










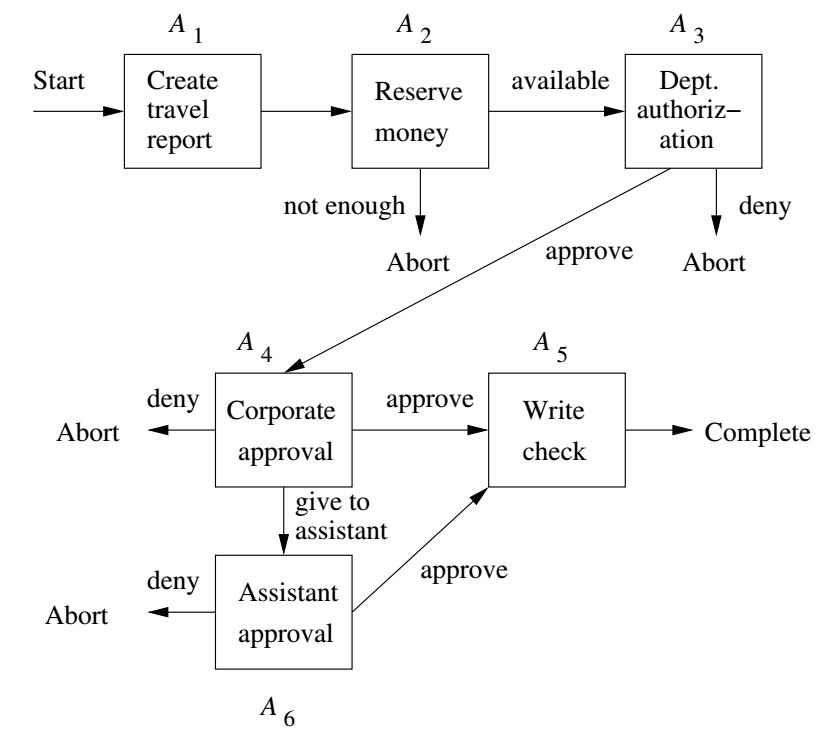
Finish Transactions - Parallel and Distributed Databases
CS157b
Chris Pollett
Apr 24, 2023
CS157b
Chris Pollett
Apr 24, 2023
Which of the following statements is true?
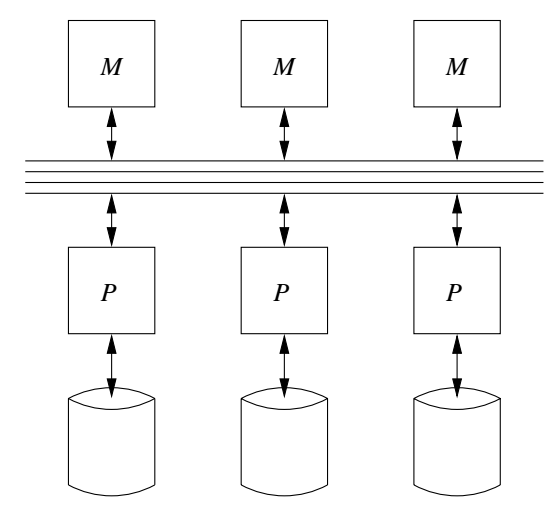
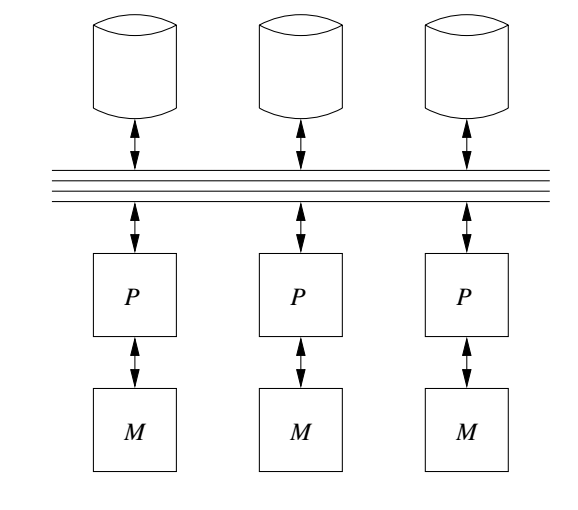
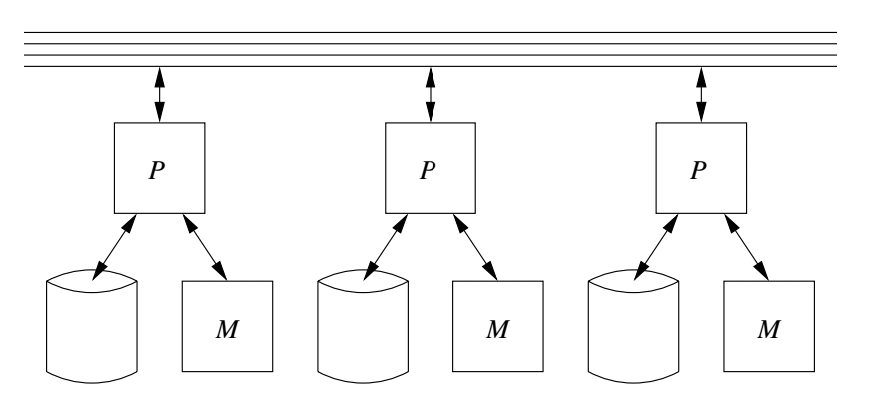
SELECT DISTINCT SALARY FROM EMPLOYEE;in parallel. I.e., in relation algebra, a `delta(R)` operation.
