I/O Streams in Java
A Java program communicates with I/O devices in its environment through streams. A stream is a queue of bytes or characters that connects a data source to a data sink:

The source places data (bytes or characters) into the stream using a special non-blocking write operation:
stream.write(data)
The sink extracts data using a special read operation:
try {
data = stream.read();
} catch(IOException e) {
System.err.println(e.getMessage());
}
The read operation blocks until input data is available, the end of the stream is detected, or an exception is thrown. It returns -1 if the end of the stream has been reached.
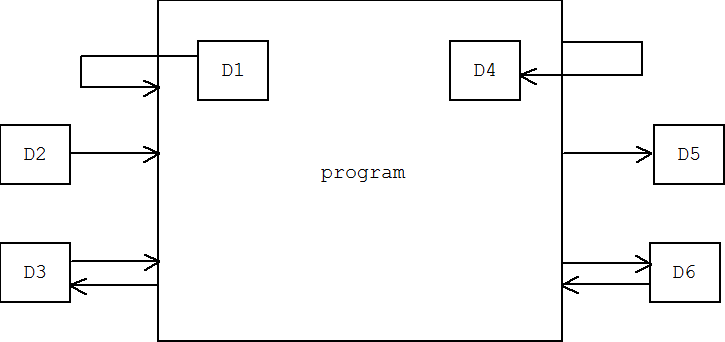
In the following diagram a program has streams connecting it to six "devices". The program plays the role of sink for D1 and D2, the role of source for D4 and D5, and is both a source and a sink for D3 and D6. The devices might be keyboards, modems, other programs, files, or arrays (or strings) inside of the program itself (this is the case with D1 and D4).
Java distinguishes between input streams and output streams and also between byte streams and character streams. A character-oriented input stream is called a reader. A character-oriented output stream is called a writer. All I/O related classes are declared in the java.io and java.nio packages.
Byte Streams
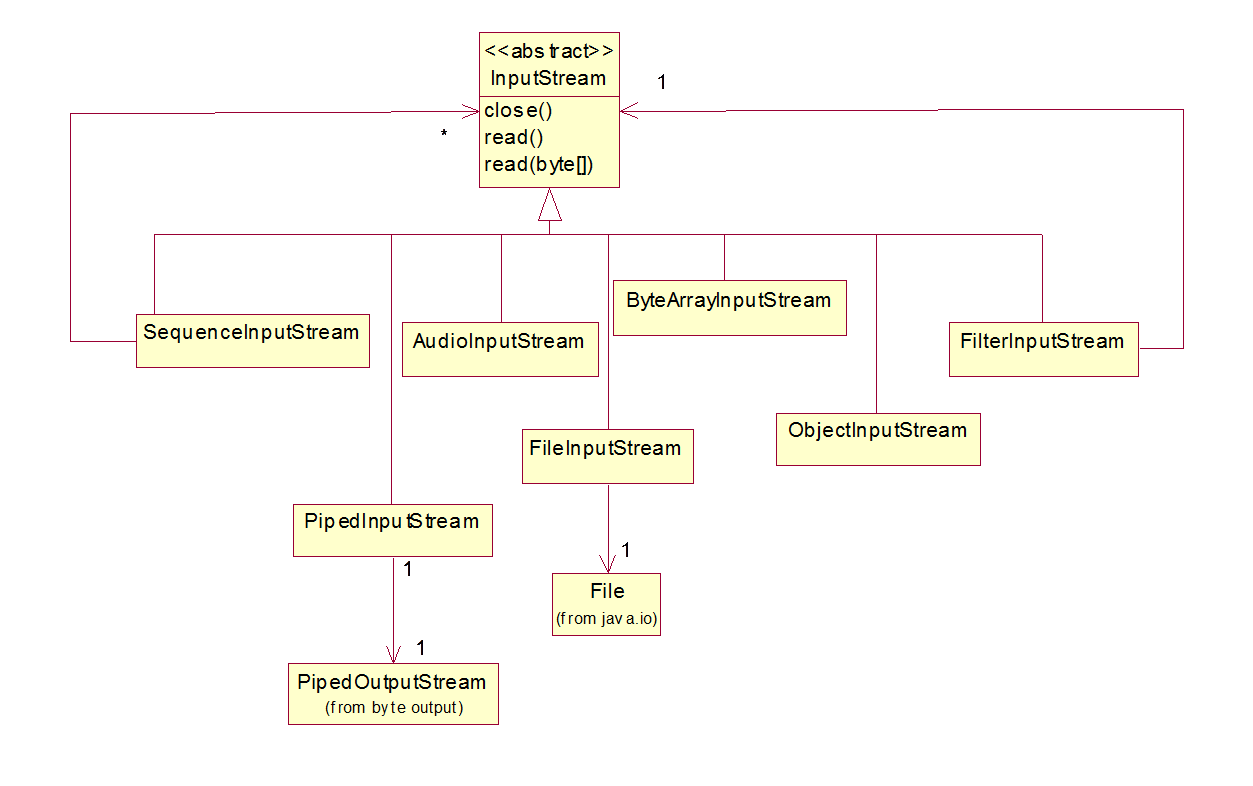
Here are the byte-oriented input streams from the java.io package
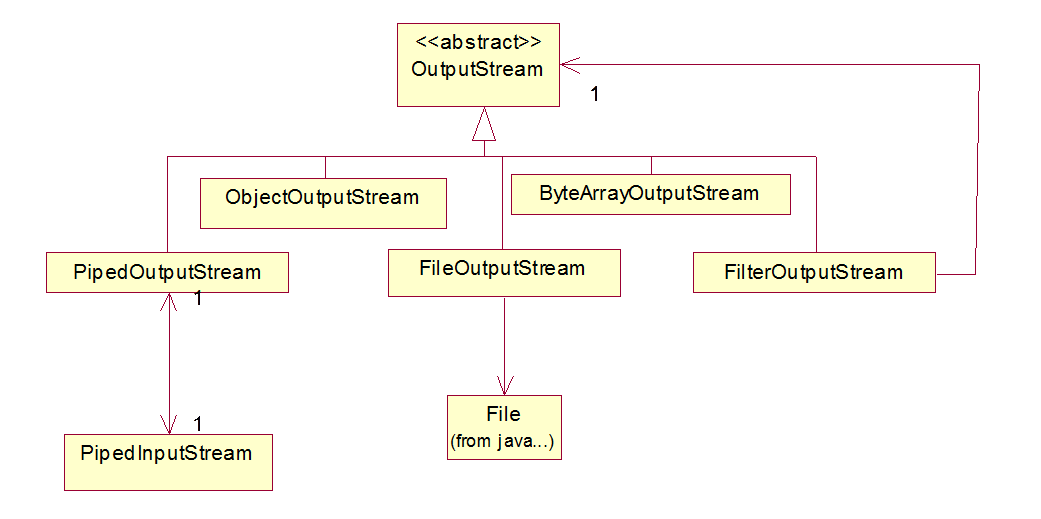
The byte-oriented output streams mirror the input streams:
Here's a sketch of the InputStream class:
abstract class InputStream {
/**
* Blocking read, returns a value between 0 and
255
* or -1 if end of stream is reached
*/
public abstract int read() throws
IOException;
public void int read(byte[] bytes) throws
IOException {
int count = 0;
while(true) {
if (bytes.length <= count)
break;
int next = read();
if (next == -1) break;
bytes[count++] = next;
}
return count;
}
// etc.
}
Here's a sketch of the OutputStream class:
abstract class OutputStream {
/**
* Wites the lower byte of b to output stream
*/
public abstract void write(int b)
throws IOException;
public void write(byte[] bytes) throws
IOException {
for(int i = 0; i < bytes.length;
i++) {
write(bytes[i];
}
}
// etc.
}
Notice that both classes are abstract. It's up to subclasses to implement the basic read or write operation.
Byte Array Streams
For example, the following fragment creates an input stream with an array of bytes as its source. It then reads from the stream until the sentinel value -1 indicates the end of the stream has been reached:
byte[] nums = {10, 20,
30, 40, 50};
ByteArrayInputStream is = new
ByteArrayInputStream(nums);
while(true) {
int next = is.read();
if (next == -1) break;
System.out.println("next =
" + next);
}
In the next fragment an output stream is created with an internal array as its sink. A series of write operations is performed, the array is subsequently extracted and displayed:
ByteArrayOutputStream
os = new ByteArrayOutputStream();
for(int i = 0; i < 10; i++) {
os.write(i);
}
byte nums[] = os.toByteArray();
for(int i = 0; i < nums.length;
i++) {
System.out.println("next =
" + nums[i]);
}
The following fragment demonstrates the ability to mark a position in an input stream, and then reset the stream to that position. It also demonstrates the ability to skip bytes and to determine the number of bytes available:
byte[] nums = {10, 20,
30, 40, 50};
ByteArrayInputStream is = new
ByteArrayInputStream(nums);
int next = is.read(); // read 10;
if (is.markSupported())
is.mark(is.available());
next = is.read(); // read 20
System.out.println("bytes
available = " + is.available()); // 3
is.skip(2); // skip 30 and 40
next = is.read(); // read 50
if (is.markSupported()) is.reset();
next = is.read(); // read 20
File Streams
The following fragment shows how to create a file containing Java bytes by creating a file output stream. Many of the operations on file streams throw exceptions when communication with the operating system fails, therefore we use a try-catch-finally block. We want to be sure to close the file if an exception is thrown or not, so we put this code in the finally clause:
FileOutputStream os =
null;
try {
os = new FileOutputStream("data");
for(int i = 0; i < 10; i++) {
os.write(i);
}
} catch(IOException e) {
System.err.println(e.getMessage());
} finally {
try {
os.close();
} catch(IOException e) {
System.err.println(e.getMessage());
}
}
Executing the above code creates a file called "data" containing the integers 0 through 9. Of course these are Java integers, which means that the file can't be easily read by a program written in another language. In particular, trying to read data using an ordinary text editor fails miserably. To read the file, we need another Java program. The following fragment reads the file and displays the contents:
FileInputStream is = null;
try {
is = new
FileInputStream("data");
while(true) {
int next = is.read();
if (next == -1) break;
System.out.println("next
= " + next);
}
} catch(IOException e) {
System.err.println(e.getMessage());
} finally {
try {
is.close();
} catch(IOException e) {
System.err.println(e.getMessage());
}
}
Filters
Reading and writing a single byte at a time is inefficient and tiresome. To add capabilities to an input stream such as buffering input, reading multi-byte values, or maintaining check sums of the data read (so the integrity of the data can be verified) Java uses a variant of the Decorator Design Pattern. Basically, a programmer wraps an input stream inside of a filter (i.e., a decorator) that adds the desired capability. The key is that the filter itself is an input stream, and therefore can be wrapped inside of another filter. Thus, the programmer can create a chain of filters in front of an ordinary input stream thereby adding any combination of desired features.
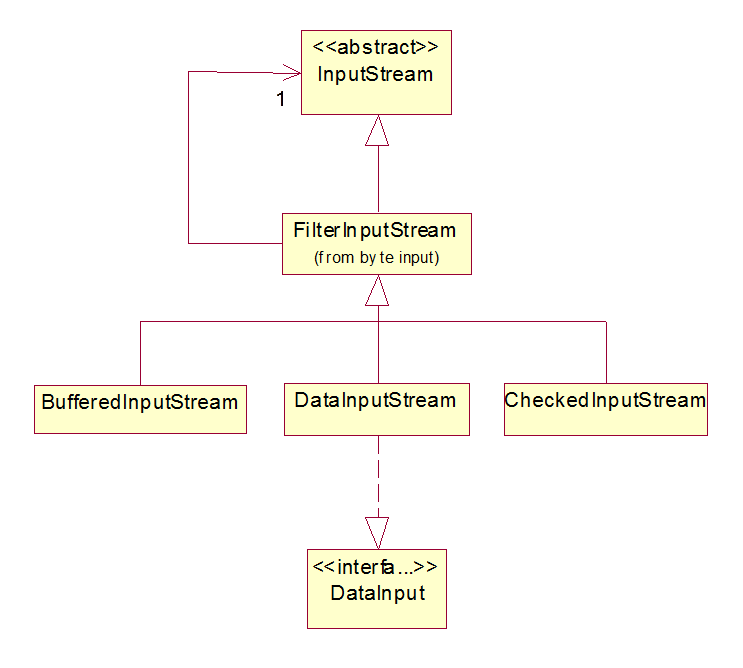
Here's a fragment of the input filter hierarchy, the output filter hierarchy is the mirror image:
The implementation of the filter input stream simply delegates to the next input stream in the chain:
class FilterInputStream extends InputStream {
protected InputStream in;
public FilterInputStream(InputStream
in) { this.in = in; }
public int read() throws IOException {
return in.read(); }
}
Analogously, an output filter delegates to the next output stream in the chain:
class FilterOutputStream extends OutputStream {
protected OutputStream out;
public FilterOutputStream(OutputStream
out) { this.out = out; }
public void write(int b) throws
IOException { out.write(b); }
}
For example, the following Java code creates a sequence of three filters in front of a file output stream:
try {
// create filter chain:
FileOutputStream fout =
new
FileOutputStream("myData");
BufferedOutputStream bout =
new BufferedOutputStream(fout);
CheckedOutputStream cout =
new CheckedOutputStream(bout, new
CRC32());
DataOutputStream dout =
new DataOutputStream(cout);
// write data:
dout.writeInt(42);
dout.writeDouble(3.14);
dout.writeChar('x');
dout.writeBoolean(true);
dout.writeChars("Hello,
World");
// etc.
} catch (IOexception e) {
// handle e
}
Of course the decorator chain could have been created by a single declaration:
DataOutputStream dout =
new DataOutputStream(
new CheckedOutputStream(
new BufferedOutputStream(
new
FileOutputStream("myData")), new CRC32()));
The following object diagram depicts the filter chain:

In the following fragment several binary values are written to a file output stream wrapped in a data output stream filter:
DataOutputStream os =
null;
try {
os = new DataOutputStream(new
FileOutputStream("bins"));
os.writeDouble(3.14);
os.writeBoolean(true);
os.writeInt(42);
os.writeChar('q');
} catch(IOException e) {
System.err.println(e.getMessage());
} finally {
try {
os.close();
} catch(IOException e) {
System.err.println(e.getMessage());
}
}
Next, the file is read using a file input stream wrapped by a data input stream filter:
DataInputStream is =
null;
try {
is = new DataInputStream(new
FileInputStream("bins"));
System.out.println("next =
" + is.readDouble());
System.out.println("next =
" + is.readBoolean());
System.out.println("next =
" + is.readInt());
System.out.println("next =
" + is.readChar());
} catch(IOException e) {
System.err.println(e.getMessage());
} finally {
try {
is.close();
} catch(IOException e) {
System.err.println(e.getMessage());
}
}
Object Streams
Not all objects can be saved to secondary memory (i.e., a file or a database). An object that can is called persistent. An object that cannot is called transient. Usually business objects representing customers, employees, transactions, etc. need to be persistent, while architectural objects such as UI components can be transient. By default, all Java objects are transient.
Writing objects to a file and subsequently reading them back is notoriously difficult. The problem is that an object may have fields that contain references to other objects. These objects have similar fields, and so on. The entire network of objects that can be reached from object a by following these references is called the transitive closure of a, TC(a). In the example below, TC(a) = {a, b, c, d, e, f, g}.

(Note: The encumbrance of an object, a, is the cardinality of TC(a). Thus, the encumbrance of a in the example above is 6. The encumbrance is a rough measure of the reusability of an object.)
Obviously, writing object a to a file really means writing TC(a) to a file. This means keeping track of the links between the objects in TC(a), but in main memory links are represented by addresses which will loose their meaning when TC(a) is read from a file back into main memory. To solve this problem Java must somehow translate between links as memory addresses and links as some sort of virtual address such as an object identifier. (An OID is a unique id number of an object paired with the type of the object.) Fortunately, Java uses reflection to automatically solve this problem for us.
To declare an object to be persistent in Java, the programmer simply indicates that the class implements the empty Serializable interface. For example:
class Message implements Serializable {
String content;
}
class Envelope implements Serializable {
private String recipient;
private String sender;
private Message msg;
public Envelope(String r, String s,
String content) {
recipient = r;
sender = s;
msg = new Message();
msg.content = content;
}
public String toString() {
return "to: " + recipient
+ ", from: " +
sender + ", content:
" + msg.content;
}
}
Note that for an object a to be persistent, every object in TC(a) must be persistent.
In the following example an array of envelopes containing messages is created. The envelopes are subsequently written to an object output stream that wraps a file output stream:
ObjectOutputStream os = null;
Envelope[] envelopes = new Envelope[5];
for(int i = 0; i < 5; i++) {
envelopes[i] = new
Envelope("Bill", "Judy", "You're number " + i);
}
try {
os = new ObjectOutputStream(new
FileOutputStream("messages"));
os.writeInt(5);
for(int i = 0; i < 5; i++) {
os.writeObject(envelopes[i]);
}
} catch(Exception e) {
System.err.println(e.getMessage());
}
Now the array is read from an object input stream:
ObjectInputStream is = null;
try {
is = new ObjectInputStream(new
FileInputStream("messages"));
int size = is.readInt();
Envelope[] messages = new
Envelope[size];
for(int i = 0; i < size; i++) {
messages[i] =
(Envelope)is.readObject();
}
for(int i = 0; i < size; i++) {
System.out.println(messages[i]);
}
} catch(Exception e) {
System.err.println(e.getMessage());
} finally {
try {
is.close();
} catch(IOException e) {
System.err.println(e.getMessage());
}
}
Here's the output produced:
to: Bill, from: Judy, content: You're number 0
to: Bill, from: Judy, content: You're number 1
to: Bill, from: Judy, content: You're number 2
to: Bill, from: Judy, content: You're number 3
to: Bill, from: Judy, content: You're number 4
Pipes
A filter is an object that perpetually:
1. reads a message (represented as a byte) from its input pipe
(represented as an input stream)
2. updates the message (i.e., modifies the byte)
3. writes the updated message to an output pipe (represented as an output
stream)
A pipeline is a sequence of filters where the output pipe of one filter is connected to the input pipe of the next filter. (Pipeline architectures are popular in UNIX, compilers, and signal processing systems.) Of course in order for each filter in a pipeline to be executing a perpetual loop we must assume that filters are active objects. (An active object is an object that owns its own execution thread. In Java this can be done by extending the Thread class and overriding the inherited run method.)
Here's a simple implementation of a Filter class; messages are simply bytes:
class Filter extends Thread {
private InputStream inStream;
private OutputStream outStream;
public Filter(InputStream in,
OutputStream out) {
inStream = in;
outStream = out;
}
// override this method in a subclass:
protected int update(int b) { return b
* 2; }
public void run() {
while(true) {
try {
int next = inStream.read();
if (next == -1) break;
next = update(next);
outStream.write(next);
} catch(IOException e) {
System.err.println("Filter:
" + e.getMessage());
break;
}
}
}
}
Java provides a special type of input stream called a piped input stream. The data source is a piped output stream. Conversely, the sink of a piped output stream is a piped input stream:

Both PipedInputStream and PipedOutputStream provide a connect() method that simultaneously sets the source of the input pipe and the sink of the output pipe.
The next example builds the following pipeline:

The input of f1 is a byte array input stream. The output of f4 is a byte array output stream.
public class PipeLine {
public static void main(String[] args)
{
try {
byte[] nums = {1, 2, 3, 4, 5};
InputStream is = new
ByteArrayInputStream(nums);
PipedOutputStream opipe1 = new
PipedOutputStream();
PipedOutputStream opipe2 = new
PipedOutputStream();
PipedOutputStream opipe3 = new
PipedOutputStream();
PipedInputStream ipipe1 = new
PipedInputStream();
PipedInputStream ipipe2 = new
PipedInputStream();
PipedInputStream ipipe3 = new
PipedInputStream();
opipe1.connect(ipipe1);
opipe2.connect(ipipe2);
opipe3.connect(ipipe3);
ByteArrayOutputStream os = new
ByteArrayOutputStream();
Filter f1 = new Filter(is,
opipe1);
Filter f2 = new Filter(ipipe1,
opipe2);
Filter f3 = new Filter(ipipe2,
opipe3);
Filter f4 = new Filter(ipipe3,
os);
f4.start();
f3.start();
f2.start();
f1.start();
f1.join();
f2.join();
f3.join();
f4.join();
byte nums2[] = os.toByteArray();
for(int i = 0; i <
nums2.length; i++) {
System.out.println("next
= " + nums2[i]);
}
System.out.println("done");
} catch(Exception e) {
System.err.println(e.getMessage());
}
}
}
Here's the program output:
Filter: Write end dead
Filter: Write end dead
Filter: Write end dead
next = 16
next = 32
next = 48
next = 64
next = 80
done
Character Streams
A character-oriented input stream is called a reader. A character-oriented output stream is called a writer. The Reader and Writer hierarchies mirror the byte-oriented input and output stream hierarchies, respectively. For example, here is the Reader hierarchy:
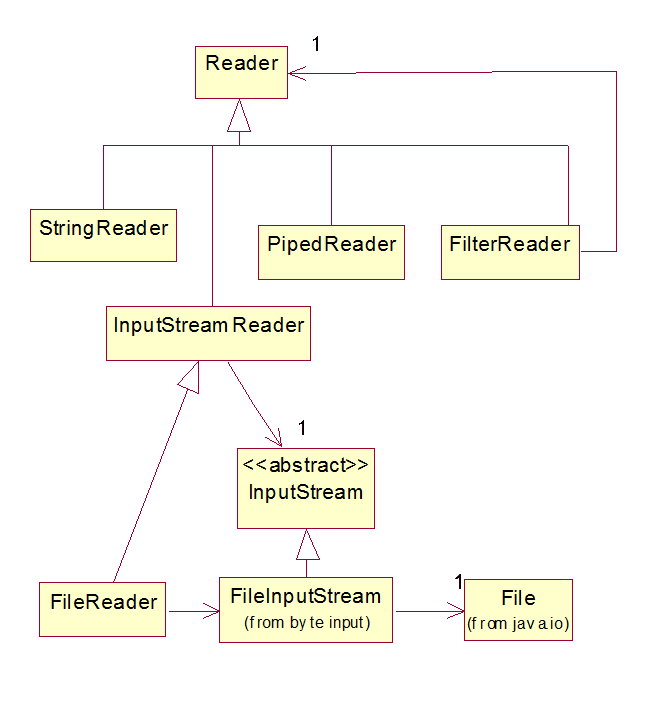
Of course Readers provide character-oriented versions of the InputStream operations: read, mark, reset, etc. while Writers provide character-oriented versions of the OutputStream operations: write, close, flush, etc.
For example, here is a simple block of code that creates a reader with a string as its source, then prints the characters in the string one at a time:
StringReader reader = new StringReader("testing: one, two,
three");
while(true) {
try {
int next = reader.read();
if (next == -1) break;
System.out.println("next =
" + (char)next);
} catch(IOException e) {
System.err.println(e.getMessage());
break;
}
} // while
Byte to Character
Conversion
Sources for readers and destinations for writers can be strings, pipes, filters, and of course, byte-oriented input and output streams. The InputStreamReader class serves as a bridge between byte-oriented input streams and readers, while the OutputStreamReader is the bridge connecting writers to byte-oriented output streams.
The interesting feature is that when constructing a reader, the user may specify a character set to be used in translating between the bytes coming from the source and the character codes being read. Similarly, when constructing a writer, the user may specify a character set to be used to translate the character codes being written with the bytes being sent to the destination. For example:
OutputStream stream = ...;
OutputStreamWriter writer =
new OutputStreamWriter(stream,
"US_ASCII");
See the Javadoc page for the Charset class for more details. If the character set isn't specified, the default character set for the host machine is used. This means the same Java program can run on any computer in the world, regardless of the underlying character set.
To demonstrate this, the following program creates a file using a writer:
PrintWriter pw = null;;
try {
pw = new PrintWriter(new
BufferedWriter(new FileWriter("text")));
pw.write("is were am be are being
was been\n");
pw.write("A squid eating dough is
fast and bulbous\n");
pw.write("These are the voyages of
the star ship Enterprise\n");
pw.close();
} catch(IOException e) {
System.err.println(e.getMessage());
pw.close();
}
Files created by writers can be read by local text editors:

Java can also read from text files created by local text editors:
BufferedReader br = null;
try {
br = new BufferedReader(new
FileReader("text"));
while(true) {
String next = br.readLine();
if (next == null) break;
System.out.println("next =
" + next);
}
} catch(IOException e) {
System.err.println(e.getMessage());
try {
br.close();
} catch(IOException e1) {
System.err.println(e1.getMessage());
}
}
Consoles
The Java system class provides the only streams for communicating with the console window and the keyboard:
class System {
public static PrintStream out, err; //
console window
public static InputStream in; //
keyboard
// etc.
}
System.in only provides the ability to read one byte at a time from the keyboard, and of course print streams are not sensitive to the underlying character set of the host machine. To remedy this defect I have a reusable Console class (see jutil.Console):
public class Console {
protected BufferedReader stdin =
new BufferedReader(
new
InputStreamReader(System.in));
protected PrintWriter stdout =
new PrintWriter(
new BufferedWriter(
new
OutputStreamWriter(System.out)), true);
protected PrintWriter stderr =
new PrintWriter(
new BufferedWriter(
new
OutputStreamWriter(System.err)), true);
A control loop perpetually prompts the user for a command, reads the command, then executes it:
public void
controlLoop() {
while(true) {
try {
stdout.print("->
");
stdout.flush(); // force the
write
String cmmd =
stdin.readLine();
if (cmmd == null) {
stdout.println("type
\"help\" for commands");
continue;
}
cmmd = cmmd.trim(); // trim
white space
if
(cmmd.equalsIgnoreCase("quit")) break;
if
(cmmd.equalsIgnoreCase("help")) {
stdout.println("Sorry,
no help is available");
continue;
}
if
(cmmd.equalsIgnoreCase("about")) {
stdout.println("All
rights reserved");
continue;
}
stdout.println(execute(cmmd));
} catch(Exception e) {
stderr.println(e.getMessage());
}
} // while
stdout.println("bye");
} // controlLoop
Executing a command must be defined in an extension:
// override in a
subclass:
protected String execute(String cmmd)
throws Exception {
if
(cmmd.equalsIgnoreCase("throw")) {
throw new
Exception("exception intentionally thrown");
}
return "echo: " + cmmd;
}
Here's a simple test harness:
public static void
main(String[] args) {
Console ui = new Console();
ui.controlLoop();
}
} // Console
Program output:
-> help
Sorry, no help is available
-> about
All rights reserved
-> hello
echo: hello
-> throw
exception intentionally thrown
-> quit
bye
Problems
PIPES: A Pipeline
Toolkit
In UNIX a filter is a program that reads its input from the standard input stream (stdin) and writes its output to the standard output stream (stdout);

Normally, the source of stdin is the keyboard while the destination of stdout is the monitor. However, using pipes and redirection, users can easily reset the source of stdin to be a file or the stdout of another filter. Similarly, the destination of stdout can be a file or the stdin of another filter. Thus, users can chain together filters to form pipelines. For example, the shell command:
filter1 < file1 | filter2 > file2
creates and starts the pipeline:

Note that each filter runs as a separate process, reading from stdin, processing the data read, then writing to stdout. Thus, while filter1 is processing data from the end of file1, filter 2 is simultaneously processing data that originally came from the start of file1.
Pipeline architectures join Peer-to-Peer architectures and Client-Server architectures as popular designs for distributed applications. With this in mind, we will construct a toolkit called PIPES that allows users to assemble pipelines. The PIPES package comes with several predefined classes:
PipeLine: a sequence of connected filters
PipeLineError: exception thrown when problems arise
Filter: abstract base class for all filters
FileInputFilter: extends Filter, input stream is connected to a file
ConsoleInputFilter: extends Filter, input comes from console prompt
FileOutputFilter: extends Filter, output goes to a file
ConsoleOutputFilter: extends Filter, output goes to console
PipeFilter: extends Filter, input and output are piped streams
Basically, a filter is a thread that perpetually reads strings from its input stream. When a non-null string is read, the string is processed using an abstract update method that must be implemented in a subclass. The output of the update method, if it's not null, is then written to the filter's output stream. Exceptions thrown by the update method must be caught by the filter. If one filter shuts down, the pipeline should shut down all of the filters and terminate.
To use PIPES, the user must first create a few extensions of the PipeFilter class. For example, suppose a user wants to create a pipeline for processing integer messages entered from the console. He begins by creating a few custom extensions of the PipeFilter class:
class Square extends PipeFilter {
String update(String msg) throws
PipeLineError {
if (msg == null) throw new
PipeLineError("bad input");
int val = 0;
try {
val = Integer.parse(msg);
} catch (NumberFormatException e) {
throw new
PipeLineError(e.getMessage());
}
return "" + (val * val);
}
}
class isEven extends PipeFilter {
String update(String msg) throws
PipeLineError {
if (msg == null) throw new
PipeLineError("bad input");
int val = 0;
try {
val = Integer.parse(msg);
} catch (NumberFormatException e) {
throw new
PipeLineError(e.getMessage());
}
return (val % 2 == 0)? msg: null;
}
}
class Accum extends PipeFilter {
int total = 0;
String update(String msg) throws
PipeLineError {
if (msg == null) throw new
PipeLineError("bad input");
int val = 0;
try {
val = Integer.parse(msg);
} catch (NumberFormatException e) {
throw new
PipeLineError(e.getMessage());
}
total += val;
return "" + total;
}
}
The PIPES user interface is a CUI. Here is how the user makes a pipeline:
-> makeFilter f1 ConsoleInputFilter
ok
-? makeFilter f2 Square
ok
-> makeFilter f3 isEven
ok
-> makeFilter f4 Accum
ok
-> makeFilter f5 ConsoleOutputFilter
ok
-> makePipeLine p1 f1 f2 f3 f4 f5
ok
Internally, here is what p1 looks like:

Note: stdin and stdout are the fields from the Console class.
Starting a pipeline starts all of its filters:
-> start p1
messages: 2 3 4 5
4
messages: 6 7 8
20
56
messages: quit
120
pipeline is shutting down
->
The "messages" prompt is perpetually printed by the console input filter, which then reads a line from stdin, breaks it into tokens, then writes each token to its output pipe.
Hint, use String.split():
String msgs = stdin.readLine();
String[] tokens = msgs.split("\\s");
for(int i = 0; i < tokens.length; i++) {
outStream.write(tokens[i]);
}
The other messages are coming from the ConsoleOutputFilter. These are simply the successive values of accum. Of course the output from the console input and output filters are not synchronized in any way.
Design of PIPES

Implementation of
PIPES
abstract class Filter extends Thread {
protected InputStream inPipe;
protected OutputStream outPipe;
protected abstract String update(String
msg) throws PipeLineError;
public void run() {
while(true) {
try {
"wait" for a message
from inPipe
read msg from inPipe
if (msg == null) continue;
newMsg = update(msg);
if (newMsg == null) continue;
if (newMsg is "halt"
command) break;
write newMsg to outPipe
} catch(PipeLineError e) {
break;
} catch (Exception e) {
break;
}
}
}
// etc.
}