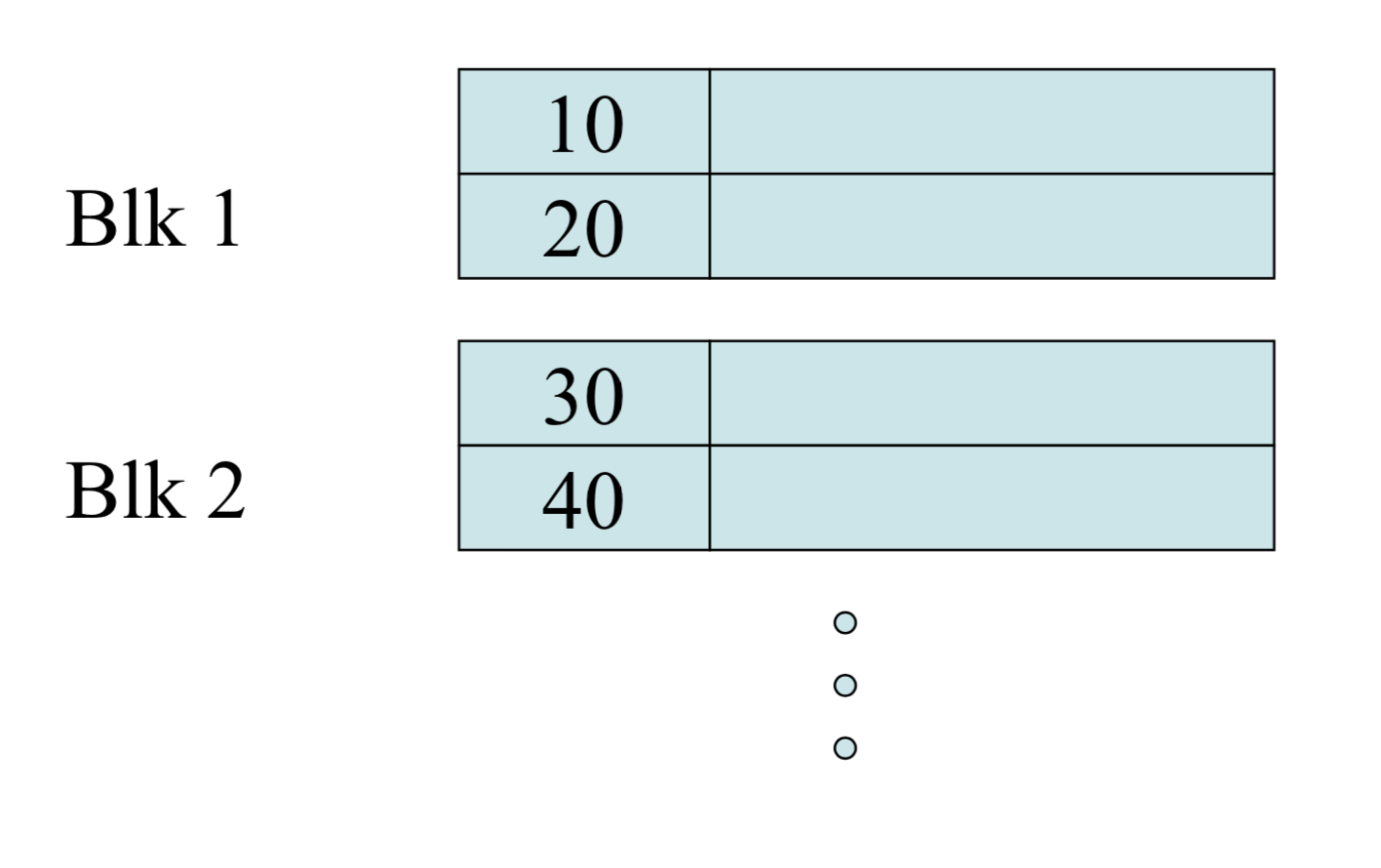
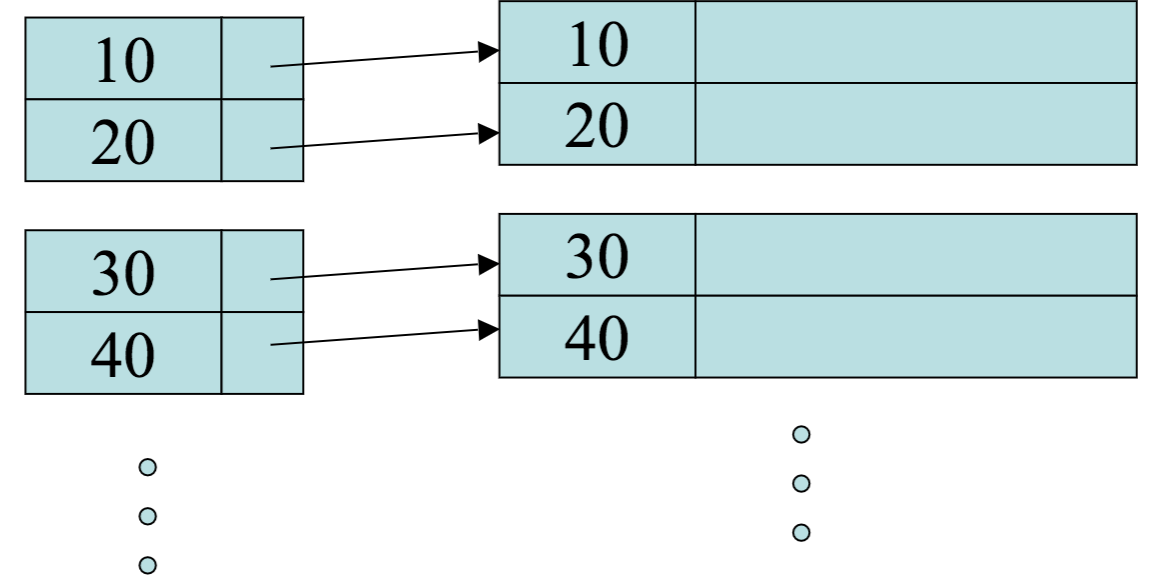
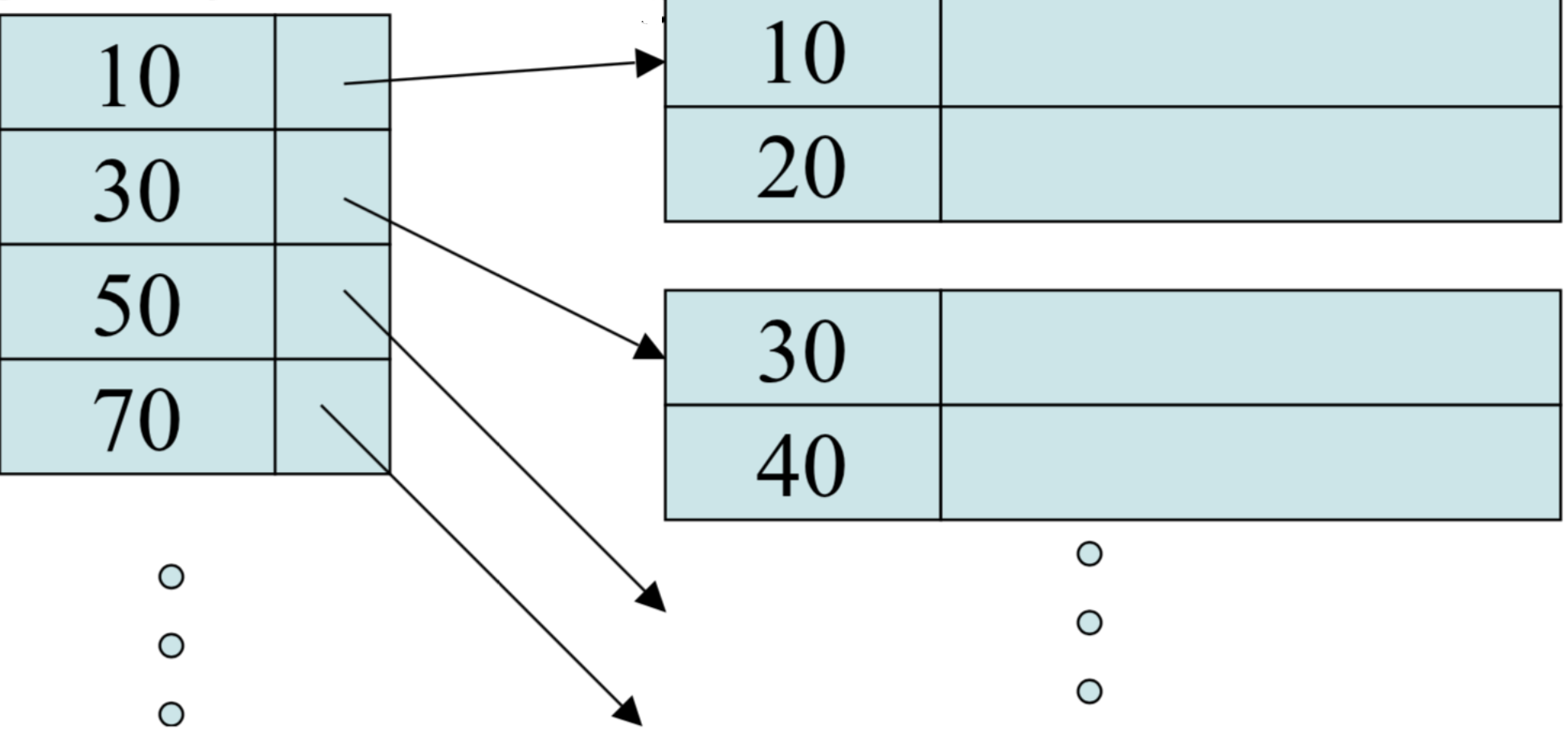
Variable Length Records, Record Modifications and Indexes
CS157b
Chris Pollett
Feb 10, 2020
CS157b
Chris Pollett
Feb 10, 2020
Which of the following statements is true?

SELECT * FROM R
SELECT * FROM EMP WHERE name = 'John Smith';only returns a small number of rows compared to the table.