Serialization
Assume we must implement persistent objects, but no database is available, neither relational nor object oriented. We could simply require all classes of persistent objects to provide a member function that inserts each member variable into a given file stream[1] (this process is called serialization) and a member function that extracts data from a given file stream and puts it into the corresponding member variable (this process is called deserialization.) We can force everyone to use the names serialize() and deserialize() for these member functions by creating an abstract base class for all persistent objects:
class Persistent
{
public:
virtual void serialize(fstream& f)
= 0;
virtual void deserialize(fstream&
f) = 0;
// etc.
};
Implementing serialize() and deserialize() seems simple: serialize() writes each member variable to a file stream, and deserialize() reads each member variable from a file stream, in the same order they were written. For example:
class Person: public Persistent
{
public:
void serialize(fstream& f)
{
f << name << endl;
f << gender << endl;
f << age << endl;
}
void deserialize(fstream& f)
{
f >> name;
f >> gender;
f >> age;
}
// etc.
private:
string name;
char gender; // 'M' = male, 'F' =
female, 'U' = unknown
int age;
};
To save a Person object, a writer program creates a file stream for output, then calls the object's serialize() member function:
fstream fs("employees", ios::out);
Person smith("Smith", 'F', 42);
smith.serialize(fs);
We can peek at the employees file using an ordinary text editor:
Smith
F
42
A reader program can restore this object by creating a file stream for input, creating a Person object to hold the data, then calling the deserialize member function:
fstream fs("employees", ios::in);
Person x; // create memory for data
x.deserialize(fs);
Although the member variables of x initially hold default values, after deserialization these values are replaced by Smith's data. Even object member variables can be easily saved and restored, as long as they too provide serialize() and deserialize() functions. For example, assume mailing addresses are persistent:
class Address: public Persistent
{
public:
void serialize(fstream& f)
{
f << building << endl;
f << street << endl;
f << city << endl;
f << state << endl;
}
void deserialize(fstream& f)
{
f >> building;
f >> street;
f >> city;
f >> state;
}
// etc.
private:
int building;
string street, city, state;
};
If we add an Address member variable to our Person class, then we only need to add a call to Address::serialize() in Person::serialize() and a call to Address::deserialize() in Person::deserialize():
class Person: public Persistent
{
public:
void serialize(fstream& f)
{
f << name << endl;
f << gender << endl;
f << age << endl
address.serialize(f);
}
void deserialize(fstream& f)
{
f >> name;
f >> gender;
f >> age;
address.deserialize(f);
}
// etc.
private:
string name;
char gender; // 'M' = male, 'F' =
female, 'U' = unknown
int age;
Address address; // = mailing
address
};
As long as the implementer of Person knows that the Address class is derived from the Persistent base class, then he doesn't need to know the details of how to serialize or deserialize Address objects.
Pointer Problems
Unfortunately, our simple plan runs into problems if the address member variable holds a pointer to an Address object instead of an Address object (which would make sense, because several people might share the same address):
class Person: public Persistent
{
// etc.
private:
string name;
char gender; // = 'M', 'F', or 'U'
int age;
Address* address; // points to
mailing address
};
There are three problems:
Problem 1: Restoring Pointers
Of course we can write a pointer into a file, and we can read it back:
Address *x = new Address(...), *y;
fs << x;
fs >> y; // same as y = x
But what do we do with a pointer we have read from a file that was put there by another program or by a previous activation of the same program? Although the pointer may have been valid in the address space of the writer program, it certainly isn't going to be valid in the address space of the reader program.[2]
Problem 2: Allocating Memory for Hidden Objects
Obviously we will have to abandon pointers when an object is serialized, and we will have to create new pointers to freshly created objects when an object is deserialized:
fstream fs("employees", ios::in);
Person x; // allocate memory for x
x.address = new Address(); // allocate memory for x.address
x.deserialize(fs); // calls (x.address)->deserialize(fs);
Although the author of the reader program may know that the employees file contains data for a Person object, and therefore that he must create a Person object, x, to receive this data, it seems unreasonable to demand that he also know about the associated Address object. In effect, the author of a reader program would need to know almost the entire implementation of any object that he intended to deserialize. It's more likely that the types of objects linked to a deserialized object would only be discovered while the reader program was running, long after it was written. Unfortunately, C++ doesn't have the built-in flexibility to create objects from type information at runtime.
Problem 3: Avoiding Unwanted Duplications
Assume Problems 1 and 2 can be solved. We must remember that an object might contain many pointers to other objects, and these objects may contain pointers to still other objects. When we save an object, a, we are really saving an entire network of objects rooted at a and linked by pointers. This network is called the transitive closure of a.
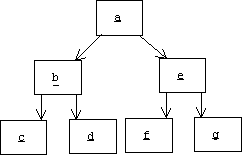
The transitive closure of an object is a directed graph, so we can use a depth-first traversal algorithm to ensure that any object that can be reached from a will be serialized, but what happens if there are two paths to the same object, or worse, if the graph contains a loop:
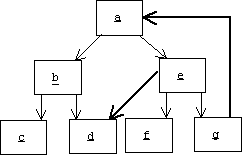
If we are not careful, then d will be serialized twice, once by b and again by e, which will result in two copies of d after deserialization. Actually, d will be serialized an infinite number of times because serializing a causes g to be serialized, and serializing g causes a to be serialized!
A Framework for Persistence
Let's develop a framework that solves these problems and that can be reused for implementing persistent objects. As with all frameworks, an important goal is to minimize the amount of work programmers who customize the framework must do.
Before we describe the framework internals, let's see how it is used. Returning to our earlier example, suppose that we kept declarations of business classes such as Person and Address in a file called bus.h:
// bus.h
#ifndef BUS_H
#define BUS_H
#include "obstream.h" // persistence framework
#include <cstring> // same as
<string.h>
class Address { ... };
class Person { ... };
// etc.
#endif
Here's the declaration of the Address class. To make things more transparent, our initial version uses C strings instead of C++ strings:
class Address: public Persistent
{
public:
Address();
Address(int b, char* s, char* c, char*
st);
IMPLEMENT_CLONE(Address)
void serialize(ObjectStream& os)
;
void deserialize(ObjectStream& os);
friend ostream&
operator<<(ostream& os, const Address& addr);
// etc.
private:
int bldg;
char *street, *city, *state;
};
Clearly the serialize() and deserialize() functions implement pure virtual functions inherited from the Persistent base class. We declare a variant of the global insertion operator, operator<<(), as a friend to provide some ability to display the private data of an Address object. This will be used primarily for testing purposes.
Because the street, city, and state attributes are pointers, it might have been a good idea to employ the Canonical Form Pattern from Chapter 4. We hide this code to simplify our demonstration.
Finally, notice the call to the IMPLEMENT_CLONE() macro. This suggests we are employing the Prototype Pattern. Further evidence of this can be found in the implementation file, bus.cpp, where a call to the MAKE_PROTOYPE() macro can be found:
MAKE_PROTOTYPE(Address)
We also find implementations of the serialize() and deserialize() functions in bus.cpp:
void Address::serialize(ObjectStream& os)
{
::serialize(os, bldg);
::serialize(os, street);
::serialize(os, city);
::serialize(os, state);
}
void Address::deserialize(ObjectStream& os)
{
::deserialize(os, bldg);
::deserialize(os, street);
::deserialize(os, city);
::deserialize(os, state);
}
There are two things to notice about these implementations. First, the parameters are no longer simple file streams. Instead, something called ObjectStreams are used. Second, both functions call global serialize() and deserialize() functions to serialize and deserialize their fields. Apparently these functions are provided by the persistence framework (obstream.h).
Returning to bus.h, the declaration of the Person class, which now contains a pointer to an Address instance, follows the same pattern as the Address declaration:
class Person: public Persistent
{
public:
Person();
Person(char *nm , char gen, int a,
Address* addr);
IMPLEMENT_CLONE(Person)
void serialize(ObjectStream& os) ;
void deserialize(ObjectStream& os);
friend ostream&
operator<<(ostream& os, const Person& per);
private:
char* name;
int age;
char gender; // 'M' = male, 'F' =
female, 'U' = unknown
Address* address;
};
The implementation file, bus.cpp, applies the MAKE_PROTOYPE() macro to the Person class:
MAKE_PROTOTYPE(Person)
The implementations of the serialize() and deserialize() functions use global serialize() and deserialize() functions to serialize and deserialize member variables, including the Address pointer:
void Person::serialize(ObjectStream& os)
{
::serialize(os, name);
::serialize(os, age);
::serialize(os, gender);
::serialize(os, address);
}
void Person::deserialize(ObjectStream& os)
{
::deserialize(os, name);
::deserialize(os, age);
::deserialize(os, gender);
::deserialize(os, (Persistent*)
address);
}
Implementations of the insertion operators are left as an exercise to the reader.
Test Program
Our test driver functions as both the writer and the reader program. This isn't cheating because the reader half doesn't use any of the objects created by the writer half. The writer half creates three Person objects. Two share an address:

Assume the test program is called main.exe and is invoked from the command line as follows:
main people
Before main() is called, we notice several messages displayed in the console window:
adding prototype for type = 7Address
done
adding prototype for type = 6Person
done
Clearly this is the work of the CREATE_PROTOTYPE() macro at work.
Main() begins by checking for the command line argument:
int main(int argc, char* argv[])
{
if (argc != 2)
{
cerr << "usage: "
<< argv[0] << " FILE\n";
exit(1);
}
Next, main() attempts to create and open an object stream for output. This creates a new file with the name stored in argv[1], which should be the string, "people":
ObjectStream os;
os.open(argv[1], ios::out);
if (!os)
{
cerr << "can't open write
file\n";
exit(1);
}
If all goes well, two Address objects and three Person objects are created:
Address a(123,
"Sesame St.", "New York City", "NY");
Address b(100, "Detroit
Ave.", "San Francisco", "CA");
Person p("Bill Jones", 'M',
42, &a);
Person q("Ed Smith", 'U', 33,
&b);
Person r("Sue Jones", 'F',
45, &a);
For diagnostic purposes, we print the three Person objects:
cout << p << '\n';
cout << q << '\n';
cout << r << '\n';
Here is the output produced:
(type = 6Person, location = 0xa0bf04, OID = 504)
Mr. Bill Jones
age = 42
(type = 7Address, location = 0xa0bf34, OID = 502)
(type = 6Person, location = 0xa0beec, OID = 505)
Ed Smith
age = 33
(type = 7Address, location = 0xa0bf1c, OID = 503)
(type = 6Person, location = 0xa0bed4, OID = 506)
Ms. Sue Jones
age = 45
(type = 7Address, location = 0xa0bf34, OID = 502)
Notice that Bill and Sue Jones both have pointers to the same Address object.
All three Person objects are serialized into the object stream, os, and the stream is closed:
p.serialize(os);
q.serialize(os);
r.serialize(os);
os.close();
We now enter the reader half of main(), which could just as easily have been implemented as a separate program. It begins by opening a second object stream for input using "people", the name still stored in argv[1]:
ObjectStream os2;
os2.open(argv[1], ios::in);
if (!os2)
{
cerr << "can't open read
file\n";
exit(1);
}
If all goes well, memory is allocated for three person objects, but no memory is allocated for the corresponding addresses. Presumably this is done dynamically, when the object stream is deserialized:
Person p2, q2, r2;
p2.deserialize(os2);
q2.deserialize(os2);
r2.deserialize(os2);
To confirm the deserialization process, we display the new Person objects and quit:
cout << p2 <<
'\n';
cout << q2 << '\n';
cout << r2 << '\n';
return 0;
}
Here is the output produced:
(type = 6Person, location = 0xa0be28, OID = 507)
Mr. Bill Jones
age = 42
(type = 7Address, location = 0x50980, OID = 502)
(type = 6Person, location = 0xa0be10, OID = 508)
Ed Smith
age = 33
(type = 7Address, location = 0x509f8, OID = 503)
(type = 6Person, location = 0xa0bdf8, OID = 509)
Ms. Sue Jones
age = 45
(type = 7Address, location = 0x50980, OID = 502)
Notice that the correct Address objects have been created. Also notice that Bill and Sue Jones share an address object, although the location of this object is different from the location of the original Address object. The deserialization mechanism preserved the object identifiers (OIDs) of the Address objects, but not the OIDs of the Person objects. This is because our program explicitly created new Person objects.
As it turns out, people, the file containing the serialized objects, is an ordinary text file that can be read by an ordinary text editor. Here is what it contains:
(10)Bill Jones
42
M
502 7Address
123
(10)Sesame St.
(13)New York City
(2)NY
(8)Ed Smith
33
U
503 7Address
100
(12)Detroit Ave.
(13)San Francisco
(2)CA
(9)Sue Jones
45
F
502
Notice that each field appears on a separate line. This makes reading the file easy. Each string field is preceded by the length of the string in parenthesis. The Address pointers have been translated into an object identifier followed by the type name. For example:
502 7Address
This is followed by the Address object itself. The only exception is the pointer to Sue Jones' address, which is simply the object identifier, 502. Presumably this is because the actual Address object occurs earlier in the file, after the entry for Bill Jones.
Implementing the Framework
The persistence framework consists of four parts: the Persistence base class, several macros, the ObjectStream class, and a collection of global functions for serializing and deserializing primitive data. Most of these definitions are contained in a file named obstream.h:
// obstream.h
#ifndef OBSTREAM_H
#define OBSTREAM_H
#include "..\util\util.h"
class ObjectStream; // forward reference
class Persistent { ... };
class ObjectStream: public fstream { ... };
// macros:
#define MAKE_PROTOTYPE(TYPE) ...
#define IMPLEMENT_CLONE(TYPE) ...
// global serialization & deserialization utilities:
void serialize(ObjectStream& os, Persistent* obj);
void deserialize(ObjectStream& os, Persistent*& obj);
void deserialize(ObjectStream& os, char& x);
void serialize(ObjectStream& os, const char* x);
void deserialize(ObjectStream& os, char*& x);
// etc.
#endif
The Persistent class follows the Prototype Pattern discussed earlier. It maintains a static prototype table, provides a function for adding entries to the table (addPrototype), and a factory method for dynamically creating new Persistent objects (makePersistent). In fact, the implementations of these functions are nearly identical to the implementations given in the Prototype Pattern (except we replace Product by Persistent).
The Persistent class declares three pure virtual functions that must be implemented by derived classes: clone(), serialize(), and deserialize(). The clone() function is required by the Prototype Pattern. It will be implemented using the IMPLEMENT_CLONE() macro exactly as before. Our test program gave examples of how the serialize() and deserialize() functions might be implemented by derived classes.
Finally, the Persistent class automatically assigns a brand new object identifier (OID) to every Persistent object. Here's a listing of the declaration:
class Persistent
{
public:
Persistent() { OID = nextOID++; }
Persistent(const Persistent& p) {
OID = nextOID++; }
virtual ~Persistent() {}
int getOID() const { return OID; }
void setOID(int id) { OID = id; }
string getType() const { return
typeid(*this).name(); }
// overridables:
virtual Persistent* clone() const = 0;
virtual void serialize(ObjectStream&
os) = 0;
virtual void
deserialize(ObjectStream& os) = 0;
// prototype support:
static Persistent*
makePersistent(string type);
static Persistent* addPrototype(string
type, Persistent* p);
private:
static map<string, Persistent*>
protoTable;
static int nextOID;
int OID; // object identifier for
this object
};
Of course we must remember to define an initialize the static class variables in obstream.cpp:
map<string, Persistent*> Persistent::protoTable;
int Persistent::nextOID = 500; // make OIDs impressively large
We make a minor modification to the MAKE_PROTOYPE() macro. Instead of stringifying the TYPE parameter to generate the type name argument for the call to addPrototype(), we use the global typeid() function to generate the type name from the parameter:
#define MAKE_PROTOTYPE(TYPE) \
Persistent* TYPE ## _myProtoype = \
Persistent::addPrototype(typeid(TYPE).name(),
new TYPE());
This is done because typeid() is called by the getType() member function, which in turn is called by the framework to provide the type names that will be written to files when pointers are serialized. It's important that this type name matches the type name that the pointer deserialization function will find in the prototype table. (Of course there are other ways to accomplish this.)
Pointer Swizzling and Object Streams
As we have seen, the biggest problem our framework faces is how to serialize and deserialize pointers to persistent objects. The standard trick for solving this problem is called pointer swizzling: each time a pointer, p, to a Persistent object needs to be serialized, the OID and type name of the object *p is written to the file instead of p. When a pointer is deserialized, the type name is read from the file and used by the Prototype Pattern to dynamically create a new object.
How do we avoid unnecessary duplications? This is where the object identifiers come in. Every object stream maintains two tables. The save table stores associations between serialized pointers and object identifiers:

Save Table
The load table stores inverse associations between object identifiers and deserialized pointers:

Load Table
Each time a pointer is serialized, a new entry is created in the save table. When a pointer is about to be serialized, the save table is consulted to determine if the same pointer has previously been serialized. If so, then only the corresponding OID is written to the file.
Each time a pointer is deserialized, an entry is made in the load table. Before a pointer is deserialized, the OID is read from the file and the load table is searched to determine if the pointer has already been deserialized.
The ObjectStream class inherits file I/O machinery from the fstream class. It adds the save and load tables as well as functions for searching these tables. Since the functions that serialize and deserialize pointers will need to access these tables, they are declared as friends:
class ObjectStream: public fstream
{
public:
Persistent* find(int oid); // searches
load table
int find(Persistent* obj); // searches
save table
friend void serialize(ObjectStream&
os, Persistent* obj);
friend void
deserialize(ObjectStream& os, Persistent*& obj);
private:
// for pointer swizzling:
map<int, Persistent*> loadTable;
map<Persistent*, int> saveTable;
};
Global Serializing and Deserializing Utilities
Serializing and Deserializing Primitive Values
Serializing primitive values is easy: the insertion operator is used to write the value and a terminator to the file stream. In most cases the extraction operator can be used to extract data from the file and into the provided reference parameter. For efficiency, the functions are made inline, which means they must be placed in obstream.h. For example:
inline void serialize(ObjectStream& os, const int x)
{
os << x << TERMINATOR;
}
inline void deserialize(ObjectStream& os, int& x)
{
os >> x;
}
Here we assume a macro defines TERMINATOR as a name for the newline character:
#define TERMINATOR '\n';
It's risky to deserialize characters using the extraction operator, because it skips over all white space characters, not just newline characters (the terminator). Our implementation only skips terminators. Because it contains an iteration, it would be unwise to make it an inline function:
void deserialize(ObjectStream& os, char& x)
{
do { os.get(x); }
while (os && x == TERMINATOR);
// skip newlines
}
Serializing and Deserializing C Strings
When we serialize a C string, we also write its length to the object stream:
void serialize(ObjectStream& os, const char* x)
{
int n = strlen(x);
os << '(' << n <<
')';
for(int i = 0; i < n; i++)
os.put(x[i]);
os << TERMINATOR;
}
When a C string is deserialized, first its length is read from the file. The length is used to allocate enough memory to hold the string, then the characters are read into the array:
void deserialize(ObjectStream& os, char*& x)
{
int n; // = string length
char lparen, rparen; // storage for '('
and ')'
os >> lparen >> n >>
rparen;
x = new char[n + 1];
for(int i = 0; i < n; i++)
x[i] = os.get();
x[n] = 0; // add null terminator
}
Serializing and Deserializing Pointers
We only provide pseudo code for serializing and deserializing pointers to persistent objects. (Note: pointers to anything else won't be serialized.) The algorithms follow the general strategy outlined earlier. The complete implementations are left as an exercise.
void serialize(ObjectStream& os, Persistent* x)
{
if (x is the null pointer?)
write 0 to os
else if (x already in saveTable?)
write associated OID to os
else
{
1. get type of *x
2. get OID of *x
3. update saveTable
4. write OID, type, & TERMINATOR
to os
5. serialize *x
}
}
void deserialize(ObjectStream& os, Persistent*& x)
{
1. read OID from os
if (OID == 0)
x = the null pointer
else if (OID already in loadTable)
x = associated pointer
else
{
2. read type from os
3. x = dynamically instantiate from
type
4. update loadTable
5. set OID of *x
6. deserialize *x
}
}
Our persistence framework will be combined with the application frameworks we will develop in Chapter 7.