Outline
- Concurrency Control and Recoverability
- In-Class Exercise
- Deadlock Detection
- Long Duration Transactions
div class="slide">
Introduction
- Last day, we started considering other techniques that allow serializable schedules besides locking, in particular, we began looking
at how we could use timestamps to do this.
- In this approach, we maintain for each transaction `T`, a starting timestamp `TS(T)` for when it began.
- For each database element `X`, we maintain `WT(X)`, the timestamp of when it was last written; `RT(X)`, the timestamp
of when it was last read; and `C(X)`, whether the last item to write `X` has committed.
- We identified the read-too-late and write-too-late problems as situations where the database scheduler might use `TS(T)`,
`WT(X)`, and `RT(X)` to determine that a transaction needs to be aborted.
- We also gave the dirty read problem as an example of a situation where the scheduler can make use of `C(X)` to determine that
a transaction's request needs to be delayed.
- We talked about a multi-version variant of timestamp scheduling that could be used to allow for greater interleaving of operations, but
still give serializable schedule.
- We said as a rule of thumb that timestamp scheduling is better than locking if the transactions tend to involve few writes (as no delays waiting for locks), but that locking works better in high conflict situations (as timestamping causes too many aborts).
- We said in SQL we use START TRANSACTION and COMMIT or ROLLBACK to tell the DBMS about transactions.
- We use SET TRANSACTION READ ONLY or SET TRANSACTION READ WRITE to help the DBMS tell if timestamping or locking should be used.
- We begin today by looking at another mechanism to tell the DBMS about how we want to handle transactions.
SQL Isolation Levels
- If a transaction is READ WRITE (DBMS will typically assume this by default), we can control the degree to which
its operations are isolated from other transactions by setting its isolation level. The possible variants on this are:
- SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; -- In this case, the DBMS can do the operations of the transaction and
not bother with locking. The transaction `T` might read data that is not committed (dirty reads) and values that `T` reads
might be changed while `T` is still operating (unrepeatable reads). Also, phantom records can be inserted while
the transaction is operating. This level might be suitable if you wanted to compute some statistics (which you write), and where you don't care
if the statistics are perfectly accurate, but you do want them calculated quickly.
- SET TRANSACTION ISOLATION LEVEL READ COMMITTED; -- In this case, the DBMS obtains exclusive locks before writes and holds them
until the end of the transaction. It obtains share locks before reads, but releases them immediately after the read. Given another transaction
at this level or higher, this guarantees that a read has been committed as exclusive locks are only released when a transaction ends.
It is possible to have unrepeatable reads and phantoms with this kind of locking.
- SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; -- In this case, the DBMS obtains exclusive locks before writes,
and shared locks before reads, but does not release any locks until the transaction commits or aborts. This is called strict 2PL. It is still possible
for phantom inserts to occurs at this level, but all reads will be repeatable.
- SET TRANSACTION ISOLATION LEVEL SERIALIZABLE; -- In this case, the DBMS obtains locks as in the REPEATABLE READ case, but also obtains
locks on any indexes and structure granularities that might be involved with `T`. Since an insert by another transaction `S`
would involve changing a table, and at this level the database would get an `IS` or `IX` lock on a table that `T` needs as well
as locks on an index elements, the insert can't happen until after `T` commits or aborts.
Transaction Management
- We have now talked about recovery and about serializability,
but we haven't said how to get these two components of the DBMS to work together.
- Our logging mechanisms make no mention of serializability and there is no guarantee
when we do a recovery that the consistent state we get to corresponds to something that
might have been produced by a serializable schedule.
- On the other hand, there is nothing about two phase locking that prevents a transaction
from writing into the database uncommitted data.
- We now look at an example situation where logging and concurrency interact.
Cascading Rollbacks
- Consider the schedule:
- `L_1(A)`, `R_1(A)`, `W_1(A)`, `L_1(B)`, `U_1(A)`, `L_2(A)`, `R_2(A)`, `W_2(A)`, `L_2(B)` denied,
`R_1(B)`, `A_1`, `U_1(B)`, `L_2(B)`, `U_2(A)`, `R_2(B)`, `W_2(B)`, `U_2(B)`.
- If we are using timestamping with a commit bit the above schedule
without the locks couldn't happen, but it is a legal 2PL schedule.
- This is because `T_2` would have been delayed based on the commit bit for `A`, rather than allowed to read the value for `A`
that the uncommitted transaction `T_1` wrote.
- Now, however, `T_2`'s value for `A` is dirty so we should rollback `T_2` when `T_1` aborts.
This kind of rollback that causes another transaction to also rollback is called a cascading rollback.
- To avoid this problem, a transaction must not release any write locks
until it either commits or aborts and the commit or abort log record is flushed to disk.
This locking protocol is called strict 2PL.
Recoverable Schedules
- For a logging method to allow for recovery, the set of transactions that are regarded as committed after recovery must be consistent.
- So if `T_1` is regarded as committed after recovery, and `T_1` read from `T_2`, then after recovery `T_2` must also be committed.
- This idea leads to the following definition:
- A schedule is recoverable if each transaction commits only after each transaction from which it has read commits.
- Here are some examples illustrating the interplay between serializability and recoverability:
- A serializable schedule that is recoverable:
`W_1(A)`, `W_1(B)`, `W_2(A)`, `R_2(B)`, `C_1`, `C_2`
`T_2` reads from `T_1` and commits after, so recoverable.
This schedule is equivalent to `T_1`, `T_2`, so serializable.
- A recoverable but not serializable schedule:
`W_2(A)`, `W_1(B)`, `W_1(A)`, `R_2(B)`, `C_1`, `C_2`
`T_2` reads from `T_1` and commits after `T_1` so recoverable. However, this schedule has
`A` written to by `T_1` after `T_2`, and `B` read by `T_2` after written by `T_1`, so not serializable.
- Serializable but not recoverable:
`W_1(A)`, `W_1(B)`, `W_2(A)`, `R_2(B)`, `C_2`,`C_1`,
This is equivalent to `T_1` followed by `T_2`, so serializable. Notice, though, if `C_2` had committed,
and there was a crash before `C_1` committed, then `T_2` would be committed after recovery and
`T_1` wouldn't have, but `T_2` has read from `T_1`, so this schedule is not recoverable.
In-Class Exercise
- Give a serializable but not recoverable schedule in which the last two operations are not both commits.
- Post your solution to the Apr 19 In-Class Exercise thread.
Schedules That Avoid Cascading Rollbacks
- A cascading rollback occurs when a transaction reads from another transaction that later aborts.
- A slightly tighter notion than recoverable can be used to guarantee both recoverability and prevents cascading rollbacks:
A schedule avoids cascading rollbacks (ACR) if transactions may read only values written by committed transactions.
- From our definitions, an ACR schedule will be recoverable.
- The schedules of the previous slide are not ACR, however, the following is:
`W_1(A)`, `W_1(B)`, `W_2(A)`, `C_1`, `R_2(B)`, `C_2`
Notice `T_1` commits before `T_2` tries to read the value of `B` written by `T_1`.
Relationships Serializability versus Recoverability
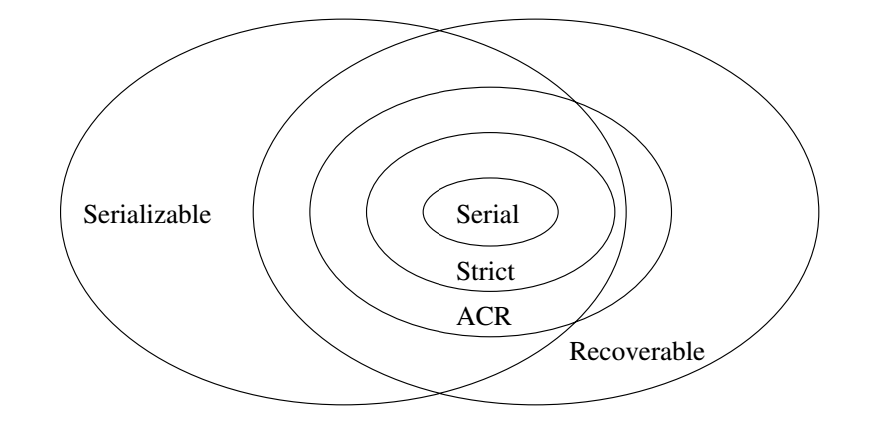
- Strict in the above is strict 2PL.
Why Strict 2PL ensures ACR and Serializability
- Every strict 2PL schedule is ACR as a transaction `T_2` can't read a value `X` written by `T_1` until after `T_1`
releases any exclusive lock. This release under strict 2PL won't happen until after `T_1` commits and the commit is flushed to disk.
- Every strict 2PL schedule is serializable as its schedule will be equivalent to the serial schedule given by the order of the
commits.
Handling Rollbacks for Database Elements
- Blocks:
- A quick trick when blocks are locked rather than rows
-- that does not require interaction with the log --
is to require blocks written (and locked) by uncommitted transaction be pinned in main memory
until the transaction commits or aborts.
- If a transaction aborts, as the changes are only in memory not disk,
its contents are ignored, and the block is put in the available buffer list.
- If we are using multiversioning rather than locking, if a transaction involving a
block `A` is aborted, then we just delete the version of block `A`
corresponding to that transaction.
- Rows and other sub-block elements: Several techniques might be used for these kinds of elements
- We can read the original value of `A` from disk, modifying the buffer in ram accordingly.
- If we have an undo log or undo/redo log, we can use it to revert the value.
- We can use a RAM based undo log which is kept only for the duration of the transaction.










