We have been considering different techniques for handling long term and recurrent information needs using categorization and filtering.
We have so far looked at how to filter medical news items both in a batch setting and on-line setting using BM25 and historical data.
We have considered how to do supervised learning of this task using pseudo-relevance feedback.
We then saw how to do language categorization and filtering, again using BM25
We begin today by looking at the problem of filtering spam emails...
On-line Adaptive Spam Filtering
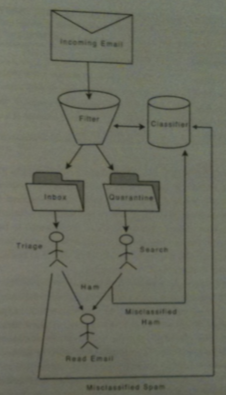
The above figure illustrates the flow of an incoming email through a spam filter.
Emails arrive one-by-one (i.e., the system is online).
If an email is labeled as spam in goes into a quarantine folder. It may be rescued from this folder and read or not.
On the other hand, a user might label mail that the filter said was okay (ham, and hence put in the Inbox) as spam.
Such relabeling's are used provided as examples to the classifier which then improves itself for subsequent mail (i.e., the system is adaptive).
For our example, we will consider the inbox to be a queue and the quarantine a priority queue with the hardest to classify ranked at the top of the queue.
Framework for Categorization
One tool for evaluating spam filtering is the TREC 2005 Public Spam Corpus.
This consists of a sequence of 92,180 messages, of which 39,399 are spam and 78,798 are ham.
Rather than splitting the sequence into training and tests sets, on-line feedback is used.
In this setting, an ideal user is assumed to detect and report all errors.
So every message may be used as a historical training example immediately after it is delivered.
The online scenario is implemented using the TREC Spam Filter Evaluation Toolkit.
This toolkit can be used for any binary classification task (we have two exclusive categories), although we are using it for just spam versus ham.
For evaluation, within the toolkit's framework, a filter must following operations:
initialize - Create a filter a process a new stream of messages
classifyfile - Return a category and priority for the message in file.
train spam file - Use file as a historical example of spam.
train ham file - Use file as a historical example of ham.
finalize - shutdown the filter.
BM25 Applied to On-line Adaptive Email Filtering
We now give an example of using this framework together with BM25 for Spam filtering.
To start we call initialize to create an initial filter which has no information on which to base its decision.
The rate and manner in which this filter improves with training is known as the learning curve.
We apply BM25 with relevance feedback separately to each of the document ranking problems: identifying spam and identifying ham.
This yields two scores: `s(d, spam)` and `s(d, ham)`.
The category ranking for `d` is determined by the difference `s(d) = s(d,spam) - s(d, ham)`.
If `s(d) > 0` the document is classified as spam, otherwise, it is classified as ham.
BM25 Applied to Adaptive Email Filtering -cont'd
In their experiments, when either a train ham or train spam is called, the book's author's filter generates 4-grams from the message and keeps track of the average length of the spam or ham document and `N_t` for that term.
When classify file is called, a BM25 score is computed with respect to the 4-grams in file and these `N_t` and average length values for both spam and for ham. Finally, `s(d)` is calculated.
In-Class Exercise
Imagine we have four messages with labels in parentheses:
Spam is good for you. (Spam)
Ham sandwiches taste great (Ham)
Monty Python is annoying. (Spam)
I eat pork. (Ham)
By hand generate 4 grams to train Spam and Ham scores.
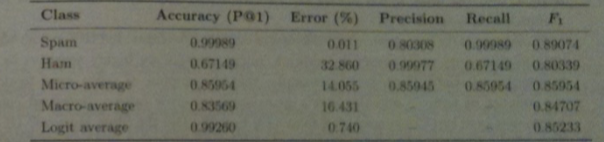
The above shows the evaluation measures for the primary categorization problem in an on-line spam filter.
For `F_1` score we assume spam constitutes the relevant class is spam
Notice the P@1 score for spam is very high.
Instead, error `1-P`@`1` expressed as a percentage is often used.
So an error rate of .1% is 10 better than one of 1%.
The above shows that about 1 in 10000 spam messages is delivered to the user's in-box.
On the other hand, the ham error rate is 32.9% so about a third of good messages are quarantined.
This is probably unacceptable, but the reverse situation might not be.
Micro-average and macro-average scores fail to take into consideration he prelevance of spam. So doubling the amount of ham while keeping he amoun of spam the same actual would improve both error rates.
To compensate for this, we can use a logit average LAM. Here `LAM(x,y) = logit^{-1}(logit(x) +logit(y)/2)` is often used.
Choosing a threshold
Rather than accept the ham rate above the book explores setting different values for `t` and then considering `s(d) >t` as spam
.
For example, when `t=2156` the spam error is 56.8% but the ham error rate is 0%. On the other hand, when `t=-180` the spam rate is 0 and the ham rate is 34.9%.
One can use this to choose the best compromise that the filter offers for the two errors.
We can also plot the points (spam error, ham error) for fixed `t` as we let `t` vary. This gives the so-called receiver operating characteristic (ROC) curve.
To compare filters one often looks at 1-AUC (area under this curve).
The book shows the score for this filter versus spam assassin are comparable.