Description: Following is a description of how Nutch was used to crawl a small site as part of Deliverable 2.
Using HTML and PHP a front end is provided to the user where the URL of the site to be crawled can be entered. The PHP code takes this URL as input to the Crawl command in Nutch and creates the necessary databases for the site that is crawled. This directory with all the crawled information is created under the directory where Nutch is installed.
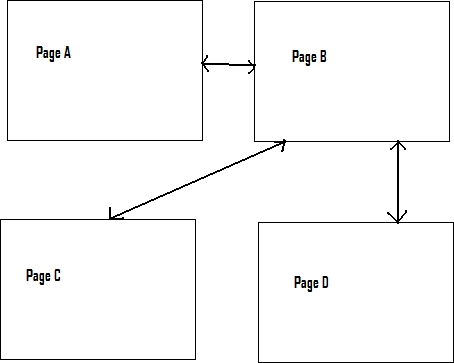
Example:As an example, a sample site http://localhost/CS297/PageA.html was crawled. This site has 4 pages with links from one page to the other as shown below.
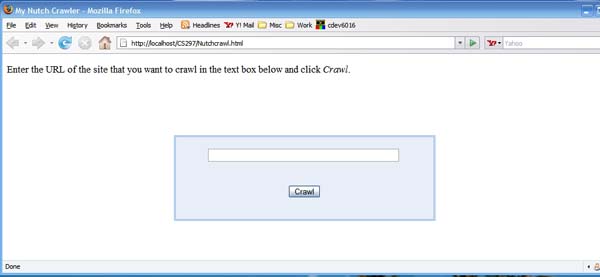
The front end provided to the user to enter the crawl site is shown in the screenshot below.
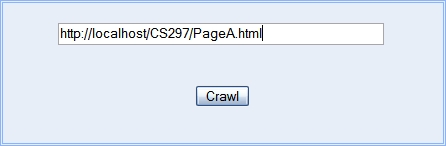
When the user enters the URL of the site in the text box provided and clicks on Crawl, a PHP script is invoked which crawls the site with the URL provided and stores the data in a directory.
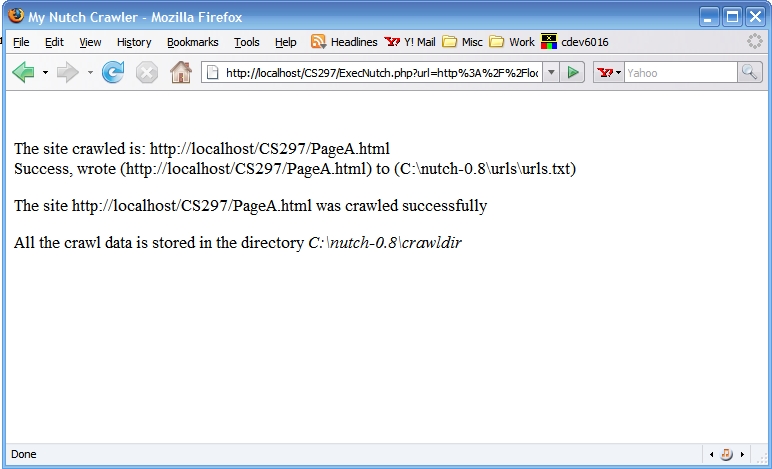
After the crawl is completed, this is what a user sees.
The following screenshot is of the directory where Nutch stores the crawled sites databases.
From here we can read the data from the databases using other Nutch commands. The commands can be exploited depending on what data we want to read from the databases.
For example: the command bin/nutch readdb crawldir/crawldb/ -dump dump_dir dumps certain information about all the pages crawled and stores in a human readable form in a file in the directory 'dump_dir'. The data stored for the sample site is shown below.
http://localhost/CS297/PageA.html Version: 4 Status: 2 (DB_fetched) Fetch time: Fri Dec 07 16:28:34 PST 2007 Modified time: Wed Dec 31 16:00:00 PST 1969 Retries since fetch: 0 Retry interval: 30.0 days Score: 1.6666667 Signature: e48ea88ce7aaa83d3115c598205ea05e Metadata: null http://localhost/CS297/PageB.html Version: 4 Status: 2 (DB_fetched) Fetch time: Fri Dec 07 16:28:44 PST 2007 Modified time: Wed Dec 31 16:00:00 PST 1969 Retries since fetch: 0 Retry interval: 30.0 days Score: 2.0 Signature: a1c8ea6e230e235c5ff1acb2be4bd202 Metadata: null http://localhost/CS297/PageC.html Version: 4 Status: 1 (DB_unfetched) Fetch time: Wed Nov 07 16:28:46 PST 2007 Modified time: Wed Dec 31 16:00:00 PST 1969 Retries since fetch: 0 Retry interval: 30.0 days Score: 1.6666667 Signature: null Metadata: null http://localhost/CS297/PageD.html Version: 4 Status: 1 (DB_unfetched) Fetch time: Wed Nov 07 16:28:46 PST 2007 Modified time: Wed Dec 31 16:00:00 PST 1969 Retries since fetch: 0 Retry interval: 30.0 days Score: 1.6666667 Signature: null Metadata: null
The code used to implement Deliverable 2 is printed below.
For the front-end page:
<!DOCTYPE html
PUBLIC "-//W3C//DTD XHTML 1.1//EN" "http://www.w3.org/TR/xhtml11/DTD/xhtml11.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en">
<head>
<meta http-equiv="Content-Type" content="application/xhtml+xml; charset=iso-8859-1" />
<title>My Nutch Crawler</title>
<link rel="stylesheet" type="text/css" href="my_css_styles.css" />
</head>
<body>
<p>Enter the URL of the site that you want to crawl in the text box below and click <i>Crawl</i>.</p>
<form id = "main" action = "ExecNutch.php" method = "get" >
<div class="formstyle">
<input type ="text" name = "url" size ="50"/>
<br /> <br /> <br />
<input type ="submit" value ="Crawl" />
</div>
</form>
</body>
</html>
PHP code for executing Nutch:
<?php
$url = $_GET['url'];
echo 'The site crawled is: '.$url;
preg_match('@^(?:http://)?([^/]+)@i',$url, $matches);
$host = $matches[1];
preg_match('/[^.]+\.[^.]+$/', $host, $matches);
$domain = $matches[0];
$pattern= '/[^w+].[^\.]+/';
preg_match($pattern, $domain, $matches);
$dirname = $matches[0];
$fulldirpath = "C:\\nutch-0.8\\".$dirname;
if(file_exists($fulldirpath))
{ echo 'The directory exists';
exit;
}
else
echo '<p>The directory does not exist</p>';
$filename = "C:\\nutch-0.8\\urls\\urls.txt";
$handle = fopen($filename, "w");
if(fwrite($handle, $url)===FALSE)
{
echo "Cannot write to file ($filename)";
exit;
}
echo "<br />Success, wrote ($url) to ($filename)";
fclose($handle);
$path1= $_SERVER['DOCUMENT_ROOT'];
$path2 = $_SERVER['PHP_SELF'];
$fullpath = $path1.$path2;
$SJAVA = "C:\Progra~1\Java\jdk1.5.0_09\bin\java";
escapeshellarg($SJAVA);
$SJAVA_HEAP_MAX ="-Xmx1000m";
$SNUTCH_OPTS =" -Dhadoop.log.dir=c:\\nutch-0.8\logs -Dhadoop.log.file=hadoop.log";
$SCLASSPATH ="c:\\nutch-0.8;c:\\nutch-0.8\conf;C;c:\Progra~1\Java\jdk1.5.0_09\lib\\tools.jar;\n
c:\\nutch-0.8\build\\nutch-*.job;c:\\nutch-0.8\\nutch-0.8.job;c:\\nutch-0.8\lib\commons-cli-2.0\n
-SNAPSHOT.jar;c:\\nutch-0.8\lib\commons-lang-2.1.jar;c:\\nutch-0.8\lib\commons-logging-1.0.4.jar;\n
c:\\nutch-0.8\lib\commons-logging-api-1.0.4.jar;c:\\nutch-0.8\lib\concurrent-1.3.4.jar;\n
c:\\nutch-0.8\lib\hadoop-0.4.0.jar;c:\\nutch-0.8\lib\jakarta-oro-2.0.7.jar;c:\\nutch-0.8\n
\lib\jetty-5.1.4.jar;c:\\nutch-0.8\lib\junit-3.8.1.jar;c:\\nutch-0.8\lib\log4j-1.2.13.jar;\n
c:\\nutch-0.8\lib\lucene-core-1.9.1.jar;c:\\nutch-0.8\lib\lucene-misc-1.9.1.jar;\n
c:\\nutch-0.8\lib\servlet-api.jar;c:\\nutch-0.8\lib\\taglibs-i18n.jar;\n
c:\\nutch-0.8\lib\\xerces-2_6_2-apis.jar;c:\\nutch-0.8\lib\\xerces-2_6_2.jar;\n
c:\\nutch-0.8\lib\jetty-ext\ant.jar;c:\\nutch-0.8\lib\jetty-ext\commons-el.jar;\n
c:\\nutch-0.8\lib\jetty-ext\jasper-compiler.jar;c:\\nutch-0.8\lib\jetty-ext\jasper-runtime.jar;\n
c:\\nutch-0.8\lib\jetty-ext\jsp-api.jar";
$SCLASS = "org.apache.nutch.crawl.Crawl";
$command1 = "$SJAVA ".$SJAVA_HEAP_MAX." ".$SNUTCH_OPTS." -classpath ".$SCLASSPATH." ".$SCLASS.\n
" C:\\nutch-0.8\urls -dir C:\\nutch-
0.8\crawldir1 -depth 2 -topN 2";
exec($command1);
echo "<p>The site $url was crawled successfully</p>";
echo "<p>All the crawl data is stored in the directory <i>C:\\nutch-0.8\crawldir</i></p>";
?>