Client-Server Architectures
A Client-Server Architecture consists of two types of components: clients and servers. A server component perpetually listens for requests from client components. When a request is received, the server processes the request, and then sends a response back to the client. Servers may be further classified as stateless or stateful. Clients of a stateful server may make composite requests that consist of multiple atomic requests. This enables a more conversational or transactional interactions between client and server. To accomplish this, a stateful server keeps a record of the requests from each current client. This record is called a session.
In order to simultaneously process requests from multiple clients, a server often uses the Master-Slave Pattern. In this case the Master perpetually listens for client requests. When a request is received, the master creates a slave to processes the request, and then resumes listening. Meanwhile, the slave performs all subsequent communication with the client.
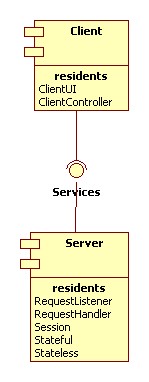
Here is a simple component diagram showing a server component that implements operations specified in a Services interface, and a client component that depends on these services.
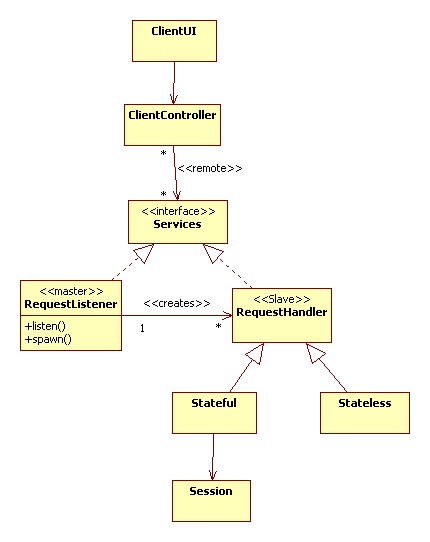
Internally, the client component may consist of a ClientUI that forwards user requests to a controller component. The controller component forwards the request across a process or machine boundary to a RequestListener inside the server. The listener, which acts like a master, creates a RequestHandler slave and forwards the request to it:
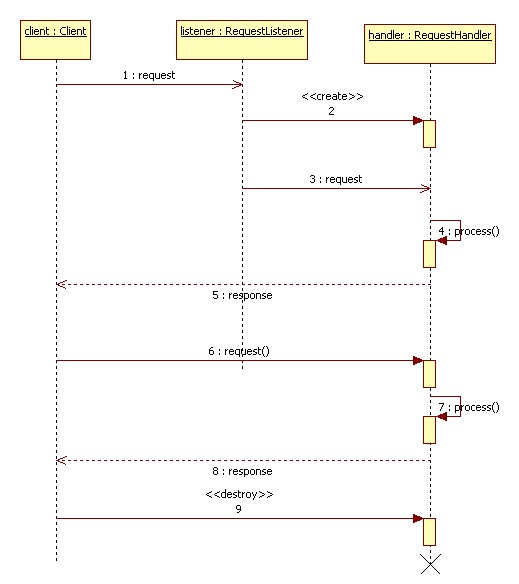
The following sequence diagram shows a typical client-server interaction:
Example: A Simple Client-Server Framework
Proxies
Suppose we want to add features to a server. The obvious way to do this would be to create a derived class with the added features:
class SpecialCommandServer extends CommandServer {
// added features
}
Of course this doesn't add features to the original server. Instead, we must create new servers that instantiate the derived class.
Another approach uses the idea of the Decorator pattern introduced in Chapter 4. Instead of creating a server object that instantiates a derived class, we place a decorator-like object called a proxy between the client and the server. The proxy intercepts client requests, performs the additional services, then forwards these requests to the server. The server sends any results back to clients through the proxy.
The proxy implements the same interface as the server, so from the client's point of view the proxy appears to be the actual server. Of course the proxy has no way of knowing if the server it delegates to is the actual server or just another proxy in a long chain, and of course the server has no way of knowing if the object it provides service to is an actual client or a proxy. The idea is formalized by the Proxy design pattern:
Proxy [POSA], [Go4]
Other Names
Proxies are also called surrogates, handles, and wrappers. They are closely related in structure, but not purpose, to adapters and decorators.
Problem
1. A server may provide the basic services needed by clients, but not administrative services such as security, synchronization, collecting usage statistics, and caching recent results.
2. Inter-process communication mechanisms can introduce platform dependencies into a program. They can also be difficult to program and they are not particularly object-oriented.
Solution
Instead of communicating directly with a server, a client communicates with a proxy object that implements the server's interface, hence is indistinguishable from the original server. The proxy can perform administrative functions before delegating the client's request to the real server or another proxy that performs additional administrative functions.
Structure
To simplify creation of proxies, a Proxy base class can be introduced that facilitates the creation of delegation chains:
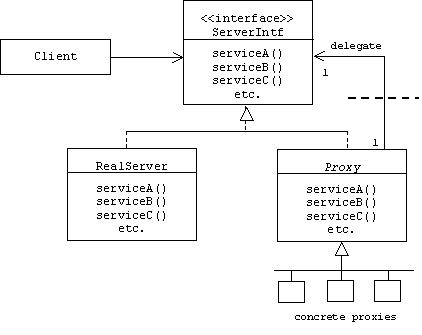
The class diagram suggests that process or machine boundaries may exist between proxies. Proxies that run in the same process or on the same machine as the client are called client-side proxies, while proxies that run in the same process or on the same machine as the server are called server-side proxies.
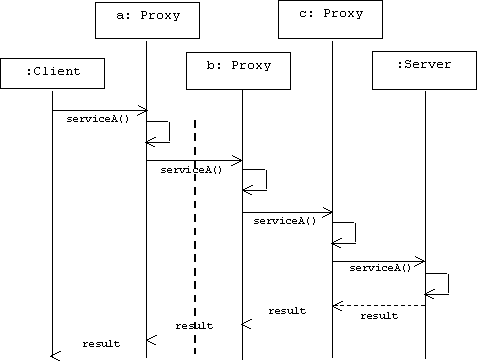
Scenario
As in the decorator pattern, proxies can be chained together. The client, and each proxy, believes it is delegating messages to the real server:
Examples of Client-Side Proxies
A firewall proxy is essentially a filter that runs on the bridge that connects a company network to the Internet. It filters out client requests and server results that may be inconsistent with company policies. For example, a firewall may deny a local web browser's request to download web pages from sites considered to host non work-related material such as today's Dilbert cartoon.
A cache proxy is a client-side proxy that searches a local cache containing recently received results. If the search is successful, the result is returned to the client without the need of establishing a connection to a remote server. Otherwise, the client request is delegated to the server or another proxy. For example, most web browsers transparently submit requests for web pages to a cache proxy, which attempts to fetch the page from a local cache of recently downloaded web pages.
Virtual proxies provide a partial result to a client while waiting for the real result to arrive from the server. For example, a web browser might display the text of a web page before the images have arrived, or a word processor might display empty rectangles where embedded objects occur.
Examples of Server-Side Proxies
Protection proxies can be used to control access to servers. For example, a protection proxy might be inserted between the CIA's web server and the Internet. It demands user identifications and passwords before it forwards client requests to the web server.
A synchronization proxy uses techniques similar to the locks discussed earlier to control the number of clients that simultaneously access a server. For example, a file server may use a synchronization proxy to insure that two clients don't attempt to write to the same file at the same time.
High-volume servers run on multiple machines called server farms. A load balancing proxy is a server-side proxy that keeps track of the load on each server in a farm and delegates client requests to the least busy server.
Counting proxies are server-side proxies that maintain usage statistics such as hit counters.
Remote Proxies and Remote Method Invocation
Communicating with remote objects through sockets is awkward. It is entirely different from communicating with local objects, where we can simply invoke a member function and wait for a return value. The socket adds an unwanted layer of indirection, it restricts us to sending and receiving strings, it exposes the underlying communication protocol, and it requires us to know the IP address or DNS name of the remote object.
A remote proxy encapsulates the details of communicating with a remote object. This creates the illusion that no process boundary separates clients and servers. Clients communicate with servers by invoking the methods of a client-side remote proxy. Servers communicate with clients by returning values to server-side remote proxies. This is called Remote Method Invocation or RMI.
For example, a client simply invokes the member functions of a local implementation of the server interface:
class Client
{
ServerIntf* server;
public:
Client(ServerIntf* s = 0);
CResult taskA(X x, Y y, Z z)
{
return server->serviceA(x, y, z);
}
// etc.
};
Internally, the client's constructor creates a client-side remote proxy, which is commonly called a stub:
Client::Client(ServerIntf* s /* = 0 */)
{
server = (s? s: new Stub(...));
}
Stubs use IPC mechanisms such as sockets to forward client requests to server-side remote proxies, which are commonly called skeletons. A Java skeleton customizes a Java version of our server framework and implements the server interface by delegating to a real server:
class Skeleton implements ServerIntf extends Server
{
private ServerIntf server = new
RealServer();
protected SkerverSlave makeSlave(Socket
s)
{
return new SkeletonSlave(s, this);
}
public JResult serviceA(U u, V v, W w)
{
return server.serivceA(u, v, w);
}
// etc.
}
The real server simply returns computed results to its local caller, the skeleton. Therefore, the server doesn't need to depend on any special inter-process communication mechanism:
class RealServer implements ServerIntf
{
public JResult serviceA(U u, V v, W w)
{
JResult result = ...; // compute
result
return result;
}
// etc.
};
The skeleton slave handles the communication with the client's stub and invokes the appropriate methods of its master, the skeleton:
class SkeletonSlave extends ServerSlave
{
protected boolean update()
{
receive request from client;
call corresponding method of
skeleton (= master);
send result back to client;
}
// etc.
}
Remote proxies can be quite complex. In our example, the message sent from the stub to the skeleton includes the name of the requested service, "serviceA," and the parameters: x, y, and z. Of course x, y, and z need not be strings. They might be C++ numbers (in which case the stub will need to converted them into strings by inserting them into string streams) or they might be arbitrary C++ objects (in which case the stub will need to serialize them using the techniques of Chapter 5). This process is called marshalling.
The problem is even more complicated in our example because the server implementation is apparently a Java object, not a C++ object. Thus, after the skeleton deserializes x, y, and z, it will have to translate them into Java data. For example, an ASCII string representing a C++ number will have to be converted into a Java Unicode sting, probably using Java character streams, then the Java string must be converted into a Java number. This process is called de-marshalling.
Of course the skeleton must marshal the result before sending it back to the stub, and the stub must de-marshal the result before returning it to the client.
Finally, the reader may well ask how the skeleton knows a received request is a string containing C++ parameters and therefore C++ to Java translation should be performed, or how does the stub know a received result is a string containing Java data and therefore Java to C++ translation should be performed? Remember, clients and servers are often developed independently.
One way to solve this problem is for all programmers to agree on a common object oriented language, let's call it COOL. Marshalling must include translating data from the implementation language into COOL, and de-marshalling must include translating data from COOL into the implementation language.
Of course getting programmers to agree on what COOL should be is difficult. The Object Management Group (OMG), is promoting a standard called the Interface Description Language, IDL. An IDL description of ServerIntf looks an awful lot like a C++ header file. Compilers are available that will automatically translate IDL interfaces into stubs and clients in most object oriented languages, including Java and C++. Microsoft is promoting a standard called the Component Object Model (COM). COM interfaces are objects that can be discovered by clients at runtime through a COM meta interface.
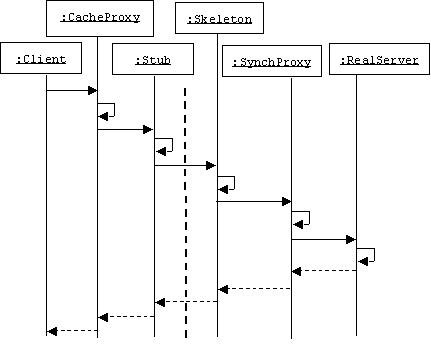
Dynamics
In the following scenario we enhance a real server by adding four proxies between it and a client. On the client side we have a cache proxy and a stub. On the server side we have a skeleton and a synchronization proxy. The stub and skeleton perform parameter marshalling and de-marshalling.