1. The eXstensible Markup Language (XML)
References
The W3C XML 1.0 recommendation can be found at:
The W3C XML 1.1 recommendation can be found at:
XML Design Goals
The design goals
for XML are:
1.
XML
shall be straightforwardly usable over the Internet.
2.
XML
shall support a wide variety of applications.
3.
XML
shall be compatible with SGML.
4.
It
shall be easy to write programs which process XML documents.
5.
The
number of optional features in XML is to be kept to the absolute minimum,
ideally zero.
6.
XML
documents should be human-legible and reasonably clear.
7.
The
XML design should be prepared quickly.
8.
The
design of XML shall be formal and concise.
9.
XML
documents shall be easy to create.
10.
Terseness
in XML markup is of minimal importance.
(SGML = Standard Generalized Markup Language, the forerunner of XML and HTML).
Goals 4 and 6 are the most significant. While HTML documents are human-legible, it's difficult to write programs that process HTML documents. This is because the markup in an HTML document (i.e., HTML elements such as forms, tables, anchors, images, paragraphs, etc.) focuses on how the information contained in the document should be presented by a web browser, not on the document's logical structure.
We shall see that XML documents allow authors to markup the logical structure of the document. This makes it easy to write programs (called XML processors) that can quickly extract relevant information.
For example, smith.xml is an XML document containing Joe Smith's resume. Educational background, prior work experience, references, and contact information are clearly indicated by markup tags:
<resume>
<contact-info> ...
</contact-info>
<education> ...
</education>
<experience> ...
</experience>
<references> ...
</references>
</resume>
It's a simple matter to write programs that extract this information and process it in different ways. One common task is to convert this document into an HTML document:

Why not simply create smith.html by hand in the first place? Note that a different processor might convert smith.xml into a completely different HTML document, perhaps a Spanish version, or perhaps even a PDF document more suitable for hardcopies. Changes to the resume, for example changes to Smith's address, only need to be made in smith.xml.
XML Documents
An XML document consists of (::=) an optional prolog followed by a root element:
document ::= (prolog?, element)
The XML Prolog
The prolog consists of an XML declaration followed by an optional document type definition, or DTD (DTDs will be discussed later). Miscellaneous comments and processing instructions may also occur in the prolog:
prolog ::= (declaration, misc*, dtd?, misc*)
misc ::= (comment | pi)
Notation: '*' = 0 or more, '+' = 1 or more, '?' = 0 or 1, ',' = AND, '|' = OR, '::=' = consists of.
Here's a sample XML declaration:
<?xml version = "1.0" encoding = "UTF-16" standalone = "yes"?>
All of the attributes in the declaration are optional, including the declaration itself. Most declarations include the XML version number. The current versions of XML are 1.0 and 1.1. When multiple versions of XML are in common use, declaring the version number will enable XML processors to differentiate between older and newer documents.
The encoding attribute allows us to specify the unicode character encoding scheme. All XML processors must be able to process UTF-8 and UTF-16 characters.
The value of the standalone attribute indicates if the internal DTD is complete or if the document depends on an external DTD. The default value is "yes".
Comments and Processing Instructions
An XML comment has the same form as an HTML comment:
<!-- this is an XML comment -->
XML processors ignore XML comments.
A processing instruction (PI) provides processing directions in the form of attribute values to a target XML processor. For example, the following PI tells a style sheet processor which style sheet should be used to process this document:
<?xml:stylesheet type = "text/xsl" href = "outline.xsl"?>
Processing instructions aren't very popular and won't be used much in these lectures. After all, the whole idea of XML is to decouple data (the XML document) from processing.
Elements
An XML element consists of a start tag, optionally followed by content, followed by an end tag. An XML element without content is called an empty element. (Presumably, the start tag of an empty element would contain attributes.) We may drop the end tag of an empty element and replace the start tag with a special empty-element tag:
element ::= (start-tag, content?, end-tag) | empty-elem-tag
A start tag consists of an opening angle brace followed by a tag name, followed by zero or more attributes, and ends with a closing angle brace:
start-tag ::= <(name, attribute*)>
An end tag starts with an opening angle brace with a slash, followed by the same tag name that appeared in the matching start tag, followed by a closing angle brace:
end-tag ::= </name>
An empty element tag consists of an opening angle brace followed by a tag name, followed by one or more attributes, and ends with a slash followed by a closing angle brace:
empty-elem-tag ::= <(name, attribute+)/>
The content of an element consists of a mixture of text, comments, processing instructions, entity references, and more elements:
content ::= (text | comment | pi | entity-ref | element)+
A document is well formed if every start tag has a matching end tag and if elements are properly nested. For example, a document containing the following element would not be well formed for two reasons. What are they?
<memo> <from> Bill <to> Sue </from> </to> Dinner tonight? </meno>
Examples
The following element has pure text content:
<date>March 15, 2003</date>
In the next example the same information is contained in the element attributes. This element has no content. It is an empty element:
<date month = "March" day = "15" year = "2003"/>
Of course an element can have attributes and content. The content can consist of other elements, too:
<name title = "Captain">
<first>
<last>Chesterton</last>
</name>
A mixed content element contains text and other elements as content:
<letter date = "12-25-2003">
Dear <name>Elaine</name>,
The <number>4</number> days we spent together last
<month>October</month> we're wonderful. The reason I never called
you was because <excuse>my phone stopped working</excuse>. I'm
anxious to see you again. Love Jerry.
</letter>
Unparsed Text Nodes
There are two types of text nodes: parsed and unparsed. Most XML parsers ignore any white space characters used to format a parsed text node. To preserve the formatting of a text node, we place the text between special CDATA tags:
<![CDATA[ FORMATTED TEXT ]]>
For example, the following element node has three children: a comment, a parsed text node, and an unparsed (i.e., CDATA) text node:
<example>
<!-- example # 5 -->
Here is what a label looks like:
<![CDATA[
*********
* *
* LABEL *
* *
*********
]]>
</example>
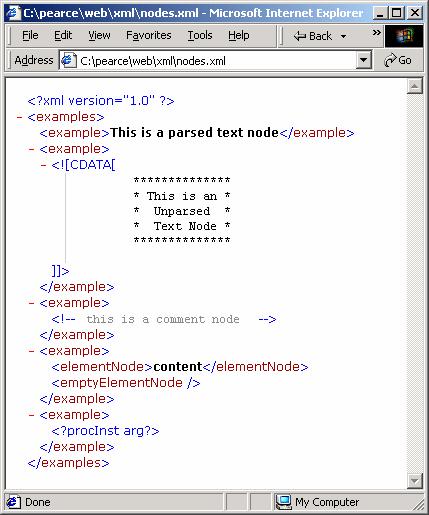
Viewing nodes.xml with IE
The following XML document, called nodes.xml, contains a list of examples. Each example shows a different type of XML node:
<?xml version = "1.0"?>
<examples>
<example>
This is a
parsed text node
</example>
<example>
<![CDATA[
**************
* This is an *
*
Unparsed *
*
Text Node *
**************
]]>
</example>
<example>
<!-- this is a comment node
-->
</example>
<example>
<elementNode> content
</elementNode>
<emptyElementNode/>
</example>
<example>
<?procInst arg?>
</example>
</examples>
Here is how IE displays nodes.xml:
Characters and Entities
Parsed XML text is normalized. This means sequences of white space characters are collapsed into a single white space character.
Entity references can be inserted into parsed XML text to represent Unicodes or XML symbols.
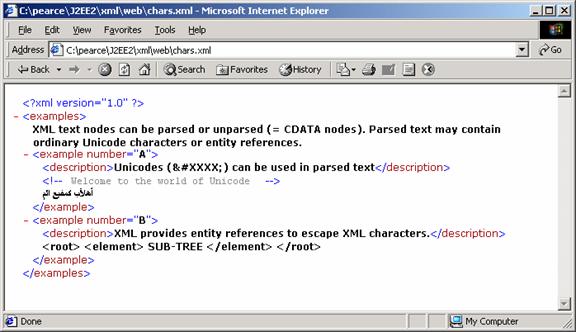
Example: chars.xml
<?xml version="1.0"?>
<examples>
XML text nodes can be parsed or unparsed (= CDATA nodes). Parsed text may
contain ordinary Unicode characters or entity references.
<example number = "A">
<description>
Unicodes (&#XXXX;) can be
used in parsed text
</description>
<!-- Welcome to the world of
Unicode -->
أهلاًب
كمفيِع
الم
</example>
<example number = "B">
<description>
XML provides entity references to
escape XML characters.
</description>
<root>
<element>
SUB-TREE
</element>
</root>
</example>
</examples>
Screenshot of chars.xml
Uniform Resource Identifiers (URIs)
Every resource has a unique name called a Uniform Resource Identifier, or URI. Agents dereference URIs to access resources. (Accessing may include retrieving the state-- get, head, updating the state-- put, post, or deleting the resource-- delete.)
The format of a typical URI is:
scheme:identifier#fragment
A registry of schemes can be found at http://www.iana.org/assignments/uri-schemes. Familiar examples include:
ftp, http, mail-to, telnet, file, news, fax, urn
Examples of URIs from various schemes include:
mailto:joe@example.org (resource is a mailbox)
ftp://example.org/aDirectory/aFile (resource is a file)
news:comp.infosystems.www
tel:+1-816-555-1212
ldap://ldap.example.org/c=GB?objectClass?one
urn:oasis:names:tc:entity:xmlns:xml:catalog
How do URIs differ from traditional URLs (Uniform Resource Locators)? An attempt to clarify this distinction can be found at http://www.w3.org/TR/uri-clarification/, where a distinction is made between the classical view and contemporary view of URIs. In the classical view URIs could be partitioned into URLs and URNs (Uniform Resource Names):
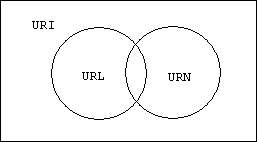
The idea was that a resource could be identified by its location on the web (http://host/path) or simply by its name. Under the contemporary view URIs are partitioned by schemes and the URL/URN distinction seems to be dead.
When talking about URIs, people seem to take a very broad view of what is meant by a resource. For example, a URI doesn't have to identify a network resource. It can also identify a physical object such as a book (isbn scheme) or a person (ssn scheme).
XML Languages
The XML standard doesn't impose any constraints on the format of an XML document other than the requirement that it must be well formed. XML authors are free to include any types of elements they choose. This much freedom can make it difficult for software agents to understand XML documents. For this reason XML authors may impose additional constraints upon themselves. These additional constraints restrict the tags and attributes of elements as well as the syntactic structure of their content. We can think of this collection of additional constraints as a definition of an XML language or vocabulary.
The additional constraints can be spelled out in the document type definition (DTD) component of an XML document's prolog. In this case certain parsers will not only verify that a document is well formed, they will also verify that the document conforms to the constraints described in the DTD. A document that conforms to a DTD is called valid.
DTDs will b e discussed later.
Public and Local Vocabularies
XML languages can be public or local. A local language is developed by an individual or company for internal use. We have seen that it is an easy to provide a program that converts documents from one XML language to another. In particular, it is easy to provide a program that converts documents that conform to Company A's local XML languages to documents conforming to Company B's local XML languages.
A public XML language is a de facto standard maintained by a consortium of individuals and companies. There are several advantages to public languages. They spare users the (big) step of defining their own XML language. More significantly, tools exist for processing many public languages. A registry of public languages is maintained by xml.org at:
http://www.xml.org/xml/registry.jsp
In addition, W3C recommendations also include a number of public languages including XHTML, MathML, and SVG.
Foreign Elements and Namespaces
One of the great features of XML is the ability to include "foreign" elements into XML documents much the same way that natural languages may include foreign words. For example, a certain lab requires all researchers to submit their lab reports in XML format. Toward that end the lab has developed a local XML language called LabML. Informally, a LabML report has the format:
<experiment date = "...">
<introduction>...</introduction>
<equipment-list>...</equipment-list>
<procedure>...</procedure>
<data>...</data>
<analysis>...</analysis>
<summary>...</summary>
</experiment>
A researcher may need to include chemical formulas, mathematical formulas, diagrams, and links to other documents. Instead of adding new elements, LabML allows foreign elements to occur in documents. Thus, the researcher may use elements in a local language called ChemML for representing chemical formulas, he may include elements and attributes from the public languages MathML, SVG, and XLink to represent mathematical formulas, diagrams, and links, respectively. For example:
<experiment date = "03-15-2003">
<introduction>
The compound under investigation is
common water:
<molecule>
<atom symbol="H"
number ="2"/>
<atom symbol="O"
number ="1"/>
</molecule>
It boils at 100 degrees and freezes at
0 degrees!
For more information about this amazing
compound
see the March 2003 issue of:
<reference
type = "simple" href = "http://www.ww.com">
Water World
</reference>
</introduction>
<!-- etc -->
</experiment>
Not only does this save the work of defining the structure of these specialized elements, it also means that tools that know how to process these types of elements can be used on MathML documents. For example, a tool may exists that knows how to read ChemML molecule elements and generate a graphic model of the molecule. A special browser may know how to traverse links.
There are two problems, however. First, how does the tool that models ChemML molecules know for sure that a particular element with "molecule" start and end tags is actually a molecule from the ChemML language and not some other language? Second, what if the name of a foreign element or attribute is the same as the name of a local element or attribute.
For example, assume LabML dictates that a reference element contains a type attribute that specifies if the reference is a book, journal, or web site.
<reference
type = "web-site"
type = "simple"
href =
"http://www.ww.com">
Water World
</reference>
Unfortunately, this conflicts with the type attribute required by the XLink language that requires a type tag specifying if the type of link (simple, arc, locator, local, etc.).
Both problems are solved using namespace declarations. A namespace is an arbitrary name chosen by the creator of an XML language. Names of all tags and attributes are understood to belong to the namespace. When an author includes a foreign element or attribute he can differentiate it from conflicting tags and attributes by qualifying it with the namespace.
For example, the creators of ChemML may have chosen cml as their namespace. A molecule element appearing in a LabML document would be written as:
<cml:molecule>
<cml:atom symbol="H"
number ="2"/>
<cml:atom symbol="O"
number ="1"/>
</cml:molecule>
Unfortunately, this just moves the problem up a level. Instead of worrying about conflicts between names of tags and attributes, we must worry about conflicts between names of namespaces! There are namespace registries, but a simpler technique is to use URIs. For example, the ChemML namespace could be http://www.sjsu.edu/xml/cml (a hipper choice would be urn://www.sjsu.edu/xml/cml). Now a molecule has the form:
<http://www.sjsu.edu/xml/cml:molecule>
<http://www.sjsu.edu/xml/cml:atom
symbol="H" number ="2"/>
<http://www.sjsu.edu/xml/cml:atom
symbol="O" number ="1"/>
</http://www.sjsu.edu/xml/cml:molecule>
This is a bit unwieldy. Fortunately, we can have our cake and eat it too. The name xmlns is a reserved attribute name that can be used for assigning local abbreviations to namespace URIs:
<experiment date = "03-15-2003"
xmlns:cml =
"http://www.sjsu.edu/xml/cml"
xmlns:xlink =
"http://www.w3.org/1999/xlink"
xmlns =
"http://www.sfsu.edu/xml/lab">
<introduction>
The compound under investigation is
common water:
<cml:molecule>
<cml:atom
symbol="H" number ="2"/>
<cml:atom
symbol="O" number ="1"/>
</cml:molecule>
It boils at 100 degrees and freezes at
0 degrees!
For more information about this amazing
compound
see the March 2003 issue of:
<reference
type = "web-site">
xlink:type =
"simple"
xlink:href =
"http://www.ww.com">
Water World
</reference>
</introduction>
<!-- etc -->
</experiment>
The last xmlns declaration declares that http://www.sfsu.edu/xml/lab is the default namespace. In other words, all unqualified tag and attribute names are assumed to belong to this namespace. (This would include the reference tag and the first type attribute.
Notice that it was not necessary to qualify the attributes of the molecule element because the tag is already qualified. There is, however, nothing wrong with this practice:
<cml:atom cml:symbol="H" cml:number ="2"/>
The W3C Namespace recommendation can be found at:
http://www.w3.org/TR/REC-xml-names/
Example
For example, the following ComposerML document, called mozart.xml, incorporates elements from the SynthesizerML language:
<composer title = "Meistro" name =
"Mozart">
<note> Mozart died at a very
young age </note>
<score>99/100</score>
<!-- one of my favorites! -->
<samples>
<score title = "The Jupiter
Symphony">
<note frequency =
"120Hz" duration = "0.5s"/>
<note frequency =
"100Hz" duration = "0.3s"/>
<note frequency =
"100Hz" duration = "0.3s"/>
<!-- etc. -->
</score>
<!-- etc. -->
</samples>
</composer>
The author hoped that mozart.xml could be fed to programs that play SynthesizerML scores on synthesizers. Unfortunately, the numerous name collisions hopelessly confuse such programs.
For example, assume all elements from the SynthesizerML language belong to a namespace identified by the URI:
http://www.emu.com/synthesizerML
Furthermore, assume all elements from ComposerML belong to a namespace identified by the URI:
http://www.music-lovers.org/composerML
We can now resolve the ambiguities in mozart.xml:
<com:composer
xmlns:com = "http://www.music-lovers.org/composerML"
xmlns:syn = "http://www.emu.com/synthesizerML"
com:title = "Meistro"
com:name = "Mozart">
<com:note> Mozart died at a very
young age </com:note>
<com:score>99/100</com:score>
<!--one of my favorites! -->
<com:samples>
<syn:score title = "The
Jupiter Symphony">
<syn:note syn:frequency =
"120Hz" syn:duration = "0.5s"/>
<syn:note syn:frequency =
"100Hz" syn:duration = "0.3s"/>
<syn:note syn:frequency =
"100Hz" syn:duration = "0.3s"/>
<!-- etc. -->
</syn:score>
<!-- etc. -->
</com:samples>
</com:composer>
Alternatively, if the vast
majority of names in mozart.xml are from the ComposerML namespace, the author
might choose to make this the default namespace:
<composer
xmlns =
"http://www.music-lovers.org/composerML"
xmlns:syn =
"http://www.emu.com/synthesizerML"
title = "Meistro"
name = "Mozart">
<note> Mozart died at a very
young age </note>
<score>99/100</score>
<!--one of my favorites! -->
<samples>
<syn:score title = "The
Jupiter Symphony">
<syn:note syn:frequency =
"120Hz" syn:duration = "0.5s"/>
<syn:note syn:frequency =
"100Hz" syn:duration = "0.3s"/>
<syn:note syn:frequency =
"100Hz" syn:duration = "0.3s"/>
<!-- etc. -->
</syn:score>
<!-- etc. -->
</samples>
</composer>
XML Design Patterns
When data in a system needs to be imported or exported, it needs some type of representation. XML can be an appropriate choice when one or more of the following is needed:
Content needs to be separate from its formatting.
Data is shared between computers, applications or organizations.
Human readable representation is needed.
Readily available tools and resources.
There are some situations where XML may not be a good choice, among them is systems where:
Terseness is important.
In a homogeneous environment.
Complicated queries need to be made against the data
The data frequently needs to be updated
There are many places where XML is being used successfully. Here is a small sampling of them.
Data syndication
Data exchange protocols for transport of messages from one system to another across a network.
Configuration files
Test Scripting
Log files
Web content management
Classifying XML Documents
XML documents tend to fall into one of three families: document, data, and command oriented.
Document-Oriented
<html> ... </html>
<report> ... </report>
<invoice> ... </invoice>
<chapter> ... </chapter>
Data Oriented
<employee> ... </employee>
<measurement> ... </measurement>
<organization> ... </organization>
Command Oriented
<deposit> ... </deposit>
<transfer> ... </transfer>
<invoke> ... </invoke>
<render> ... </render>
Data Structures
Consider using standard data structures such as records, lists, graphs, trees, and tables as XML elements.
Records
<record type = "student">
<field name = "name">
Joe Smith </field>
<field name = "gpa">
2.3 </field>
<field name = "class">
Sophmore </field>
<!-- etc -->
</record>
Or, less generically:
<student>
<name> Joe Smith </name>
<gpa> 2.3 </gpa>
<class> Sophmore </class>
<!-- etc -->
</student>
Lists
Lists can be implicitly ordered by their position in the document (document order):
<items>
<item> 100 </item>
<item> 200 </item>
<item> 300 </item>
<item> 400 </item>
<item> 500 </item>
</items>
Or the order can be made explicit:
<items>
<item id = "id4">
<data> 400 </data>
<prev ref = "id3"/>
<next ref = "id5"/>
</item>
<item id = "id1">
<data> 100 </data>
<next ref = "id2"/>
</item>
<item id = "id5">
<data> 500 </data>
<prev ref = "id4"/>
</item>
<item id = "id2">
<data> 200 </data>
<prev ref = "id1"/>
<next ref = "id3"/>
</item>
<item id = "id3">
<data> 300 </data>
<prev ref = "id2"/>
<next ref = "id4"/>
</item>
</items>
Networks
XLink already exists for describing graphs (i.e., networks).
TableML
HTML already has a table element, which we mimic here.
<table>
<caption> 2003 Budget
</caption>
<headers>
<column> Pens </column>
<column> Paper
</column>
<column> Paper Clips
</column>
</headers>
<row header = "May">
<column>
<quantity amount =
"43.25" units = "usd"/>
</column>
<column>
<quantity amount =
"28.12" units = "usd"/>
</column>
<column>
<quantity amount =
"10.10" units = "usd"/>
</column>
</row>
<row header = "June">
<column>
<quantity amount =
"25.66" units = "usd"/>
</column>
<column>
<quantity amount =
"44.00" units = "usd"/>
</column>
<column>
<quantity amount =
"19.22" units = "usd"/>
</column>
</row>
<row header = "July">
<column>
<quantity amount =
"43.25" units = "usd"/>
</column>
<column>
<quantity amount =
"28.12" units = "usd"/>
</column>
<column>
<quantity amount =
"10.10" units = "usd"/>
</column>
</row>
</table>
Trees
Trees are good for representing hierarchies such as organizations, assemblies, and taxonomies:
<car>
<engine temperature =
"180">
<carburetor/>
<cylinder/>
<cylinder/>
<cylinder/>
<cylinder/>
</engine>
<dashboard>
<speedometer/>
<radio>
<cd-player/>
<tape-player>
<tape-head/>
</tape-player>
</radio>
</dasboard>
<transmission>
<shifter/>
<gear num = "1"/>
<gear num = "2"/>
<gear num = "3"/>
<gear num = "R"/>
</transmission>
</car>
Domain Modeling
An application domain-- or simply a domain-- is the real world context of some computer applications. Examples of domains include health care domains (hospitals, clinics, insurance companies, etc.), manufacturing domains (factories, warehouses, etc.), business domains (retailers, wholesalers, contractors, etc.), scientific domains (ecosystems, galaxies, experiments, labs, etc.), legal domains, military domains, academic domains, government domains, etc.
A domain model, or ontology, is a formal representation of all or part of an application domain. Various domain modeling languages are in common use: UML, Entity-Relationship diagrams, first-order logic, etc.
We can think of an XML document or a collection of XML documents as a domain model. We start by identifying the important entities, events, roles, and descriptions in the domain being modeled.
Entities
Entities such as persons, places, and things, should have a unique identifier. If the entity is an element in a larger document, this can be an ID attribute:
<person ssn = "ssn222-33-4444">
<name> Ed Smith </name>
</person>
<product upc = "upc1324">
<name> Weed Whacker 2000
</name>
</product>
If the entity is contained in its own document, then its URL can be used to locate it:
http://www/demo.com/smith.xml
We can even make up a URL:
<dvd id = "http://blockbuster/inventory/item3214"/>
When representing an entity, try not to explicitly represent derived properties-- i.e., properties that can be computed:
<rectangle height = "20" width = "50">
<ul-corner xc = "-12.3" yc
= "10"/>
</rectangle>
Note that we can compute the position of the other corners as well as area and perimeter.
Descriptions
A description
<description id =
"http://blockbuster/movies/matrix">
<title> The Matrix </title>
<starring> Keaneau Reeves
</starring>
<!-- etc -->
</description>
It's often useful to think of types as descriptions. In an application domain roles, phenomena, units, and roles can be regarded as types/descriptions:
<quantity amount = "43.25" units = "usd"/>
Events
An event, such as a transaction, observation, etc, should use standard XML schema representations of times and durations:
durations: PaYbMcDTdHeM
times: HH:MM:SS.SSS
dates: CCYY-MM-DD
dateTimes: CCYY-MM-DDTHH:MM:SS
Here's a generic event:
<event>
<description> Third XML lecture
</description>
<start time =
"2003-08-26T13:00:05"/>
<!-- end time is optional -->
<end time =
"2003-08-26T16:01:00.3"/>
</event>
Here's an event that combines quantity, roles, and type:
<measurement>
<quantity amount = "98.6"
units = "degrees Fahrenheit"/>
<at time =
"2003-08-26T16:01:00.3"/>
<observer ref =
"id46"/>
<subject ref = "id2983"/>
<phenomenon> body temperature
</phenomenon>
</measurement>
Actors and Roles
<role>
<title> Manager </title>
<description> Manager of software
development </description>
<actor ref = "id28"/>
<organization ref =
"id4444"/>
<supervisor ref = "id49"/>
<supervises ref =
"id18"/>
<supervises ref =
"id28"/>
</role>
Containers, Collections, and Marketplaces
Consider the following XML document:
<employees>
<manager> Joe Smith
</manager>
<programmer> Bill Edwards
</programmer>
<manager> Betty Kline
</manager>
<secretary> Harry James
</secretary>
<programmer> Tim
<secretary> Ann Boone
</secretary>
<!-- etc. -->
</employees>
In some situations it might make sense to add structure by introducing containers corresponding to the types of employees:
<employees>
<managers>
<manager> Joe Smith
</manager>
<manager> Betty Kline
</manager>
</managers>
<programmers>
<programmer> Bill Edwards
</programmer>
<programmer> Tim
</programmers>
<secretaries>
<secretary>
Harry James </secretary>
<secretary> Ann Boone
</secretary>
</secretaries>
<!-- etc. -->
</employees>
Instead of introducing more hierarchy, we can introduce type attributes:
<employees>
<employee pos =
"manager"> Joe Smith </employee>
<employee pos =
"programmer"> Bill Edwards </employee>
<employee pos =
"manager"> Betty Kline </employee>
<employee pos =
"secretary"> Harry James </employee>
<employee pos =
"programmer"> Tim Burton </employee>
<employee pos =
"secretary"> Ann Boone </employee>
<!-- etc. -->
</employees>
Suppose we add a department attribute to our document. This is called a marketplace:
<employees>
<employee pos = "manager"
dept = "marketing">
Joe Smith
</employee>
<employee pos =
"programmer" dept = "development">
Bill Edwards
</employee>
<employee pos = "manager"
dept = "development">
Betty Kline
</employee>
<employee pos =
"secretary" dept = "marketing">
Harry James
</employee>
<employee pos =
"programmer" dept = "development">
Tim Burton
</employee>
<employee pos =
"secretary" dept = "development">
Ann Boone
</employee>
<!-- etc. -->
</employees>
We might want to add collections to eliminate duplication of attributes:
<employees>
<marketing>
<employee pos =
"manager"> Joe Smith
</employee>
<employee pos =
"secretary"> Harry James </employee>
<employee pos =
"programmer"> Tim Burton </employee>
</marketing>
<development>
<employee pos =
"programmer"> Bill Edwards </employee>
<employee pos =
"manager"> Betty Kline </employee>
<employee pos =
"secretary"> Ann Boone </employee>
</development>
<!-- etc. -->
</employees>
Referencing Elements
Consider the following XML document
<books>
<book>
<title> The Dubliners
</title>
<author> James Joyce
</author>
</book>
<book>
<title> Ulysseys
</title>
<author> James Joyce
</author>
</book>
<book>
<title> Finnegan's Wake
</title>
<author> James Joyce
</author>
</book>
</books>
It might be better to use an author reference. There are three ways to do this. The most obvious way is to use identifiers and identifier references:
<books>
<author id = "a10">
James Joyce </author>
<book>
<title ref> The Dubliners
</title>
<author ref = "a10"/>
</book>
<book>
<title> Ulysseys
</title>
<author ref = "a10"/>
</book>
<book>
<title> Finnegan's Wake
</title>
<author ref = "a10"/>
</book>
</books>
Another technique is to use xlinks. Suppose the author information is in some other XML document, say joyce.xml:
<?xml version = "1.0"?>
<author>
<name> James Joyce </name>
<!-- etc. -->
</author>
We can use simple xlinks to reference this document:
<books xmlns:xlink =
"http://www.w3.org/1999/xlink">
<book>
<title ref> The Dubliners
</title>
<author xlink:type =
"simple" xlink:href = "joyce.xml"/>
</book>
<book>
<title> Ulysseys
</title>
<author xlink:type =
"simple" xlink:href = "joyce.xml"/>
</book>
<book>
<title> Finnegan's Wake
</title>
<author xlink:type =
"simple" xlink:href = "joyce.xml"/>
</book>
</books>
Another technique is to use entity references:
<!DOCTYPE Doc[
<!ENTITY JOYCE "James
Joyce">
]>
<books>
<author id = "a10">
James Joyce </author>
<book>
<title ref> The Dubliners
</title>
<author> &JOYCE;
</author>
</book>
<book>
<title> Ulysseys
</title>
<author> &JOYCE;
</author>
</book>
<book>
<title> Finnegan's Wake
</title>
<author> &JOYCE;
</author>
</book>
</books>
Separating Data and Metadata
Consider the following XML document:
<message>
<author> Tod LeBlank
</author>
<date> 2003-12-25 </date>
<language> en </language>
<to> Lucy </to>
<from> Ed </from>
<text>
I will be arriving in
</text>
<salutation> See you soon, Ed
</saluation>
</message>
This document mixes data (to, from, text, salutation) with the metadata-- information about the data. We can use the Head-Body pattern to separate data from metadata:
<message>
<head>
<author> Tod LeBlank
</author>
<date> 2003-12-25
</date>
<language> en
</language>
</head>
<body>
<to>
Lucy </to>
<from> Ed> </from>
<text>
I will be arriving in
</text>
<salutation> See you soon, Ed
</saluation>
</body>
</message>
Consider using standard (Dublin Core) tags for metadata:
<message>
<head xmlns:dc=
"http://dublincore.org/documents/2002/07/31/dcmes-xml/dcmes-xml-xsd.xsd">
<dc:creator> Tod
LeBlank </dc:creator>
<dc:date> 2003-12-25 </dc:date>
<dc:language> en </dc:language>
</head>
<body>
<to>
Lucy </to>
<from> Ed> </from>
<text>
I will be arriving in
</text>
<salutation> See you soon, Ed
</saluation>
</body>
</message>
Use an envelope to separate the message from the transport details:
<envelope
xmlsns:env="http://www.demo.com/envelope">
<env:sender address =
"ed@demo.com"/>
<env:receiver address =
"lucy@bcn.com">
<message>
<head>
<author> Tod LeBlank
</author>
<date> 2003-12-25
</date>
<language> en
</language>
</head>
<body>
<to>
Lucy </to>
<from> Ed> </from>
<text>
I will be arriving in
Barcelona from
New York on Wednesday night.
</text>
<salutation> See you soon,
Ed </saluation>
</body>
</message>
</envelope>
Extensibility
Consider using generic elements with role attributes when it is difficult to anticipate the types of elements you will eventually need:
<inventory>
<item type = "tool">
TI 70 Calculator </item>
<item type = "toy">
Malibu Barbie </item>
<item type = "food">
Hershey Bar </item>
<!-- etc. -->
</inventory>
Use a catch-all element when the content of an element is difficult to anticipate:
<car vin = "321-8420xwb-199276-f520">
<make> BMW </make>
<model style = "sedan">
328i </model>
<year> 1998 </year>
<features>
<feature> CD Player
<feature>
<feature> side air bags </feature>
<feature> ABS </feature>
<!-- etc. -->
</features>
</car>