










Neural Nets
CS156
Chris Pollett
May 9, 2012
CS156
Chris Pollett
May 9, 2012
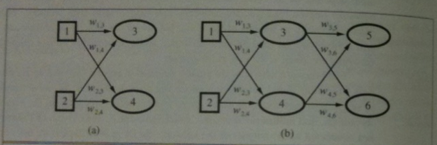
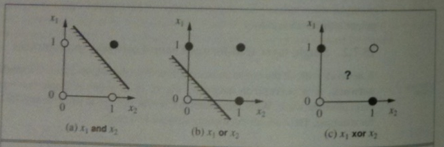
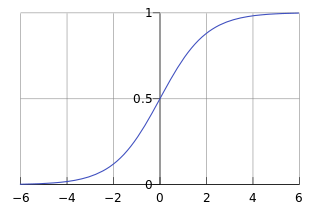
Putting this all together we get the following algorithm:

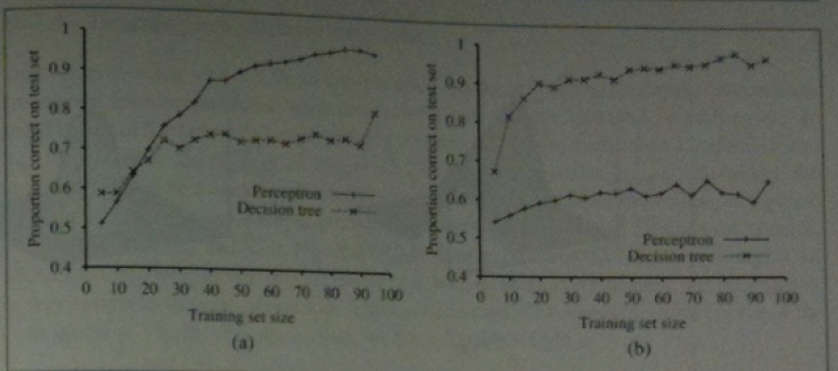
The book has a graph showing that decision tree learning in the restaurant example is only slightly better than using a feed-forward network.