Outline
- Slidy
- Information Retrieval and Applications
- Basic Architecture
- Documents and Update Model
- Probability Ranking Principle
Using Slidy
- The slides for this class are HTML files which both validate as HTML 5 and pass the WAVE Accessibility Checker.
- They are made to look like slides using a Javascript called Slidy.
- The following keystrokes do useful things in Slidy:
- h - help (see all the commands)
- f - fullscreen (gets rid of the links at the bottom of the window
- space - advance a slide
- left/right arrows - forward or back a slide
- up/down arrows - scroll within a slide
- a - show all slides at once for printing
- u - up to the list of lectures
Information Retrieval and Applications
- IR is concerned with representing, searching, and manipulating large collections of text and data.
- Common applications include:
- Web search
- Desktop, email, and filesystem search
- Document Management Systems for businesses.
- Digital Libraries.
- Document Filtering such as News Aggregation.
- Text Clustering and Categorization
- Summarization
- Question Answering
- Multimedia Retrieval
Basic Architecture
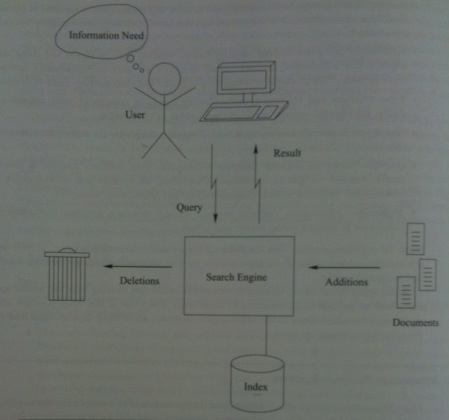
- A user has an information need called a topic and issues a query to
the IR system to try to satisfy this need.
- A query typically consists of a small number of search terms (may or may not be words -- could be dates wildcards, etc).
- The user's query is processed by a search engine. This may be on the user's machines, or may be on one or more machines
accessed over an internet.
- A major task of the search engine is to maintain and provide access to an inverted index for a document collection,
the "database" of the search engine. This index provides a mapping between terms and documents that contain those terms. The size of the
inverted index is typically about the same size as that of all the documents which are stored. So one has to be very clever in order to get
information out of it quickly.
- The search engine processes the query and computes a ranked list of results according to a score calculated for each found document.
It then attempts to remove duplicates from the results so far and finally returns what's left to the user.
Documents and the Update Model
- For the purposes of this class when we say the word document, we mean it as a generic term to refer to any self-contained unit that can be returned to the user as a search result.
- For example, it might be an e-mail message, a web page, a news article, or even a video.
- When sub-parts of a larger object may be returned as an individual search results, we refer to the sub-part as an element.
For example, a paragraph or page from a book.
- When arbitrary text passages, video segments, or similar material may be returned from a larger object it is called a snippet.
- In our picture from an earlier slide, notice that documents can be added and deleted from the search engine's document collection. How this is done is called the update model of the IR system.
Performance Evaluation
- Two common ways to evaluate an IR system's performance are: efficiency and effectiveness.
- Efficiency is measured in terms of time (seconds per query) and space (bytes per document).
- Response time (time between query and results) and throughput (queries per second) are two statistics which are often cited
for efficiency.
- As an example, according to Searchengineland.com, as of 2015, Google handles
about 40,000 queries/second (I've seen a number of non-clearly sourced reports it was about 63,000 qps in 2020, I've also seen sites like internetlivestats indicate that the volume has pretty much plateau'ed).
- Other measures of efficiency include such things as the power consumed by the machines needed to generate the search results and their
overall carbon footprint.
- Effectiveness is harder to measure than efficiency since it depends on human judgment.
- One commonly used notion of effectiveness is that of relevance. A document is considered relevant to a given query if its content satisfy the information need represented by the query.
- To determine this an assessor reviews document/topic pairs and assigns a relevance value. These values might be either binary or graded.