Deliverable 5 - YOLO Training
Summary
It works in Pytorch with GPU computation via CUDA integration.
This involves training on the latest version of the YOLO CNN architecture.
It runs on a Pytorch implementation of the model and interfaces with
the GPU via the CUDA framework API.
Background
Previously, the YOLO network was set up and executed for
object detection
and showed promise detecting cars even in images with several of them.
Also, it is effective at detecting other classes, such as dogs, horses,
and people, in an image. Even when the objects have varying pose,
YOLO can still locate the objects of interest and classify them
with effective accuracy and speed.
There are two cases where the YOLO detection struggles to detect cars accurately.
It fails to classify toy cars in a top-down view, although it does identify
accurately the bounding boxes for both objects.
It was fed an image of a parking lot full of cars. It effectively detects
cars in the foreground, identifying whole rows of cars and trucks. But it
fails to detect cars in the background.
YOLO proves itself to be a powerful starting point to develop a model
that can detect several objects of different pose in an image. Detecting
several cars in a parking lot will require updates to the model.
Training Setup
A model is only as good as the data it is trained on. And because
the model will morph during the research development process, it will
need to run through training data whenever it mutates. Therefore, it
is crucial to the continued progress of this research topic to set up
training for this model.
Training works off the same code that is used to detect objects in images.
The neural net expression is in the same application. However, much more
additional work is completed to compile training data into a format
the neural net can consume.
The CNN is trained on the VOC data set. It contains a mixture of iconic
and non-iconic images. The non-iconic images do not contain nearly the
same density of objects as a parking lot full of cars, however.
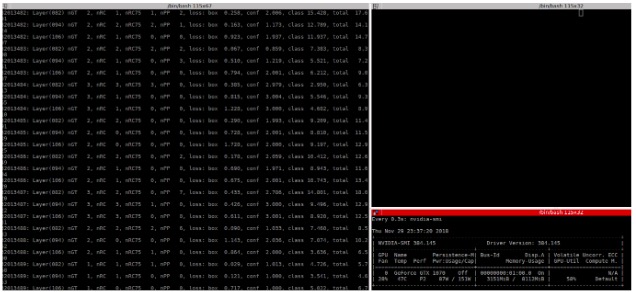
Training successfully occurs on the GPU because of the relative ease
of using CUDA with Pytorch. In fact, training on the GPU needs to happen.
Otherwise, there will not be much progress towards improving the model given
time constraints and the necessity to see results sooner rather than later
during the research development process.
The
YOLO training slides contain more details on training performance.
The data used for training is the VOC 2007 and 2012 data sets.
Next Steps
There are already several thousand images collected of cars in parking lots
collected in
Deliverable 3. The natural progression is to incorporate these
images into the training and validation. Each dataset will need
some conversion script to fit the input format YOLO expects.
The hypothesis is that additional training examples on objects in the background
or from different viewpoints and pose will improve accuracy.