Prototype - Find relevant ads for the search query
The aim of this deliverable is to design and develop a model which would retrieve relevant ads from advertisement database based on user's query. To implement the system, we first created bag of words model based on documents available for indexing. The bag of words model used to retrieve documents relevant to the user's query using cosine similarity ranking algorithm.
Cosine similarity is a measure of similarity between two vectors of an inner product space that measures the cosine of the angle between them. The cosine of 0° is 1, and it is less than 1 for any other angle. It is thus a judgement of orientation and not magnitude: two vectors with the same orientation have a Cosine similarity of 1, two vectors at 90° have a similarity of 0, and two vectors diametrically opposed have a similarity of -1, independent of their magnitude. Cosine similarity is particularly used in positive space, where the outcome is neatly bounded in [0,1].
Implementation overview:
Bag of words data format:
< term : number of docs containing term
doc1:position1,position2...;
doc2:position1,position2...; >
Input:
Search query
Intermediate output:
documents relevant to search query
Output:
Ads relevant to the search query
Important source files:
BagOfWords.java : Responsible for building inverted index.
DcoumentVector.java : This class contains methods for building document vector.
ContentBasedAds.java : Responsible for retrieving ads relevant to the search query from ads inventory.
TermInvertedIndex.java : Domain class for inverted index.
StopWordsHelper.java : Responsible for removing stop words from the document text.
IRServiceHelper.java : This class contains helper methods for finding relevant ads.
BagOfWordsHelper.java : This class contains helper methods for building inverted index.
Example:
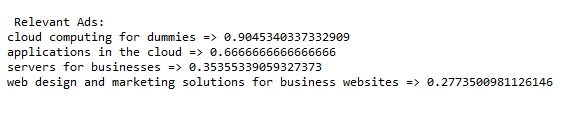
Let us say user entered search query "cloud". We get following set of documents which are relevant to entered query using cosine similarity.
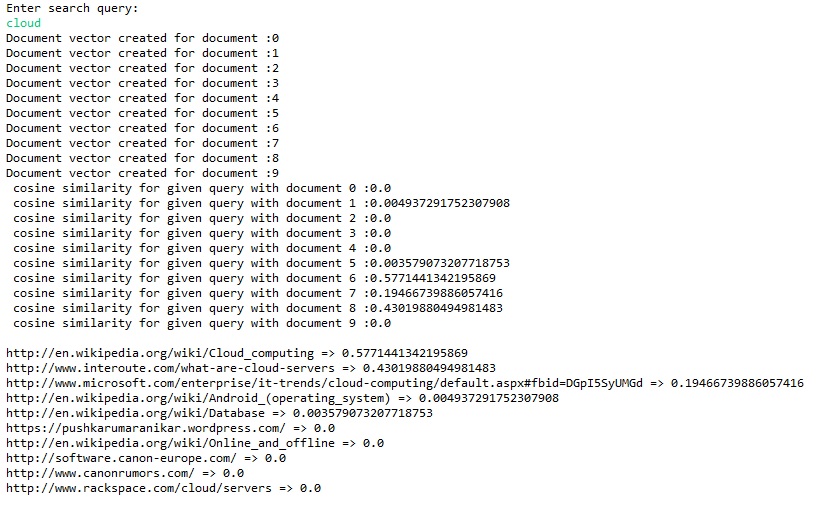
A set of documents is build using retrieved documents. Each of these documents is formed with entered keywords and immediate three words associated with it on either sides. In above case, I parsed through retrieved documents to locate cloud and formed documents containing <3 words> cloud <3 words> as shown in figure.

Then, calculate cosine similarity of each of these documents with ads in the inventory by forming vectors. Cosine similarity ranking algorithm will give the most relevant ads for given search query.