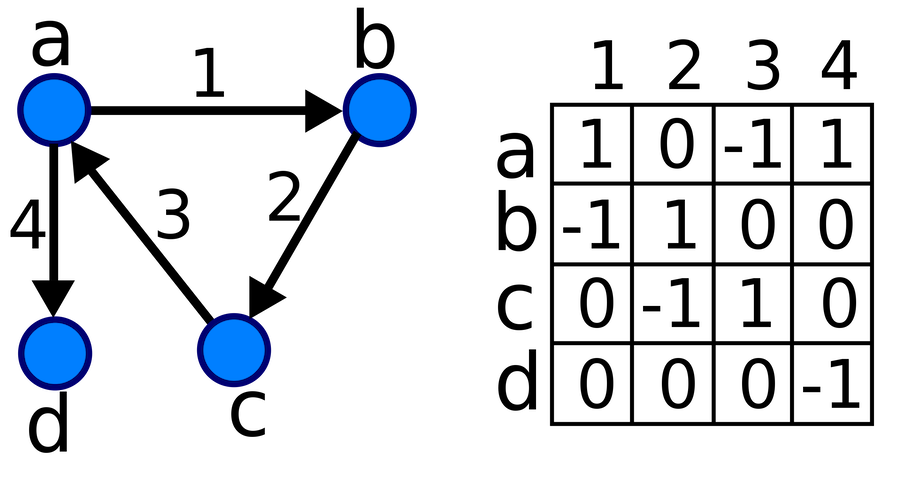
High-Level Parallel Algorithm for Page Rank
Let epsilon be the constant we used to decide if we stop
Compute initial list of node objects, each with a page_rank field and an adjacency list.
This whole list we'll call current_r and slightly abuse notation to view it as a
vector to which our matrices are applied
do {
Store in distributed file system (DFS) pairs (nid, node) as (old_nid, old_node)
where node is a node object (containing info about a web page)
Do map reduce job to compute A*current_r
where A is the normalized adjacency matrix
Store result in DFS as pairs (nid, node) where node has its page_rank field set to the
value given by the above operation.
Do map reduce job to compute dangling node correction to current_r
Store result in DFS as (nid, node) where where node has its page_rank field set to the
value given by the above operation.
Do map reduce job to compute teleporter correction to current_r
Store result in DFS as (nid, node) where where node has its page_rank field set to the
value given by the above operation.
Send all pairs (nid, node) in DFS computed above to reduce job which
computes (nid, node) in which node has a page_rank equal to the sum of the three
page_ranks that one would have grouping by nid.
Store result in DFS as pairs (nid, node).
Do map reduce job to compute len = || current_r - old_r||
} while(len > epsilon)
output nodes with their page ranks
- As we can see, we iteratively apply map reduce jobs to data stored in the distributed file system
- The amount of space we need to store stuff in the DFS is proportional to the nonzero entries in `A` and `vec(r)`.
- Howard Karloff, Siddharth Suri, and Sergei Vassilvitskii (2010) studied what kinds of computations can be done by iteratively
applying map reduce jobs `t` times , where each machine can store at most `n^(1 - epsilon)` of the input. They get the following interesting result:
Any CREW PRAM (concurrent read exclusive write parallel random access machine) algorithm using `O(n^(2 - 2 epsilon))` total memory, `O(n^(2 - 2 epsilon))` processors, and `t = t(n)` time can be run in `O(t)` rounds of map reduce jobs like we have described.