CFG Based File Compression
by James Keesey
Introduction
This project's goals were to implement a compression algorithm and to analyse the effectiness of the algorithm. The algorithm is described in Approximating the Smallest Grammar: Kolmogorov Complexity in Natural Models by Moses Charikar et al. [CLLP02].
This article defines a compression algorithm that generates a balanced-binary context-free grammar whose expansion is the input string. The input to the algorithm is a stream of tokens that are the input string compressed using the Lempel-Ziv 77 (LZ77) algorithm. This article describes the algorithm at a theoretical level with no information about implementation.
The primary problems encountered while implementing this algorithm were related to converting the theory to practice. Of special concern was the output format. While the discussion in the article related to number of nodes, the size of the nodes was never examined or even mentioned. When using the same basic output format for the LZ77 compressed stream and the CFG compressed stream there was a significant difference in the output size.
Implementation
The algorithm was implemented using Sun's Java JDK 1.4.1. The grammar
is genreated as a forest of balanced-binary grammer trees. The forest
corresponds to the working set of the algorithm. The nodes
of the grammar one of two types: NonTerminalRule and
TerminalRule which correspond to an interior or leaf node
respectively.
The algorithm takes as input a stream compressed using the LZ77 algorithm. While there are many examples of the algorithm available, this alogrithm was implemented here for fairness because it is used as the benchmark against which the CFG algorithm is compared. Having control of this algorithm allowed for a fairer comparison as neither implmentation was optimized. This implementation uses a single internal memory buffer and so the maximum file size that can be handled is based on the Java VM size.
Output
The output stream for both algorithms is basically a series of integers (index and length for LZ77 and node numbers for CFG) so the same output format was used for both. This format is a semi-compressed format where each integer uses 1, 2, 3, or 4 bytes depeneding on its value. All integers in the range [0-127] take one byte and have the highest bit equal to 0. All integers in the range [128-16,383] take two bytes and have the highest two bits equal to 10. All integers in the range [16,384-2,097,151] take three bytes and have the highest three bits equal to 110. All integers in the range [2,097,152-134,217,728] take four bytes and have the highest four bits equal to 1110. The numbers are written with the highest order byte first and the lowest order byte last (big-endian order).
LZ77
The LZ77 output is a series of byte values intersperse with (index, length) pairs. Each byte value is written as is to the output. The (index, length) pairs are written to the output as a pair of integers (index first, then length) each of which has 256 added to the value. This allows for the index and length values to be distinguished from the byte values.
CFG
The CFG output consists of two sections. The first is the node list with one entry per node. The second section is the working set which controls the expansion of the nodes.
For the first section (the node list) the number of nodes is written and then each node is written in node index order. The node indexes start at 256 to distinguish them from byte values so the first node (number 256) is written immediately after the node count. Each node consists of a left pointer and a right pointer. The left pointer is written first followed by the right pointer. If the left node is a terminal node then the byte value is written instead of a node index number otherwise the node index number plus 256 is written.
For the second section (the working set) the number of items is written first and then the node index plus 256 of each node is written. If the node is a terminal node then the byte value is written.
Execution
I ran the system against several different file types and the results are included below. Basically there were a series of files that were designed for maximum compression, several text files (source code), and a couple of binary files. The results were not encouraging. In all cases the LZ77 did well to excelent. On the special files doubling the file size only added a few bytes to the output. However, the CFG algorithm did not perform well at all. Only on the constructed files did it do any compression and in most cases it expanded the the file size.
Analysis
Running Time
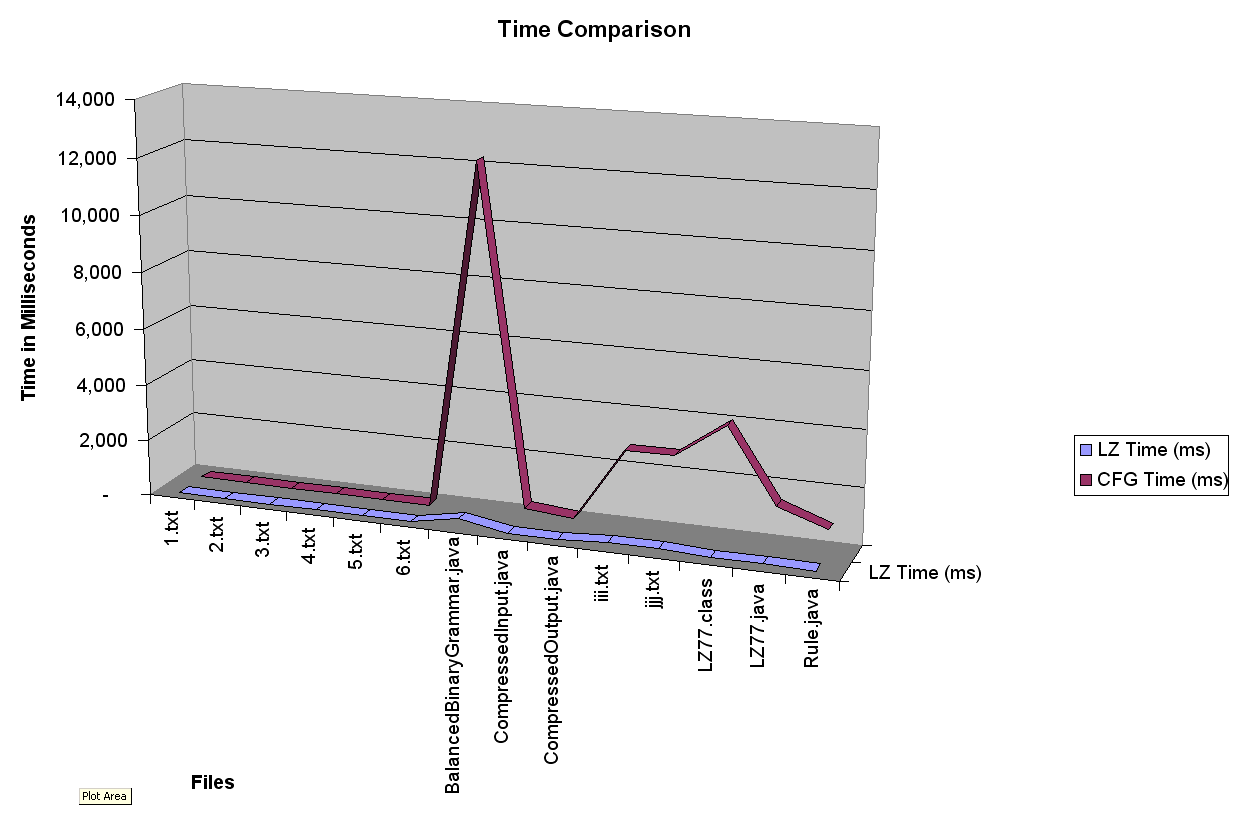
As can be seen from the following chart (Time Comparison) the runtime efficiency of the CFG algorithm was not spactacular. Even though the LZ77 algorithm requires scannning the input multiple times it still performed far better than the CFG. I believe that most of this is because the CFG algorithm must do multiple tree traversals as well as tree manipulations while the LZ77 algorithm does simple integer indexing into a byte array. As little or no time was spent optimizing either of the alogrithms, there are probably may places they could be improved.
File Sizes
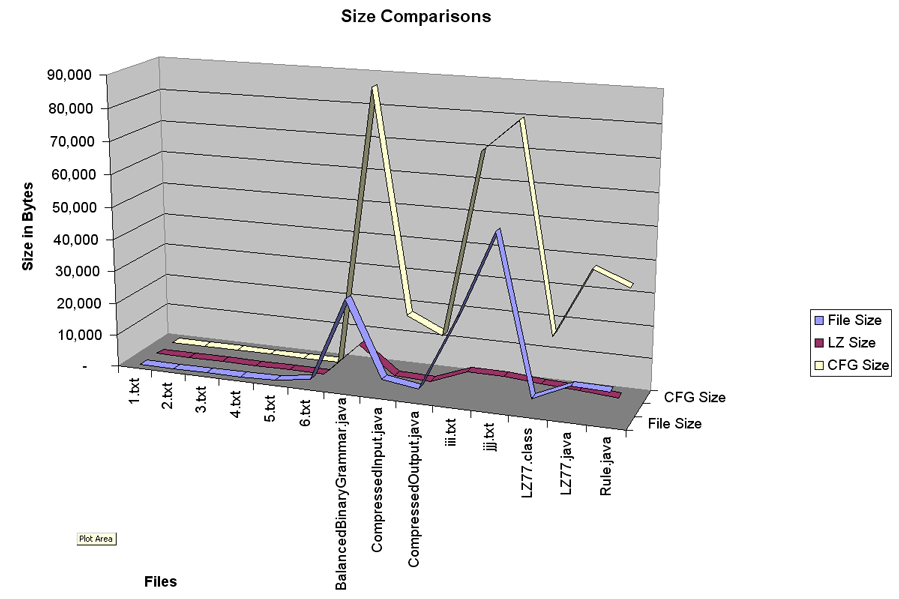
The following chart (Size Comparision) shows that the CFG algorithm almost always increased the size of the file except for a couple of files specifically designed for good compression results. In all of the "random" files the size was increased many times its original. While there are possible improvements in the storage structure, it does not seem reasonable to expect an improvement great enough to ever make this compression algorithm a valid choice.
Compression Comparision
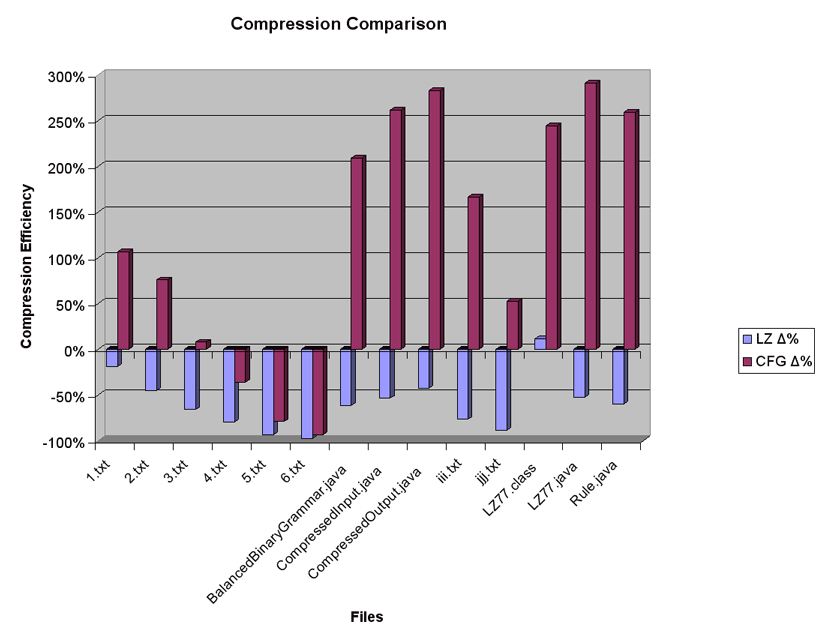
The last chart (Compression Comparison) shows in the most telling way that the CFG is not very good. This chart compares the "compressed" file size to the original file size. Except for the one binary file, the LZ77 algorithm reduced the size of the file for all files. The CFG algorithm only reduced the size of the file specifically designed for maximum compression (the same string repeated many times) and for all other the size increase was significant (up to 300%).
Conclusion
The CFG algorithm, while theoritically good, turned out in practice to
not perform well. While the number of nodes generated did behave as
predicted, the amount of data needed to represent those nodes was
significantly larger than that of the LZ77 method. In all cases the
LZ77 adds a single node per input node whereas the CFG algorithm always
adds multiple nodes (except for single bytes). So while the algorithm
is guarenteed to be no larger than log(n/g*) in practice it
seems to always be significantly larger than LZ77. Granted the encoding
method used may not be optimal but it should have been realtively the
same for both. The only real improvement would come if there were large
numbers of repeated node references which does not seem to be the case.
Copyright (C) 2003 by James Keesey. All right reserved.
Bibliography
[CLLP02] Moses Charikar, Eric Lehman, Ding Liu, Rina Panigrahy, Manoj Prabhakaran, April Rasala, Amit Sahai, Abhi Shelat: Approximating the smallest grammar: Kolmogorov complexity in natural models. STOC 2002: 792-801