CS297 Deliverable 1
Document-Level Machine Translation with Hierarchical Attention
Experiments with rule-based machine translation
Yu-Tang Shen (yutang.shen@sjsu.edu)
Advisor: Dr. Chris Pollett
[PDF version of this page] [Implementation code]Introduction on Rule-based Machine Translation
Rule-based machine translation (RBMT) is one of the more apparent ways of implementing machine translation (MT) technologies. RBMT follows a set of rules to perform translation, and the difference between swapping every word in the source language (SL) into target language (TL) is more complex rules, such as re-ordering, can be specified in RBMT.
Although the concept of MT was brought up in the seventeenth century, it was until 1933 that George Artsrouni and Petr Sminrnov-Troyanskii published a concrete proposal utilizing a paper tape machine to translate [1]. Most of the pioneers in the MT field, including the one published by George Artsrouni and Petr Sminrnov-Troyanskii, can be categorized as RBMT.
RBMT requires delicate preparation on the rules, where a huge number of rules consist of translating Russian polysemes to English terms in a MT system developed by Erwin Reifler [1]. Even though a great amount of mappings of Russian-English were done, the results were unsatisfactory. Therefore, the research split into two directions, trial-and-error approaches and theoretical approaches, where the former tried to get the immediate working MT systems and the latter aimed to improve MT by scrutinizing the linguistics.
Machine Translation Types
Three MT strategies, direct translation, indirect translation, and transfer translation will be discussed in this section.
Direct translation
Direct translation utilizes a set of rules that directly translate SL to TL, so developers can easily revise the rules and quickly identify the errors. For example, RAND Corporation project started with basic rules and keep on revising the rules by examining the translation generated by the rules.
However, the disadvantage of this strategy is the exponential growth on the set of rules: for translation between N languages, N(N-1) sets of rules are required, which grows exponentially.
Indirect translation
Indirect translation adds an additional interlingua (IL) layer between two languages so that less set of rules are required for multi-language MT. Instead of translating the source language to the target language, SL is first mapped to IL, which preserves the semantic information, and TL is generated from IL information. With this approach, merely 2N sets of rules are required for translation between N languages.
However, an universal interlingua might fail to abstract the transition between every pair of languages, because two TLs might be inherently different and it would be challenging to synthesize two divergent languages with a same piece of IL.
Transfer translation
Transfer translation attaches an extra layer of IL from the indirect translation schema, so the two layers of IL act as abstractions of SL and TL respectively. In this approach, it resolves the challenge of synthesizing different TLs with a same piece of IL. Instead of synthesizing TL from the abstraction of SL, which is the first IL, an additional transition to convert abstracted information from SL to TL is deployed. Therefore, the second IL will act as seed information to generate the TL.
Experiments
Simple experiments are conducted to evaluate the strengths and weaknesses of RBMT. The experiments are done with Universal Rule-Based Machine Translation toolkit [2].
Experiments with one-to-one translation
In this configuration, the relationships between SL to TL is one-to-one without reordering, and this experiment shows satisfying results.

Fig 1. Tuples of translations from English to Traditional Chinese |
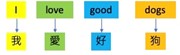
Fig 2. One-to-one relationships without reordering |
The translations from the experiment are correct. Due to its simplicity, once the rules are set correctly, the translation will be satisfactory.
Experiments with one-to-many translations
Knowing simple-structured sentences can be correctly translated, a more sophisticated test is shown in this section. One of the shortcomings of RBMT is the inability to provide more than one translation from a same word.

Fig 3. Tuples of translations from English to Traditional Chinese
In the two source sentences in Fig3., the two 'make's mean differently. Since the rules must be deterministic, RBMT failed to resolve different meanings in these two sentences.
Attempts on complex sentence structures
With unsatisfactory results from one-to-many configuration, another experiment is configured to observe the results from more complicated sentence structures such as clauses, conjunctions, etc.

Fig 4. Complicated sentence structure corpus
A sub-corpus is derived from [3], where 10 sentence pairs are sampled. Due to the complexity of the grammatic transition, the attempts to set rules fail. But by observing the relationship between SL and TL, it is obvious that an in-depth understanding on the linguistic knowledge in both languages is required to create a RBMT system.
Conclusion
As the pioneer of machine translation, RBMT showcases the practicality of translating with machines. Despite the poor translation quality, it provides users a general idea of the information written in languages ones don't understand.
RBMT generates deterministic translations once the rules are set, and that can be a beneficial property in MT systems, where developers can easily adjust the system for wanted effects. On the other hand, the determinism also hinders the ability for the system to provide different translations under different context.
References
- [1] W. J. Hutchins, "Machine translation: A brief history," in Concise history of the language sciences, Elsevier, 1995, pp. 431-445.
- [2] T.-P. Nguyen, URBANS: Universal Rule-Based Machine Translation NLP toolkit, GitHub, 2021.
- [3] J. Tiedemann, "Parallel Data, Tools and Interfaces in OPUS," in Proceedings of the 8th International Conference on Language Resources and Evaluation, 2012.