One of the most popular bitwise coding techniques is due to Huffman (1952).
For a given probability distribution `M` on a finite set of symbols `{sigma_1, ... sigma_n}`, this scheme produces
a prefix code `C` that minimizes
`sum_(i=1)^n M(sigma_i) |C(sigma_i)|`.
A Huffman code is optimal amongst codes that use an integral number of bits per symbol.
Huffman Tree Construction
Suppose we have a compression model `M` with `M(sigma_i) = Pr(sigma_i)`.
To construct a Huffman code, we:
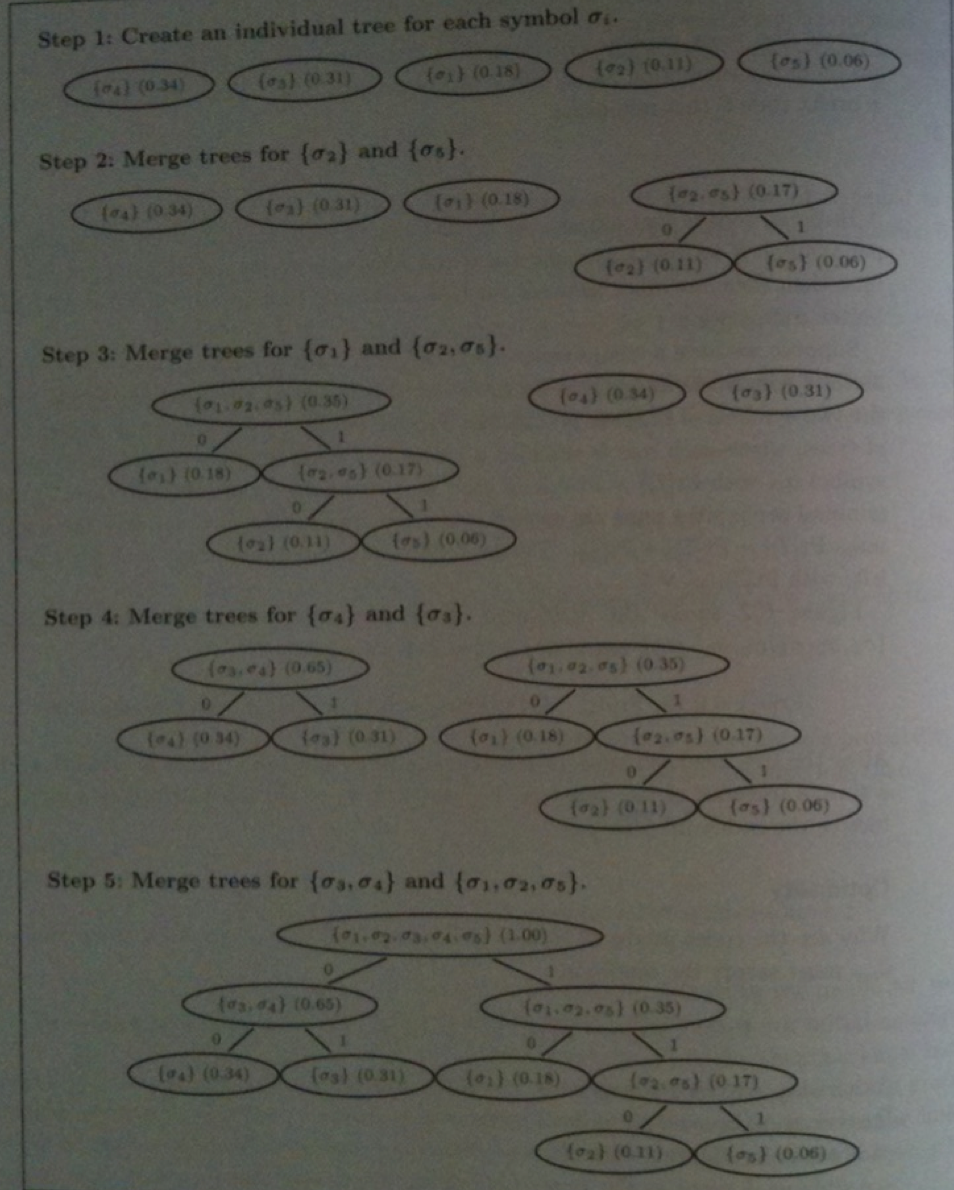
Start with a set of trees `T_i` one for each `sigma_i`. The probability of a tree will be the sum of the probabilities
of the symbols in it.
We next repeat until there is only one tree left and do:
Take the two trees of least probability, say `T_j` and `T_k`, and merge these into a single tree `T_i` consisting of a new top node labeled with the sum of `T_j` and `T_k`'s probabilities and having the more probable tree as the left child and the less probable as the right child. The edge to left child is labeled 0; to the right is labeled 1.
Once this tree is constructed, codes for symbols correspond to paths down this tree to the symbol in question.
Example
Facts About Huffman Codes
An optimal prefix code `C_(opt)` must satisfy `Pr[x] < Pr[y] => |C_(opt)(x)| ge |C_(opt)(y)|`
for every pair of symbols `x`, `y`.
The book uses this together with a proof by induction to show the Huffman code is in fact optimal.
The Huffman tree has `2n-1` nodes. So after the tree is constructed we can traverse the tree to assign codewords to symbols in `Theta(n)` time.
To actually build the tree, we need to keep track of the two trees of least probability.
If one implements this using a priority queue, the tree construction phase can be done in
`Theta(n log n)` time.
Thus, the complete algorithm is `Theta(n log n)` time.
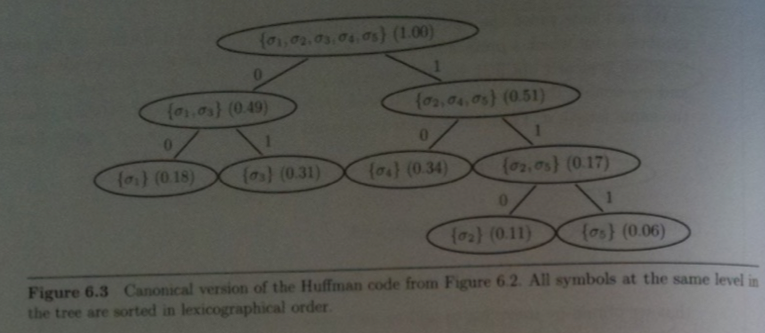
Canonical Huffman Codes
In order to use a Huffman code, the decoder needs to know how each symbol is encoded.
This description is prepended to the actual message being compressed in what's known as the preamble.
It might consist of a list of symbols together with their codes. For example,
`((sigma_1, 10)`, `(sigma_2, 110)`, `(sigma_3, 01)`, `(sigma_4, 00)`, `(sigma_5, 111))`
Consider the following Huffman tree:
The length of each code word is the same as for the first tree we had built a couple slides back.
So there is no reason to prefer that code to the one above.
Moreover, reading the symbols `sigma_i` from left to right in the above, corresponds to ordering them by length of
their respective codewords; ties broken according to lex order (i.e., `sigma_1` before `sigma_3`).
A code with such a property is called a canonical Huffman code.
For such a code it suffices to write down the length of the codes rather than the actual codewords:
`((sigma_1, 2)`, `(sigma_2, 3)`, `(sigma_3, 2)`, `(sigma_4, 2)`, `(sigma_5, 3))`.
Since we known the symbols in advance, we can further simplify this to: `(2, 3, 2, 2, 3)`
Quiz
Which of the following is true?
A generalized concordance list is any sequence of text intervals.
trec_eval can be used to generate search result judgments.
Compression techniques often involve a modeling and coding phase.
Motivating Arithmetic Coding
Consider the following probability distribution for a two symbol alphabet `S = {a, b}`: `Pr(a) = 0.8`, `Pr(b) = 0.2`.
Shannon's Theorem says symbol sequences generated according to this distribution cannot be encoded using
less than `0.7219` bits/symbol on average.
However, a Huffman code will need to use `1` bit per symbol, `39%` more than the lower bound.
Arithmetic codes will allow as to get closer to the lower bound by dispensing with the idea that each symbol gets a separate codeword.
As an example, we could improve upon the Huffman code for single symbols by taking pairs of symbols and making the Huffman code for them. In our example, we code "aa", "ab", "ba", and "bb" using a Huffman code. This actually reduces the the bits per symbol to `0.78`.
Arithmetic Coding
Consider a sequence of `k` symbols from the set `S={sigma_1, ... sigma_n}`:
`langle s_1, s_2 ..., s_k rangle in S^k`.
Each such sequence has a certain probability associated with it: `prod_(i=1)^kPr(s_i)`.
The sum over all such sequence is 1.
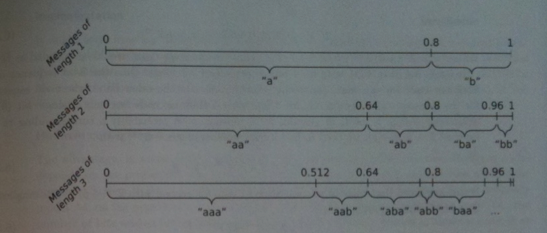
We can think of a sequence `x` as an interval `[x_1, x_2)`, with `0 le x_1 le x_2 < 1` and `x_2 - x_1` = Pr(x)`.
These sequences are arranged as subintervals of the interval `[0, 1)`, in lex order of the respective symbol sequence and form a partitioning of `[0, 1)`.
More Arithmetic Coding
We can code a message by encoding the associated interval `I` instead of the message itself.
It actually suffice to encode a smaller interval `I'` such that `I' subseteq I` and such that `I'`
have the form `I' = [x, x+2^(-q))` with `x = sum_(i=1)^q a_i cdot 2^(-i)` where (`a_i in {0, 1}`).
Such an interval is called a binary interval.
We encode a binary interval as just the bit sequence `langle a_1, a_2, ... a_q rangle`.
For example, `0`, encodes the interval `[0, 0.5)`, the bit sequence `01` encodes `[0.25, 0.5)`.
These two steps: (1) Transforming a message into an equivalent interval; (2) Encoding a binary interval within `I`
as a simple bit sequence -- is called arithmetic coding.
If `I=[y, y +p)`, the interval `I' = [x, x+2^(-q))` we want to use is the one of smallest `q` such that
`y le x < x + 2^(-q) le y +p.`
The smallest `q` for which this works is `q= |~ - log (p) ~| + 1`.
Redux
If probabilities of each k sequence are of finite precision, one can imagine using an integer to store some maximum denominator and then avoid using floating points and their associated error when doing arithmetic coding.
Witten et al. (1987) have shown how to do this in a systematic way.
Huffman tends to be faster to encode and decode.
Both of these algorithms are used in more sophisticated algorithms such as gzip (Ziv Lemmpel, 1977) and bzip (Burrows and Wheeler, 1994).
Straight text compression as we have seen might be used to compress the downloaded pages of a search engine or snippet-ready summaries generated from them.
On Wednesday, we will look at compression techniques geared toward posting lists.