










I/O Model, Disk Access, Scheduling, Failure
CS157b
Chris Pollett
Jan 30, 2022
CS157b
Chris Pollett
Jan 30, 2022
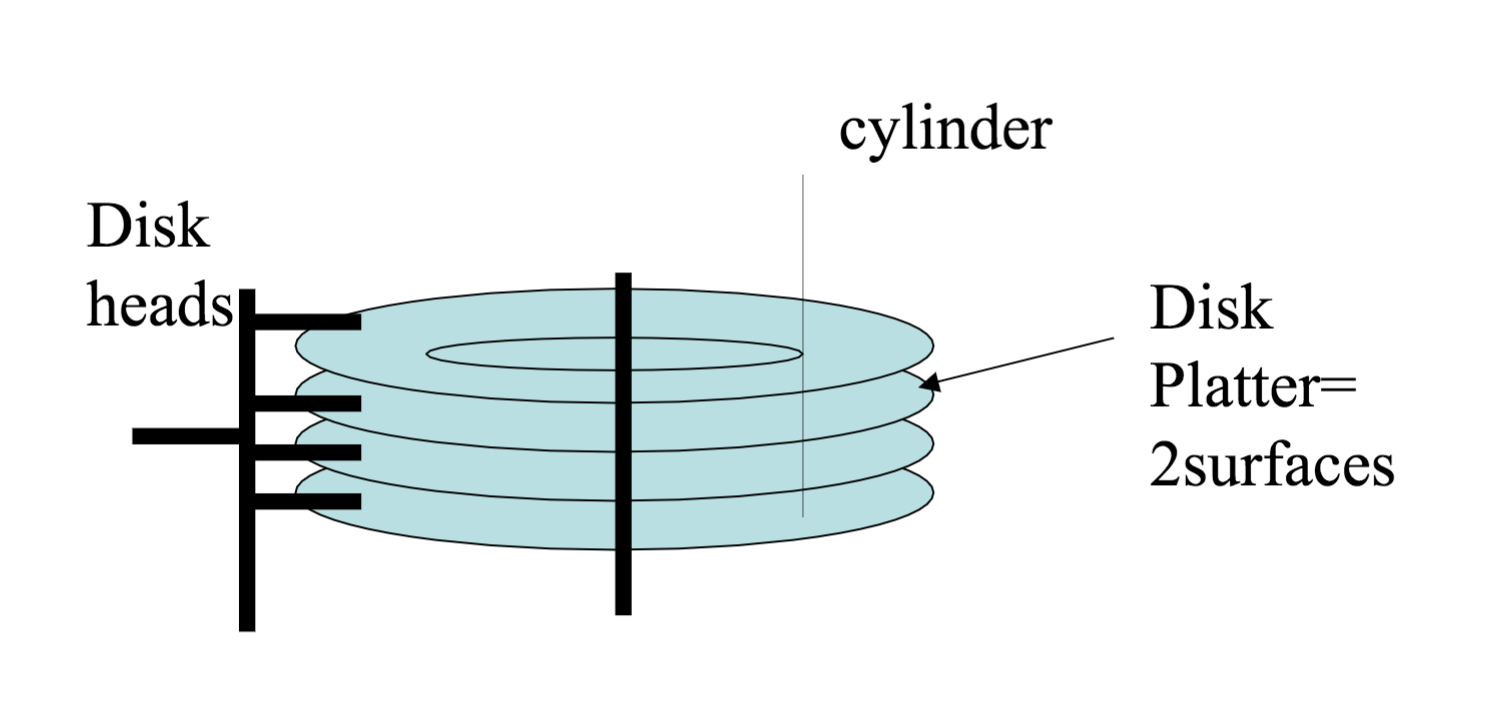
A disk controller is a small processor in an HDD capable of:
Which of the following statements is true?