Chris Pollett >
Students >
Bhajikaye
( Print View)
[Bio]
[Blog]
Deliverable 2:
Introduction
The purpose of this deliverable was to study existing Question Answering systems over knowledge graphs. Looking at surveys and conference papers, it could be seen that both rule based and machine-learning techniques can be applied. This study concentrated on using machine-learning networks to learn the question structure and build the equivalent sparql query.
Lin et. al[1] described an unsupervised approach to train the model to make all decisions. It learns the relevant facts from the question to retrieve a ranked list of subject-predicate pairs. The network contains a nested word and character level encoder which handles out-of-vocabulary words and exploits word semantics. This is the encoder that was implemented as part of deliverable 2.
Method Used
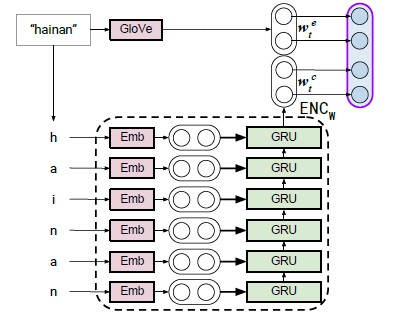
The word representation encoder consists of a word embedding module and a character level embedding module. Pre-trained Glove embeddings are used to create the word vector part of the representation. For every word that was discovered, custom character embedding are created to feed into an RNN that results in the final character vector. The word and character vector are combined as the word representation for a candidate subject or predicate.
This word representation is an important part of the system defined in [1]. The user enters a question that is separated into a list of facts. All words in this fact list are encoded as their word representation using the model described below.
According to [1], the cosine similarity between the word representation of the fact list and the word representation of candidate subject-predicate pairs ranks the possible results.
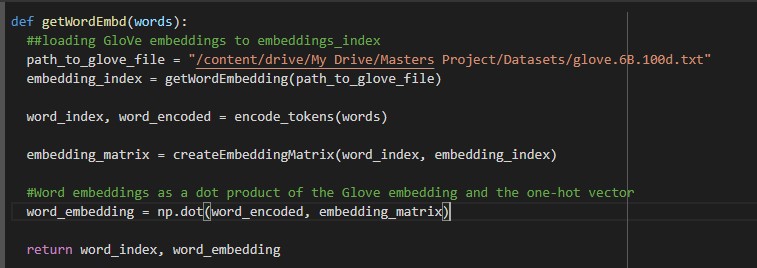
The word level embedding is defined as the dot product of the Glove embedding and the one hot vector representation of the word in the input sentence.
The character-level embedding model observes characters in a word for a predefined window size. For all context characters, the length of the list is the window size defined. For the word 'hainan', with a window size = 2 the character contexts are defined as -
target : [ h ] context : [ a i <PAD> <PAD> ] target : [ a ] context : [ h i n <PAD> ] target : [ i ] context : [ h a n a ] target : [ n ] context : [ a i a n ] target : [ a ] context : [ i n n <PAD> ] target : [ n ] context : [ n a <PAD> <PAD> ]
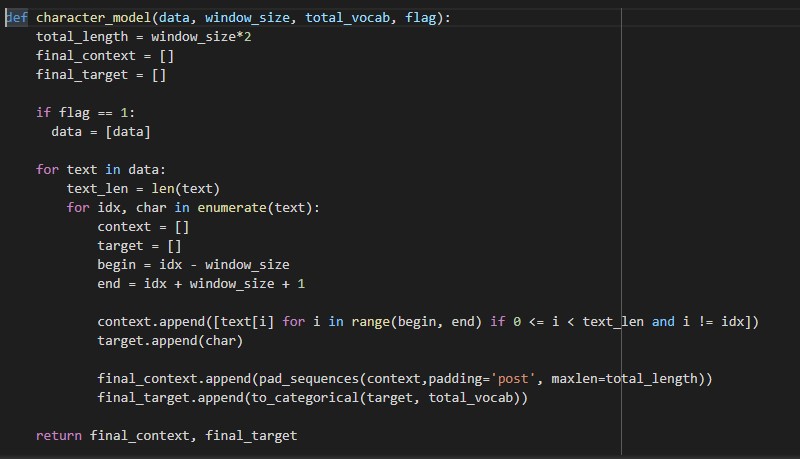
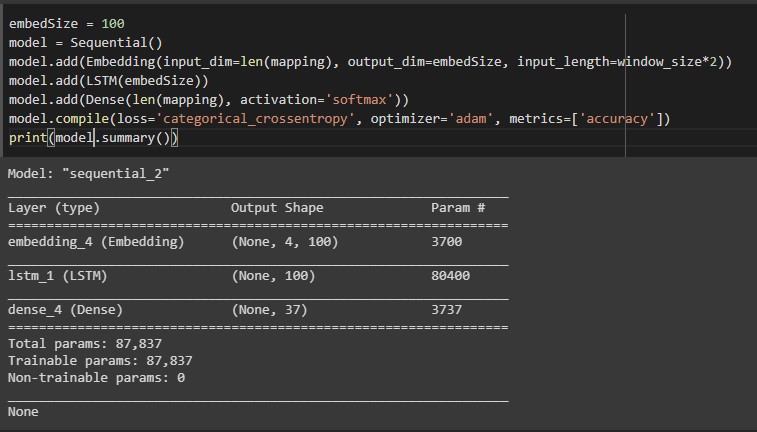
Every character is then encoded as a one hot vector depending on the character vocabulary. This model recognizes a total of 37 characters - the padding symbol [<PAD>], lowercase alphabets [a-z] and numbers [0-9].
Based on the characters before and after, the LSTM model learns the target character. The embedding layer that connects to it has the character embeddings as its final internal states.
Dataset Used
The pre-trained word embedding used are GloVe embeddings from the Stanford NLP publications[2]. The embedding file has 400K words with each having 100 dimensions.A subset of 50,000 words from the Brown Corpus Dataset[3] was used to train the character embeddings for all alphabets and numbers.
Result Analysis
Setting epoch count = 100 and embedding dimension = 100.For window size = 2, the accuracy of the character embedding model is 66.90%
For window size = 3, the accuracy of the character embedding model is 74.90%
Evaluating for input question - "What cyclone affected Hainan?"
The recognized facts are [ "cyclone", "affected", "hainan" ]
Word index: {'cyclone': 1, 'affected': 2, 'hainan': 3}
One hot encoded vector for the question:
[[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]
The character embedding for the word 'cyclone' are of shape [7, 100], for 'affected' are [8, 100] and 'hainan' are [6,100].
When these are input to a single-layer GRU, the resultant character vectors are [1,100] for every word.
The final word representation are a combination of the word vector [1,100] and the character vector [1,100].
References
- Liu, Y., Zhang, T., Liang, Z., Ji, H., & McGuinness, D. (2018). Seq2RDF: An End-to-end Application for Deriving Triples from Natural Language Text. ArXiv, abs/1807.01763.
- https://nlp.stanford.edu/projects/glove/
- https://www1.essex.ac.uk/linguistics/external/clmt/w3c/corpus_ling/content/corpora/list/private/brown/brown.html