Last week, we started looking at how to make IR systems capable of handling longstanding recurring information needs.
Some examples of these were (a) determining the language a document or query was written in, (b) medical news update delivery,
(c) removing spam content from email
(a) is an example of classification: assigning a label to a document.
(b) is an example of filtering: sending documents to different locations based on who has what information need.
We looked at (b) in more detail and proposed collecting news items in an ongoing basis into batches of a certain time period or number of items
then filtering/routing those items to the appropriate recipients.
As part of the filtering process, we used BM25 as a soft filter to rank documents according to the relevance to the intended user.
Even if all batches were the same size, they might not have the same number of relevant documents. To see this effect we looked at P@10 scores for different batch sizes and saw the scores varied a lot.
To fix this, we considered sending the recipients the top fraction `rho` of the results and shows P@`lfloor rho n rfloor` was relatively constant for BM25 no matter what the batch size.
We also considered rather than returning the top fraction of results, returning results whose score was above some threshold. This gave even more stable results.
We begin today, by looking at online filtering rather than batch filtering...
Online Filtering
Online filtering is essentially batch filtering where the batch size is 1.
An online filter must act immediately on each message in a sequences rather than on batches of messages.
Messages deemed relevant must be delivered and all others discarded.
Delivery might be an email to an inbox or text message or sending a message to some folder.
If possible we would like to be able to flag messages by priority. I.e., have some kind of primitive importance ranking.That way we don't need to discard messages.
Otherwise, we need to set some relevance threshold so that the rate of delivery `rho` represents a good balance of precision and recall as measure by a score like an F-measure.
Scores like BM25 when used to give a priority score need to be modified so they can work on a per-document basis. For example `N_t` assumes a large collection of documents. To fake this one can just assume the corpus consists of the single current document.
Above shows the aggregate precision scores for online filtering using BM25 and a theshold that gives a given target (10, 20, 100, etc) number of results over the whole collection versus single batch filtering (whole corpus 1 batch).
Historical Collection Statistics
At the time we deploy a filtering system we might not know the rate at which relevant documents arrive, making it harder to choose thresholds, etc.
We next consider how to take advantage of this kind of information.
If we are doing batch filtering, one way to take advantage of historical information.
In the batch setting, we can do this by historical documents with a given batch to do ranking, then removing the historical documents leaving a rank and score for the documents in the batch.
This will mean the batch makes use of better collection statistics such as IDF scorse and so the relevancy scores determined will be more accurate.
Rather than return a fixed number of documents per batch, we can return only those documents that appear in the top `k' > k` in the combined list
For a suitable `k'` this will return the same number of documents overall while achieving better precision.
Online Filtering with Historical Collection Statistics -- What to Store
When historical documents are used online filtering effectively reduces to batch filtering.
One difference is that we only need to figure out where a single documents score is relative the list we have already computed.
Hence, we don't need to build a full inverted index apparatus we have previously considered.
All we need to compute BM25 or a similar score is a dictionary with entries indicating `N_t` for each term. For overall ranking, we might also keep an ordered list of historical scores (with respect to all terms, not per term scores).
We can compute relevance using the current document and `N_t`. To compute rank we binary search in the list to insert the score of the current document.
The table above compares online filtering with and without use of historical information.
We haven't explained the last row of the above table yet.
Historical Training Examples
In the filtering setting it is likely that some examples of relevant documents are already known.
For example, before we start filtering medical papers related to cardiac surgery, we probably have some known examples of papers on this subject.
Such examples are known as training examples or labeled data.
In machine learning, building a classifier using labeled data is known as supervised learning.
Using BM25 relevance feedback is an example of how we could build such a classifier.
I.e., we could look at the `r` known relevant documents, select the top `m` term scores with respect to these documents, say `m=20` and then augment our original query with these terms.
This was used to produce the last row of results from the previous slide for the query we had last day using TREC45 data.
Quiz
Which of the following is true?
Yarn is the name of the Hadoop file system.
Categorization is the process of labeling documents to satisfy some information need.
Filtering is another name for ranking.
Language Categorization - Filtering
Two common tasks associated with documents and the language they are written in are:
Categorization: Given a document `d` and a set of possible categories, identify the category to which `d` belongs. Related to this is Category Ranking: rank the category according to how likely the document belongs to that category.
Filtering: Given a category `c` determine which documents belong to this category. Related to this is document ranking list the documents in order of the likelihood of belong to the category.
The book's authors used the random link feature of Wikiepdia to collect 8012 articles from each of 60 languages from Wikipedia.
They then extracted the first 50 bytes of text from each article as snippet messages.
They used 4000 snippets for training and 4012 for categorization and filtering.
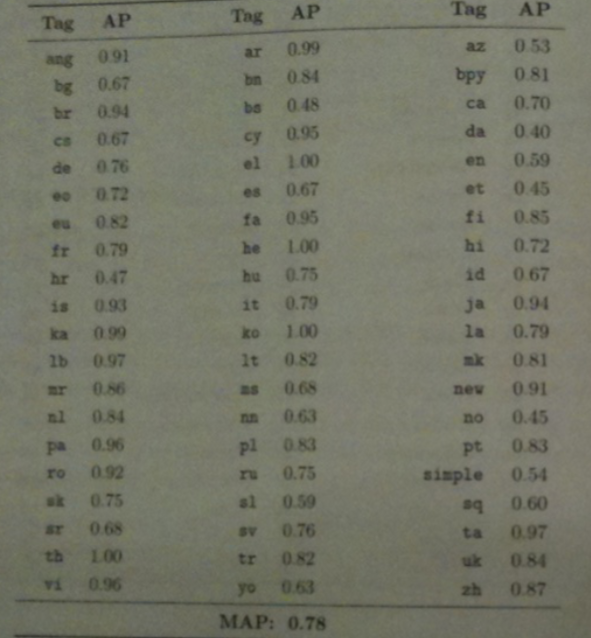
To do filtering, each language was treated as a separate topic. Snippets were 4-grammed and training snippets grams were used as query terms in BM25 document ranking for test documents.
The graph above shows the results of this document ranking experiment.
Language Categorization - Categorization
To perform categorization we have to rank languages instead of documents.
To do this we use the relevance scores from the document ranking.
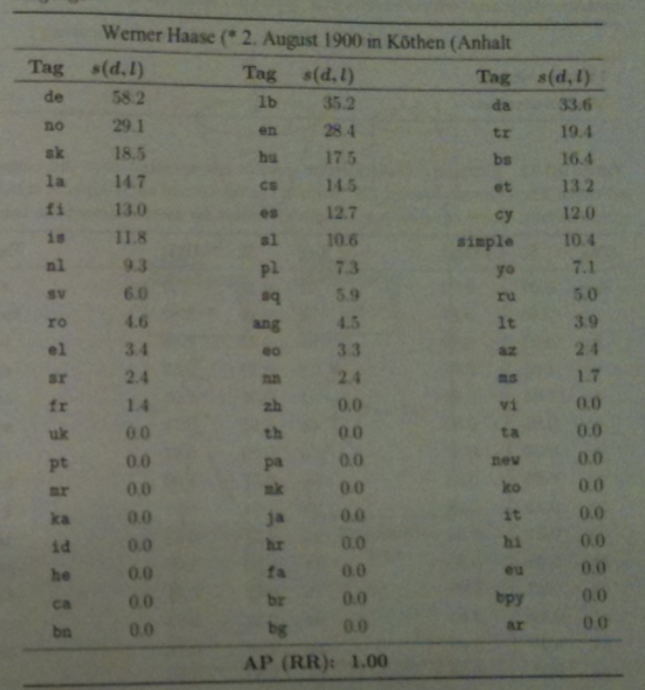
Given a document `d` and a language `l`, let `s(d,l)` be the relevance score for `d` in the document ranking for `l`.
Given two language `l_1` and `l_2` we assume if `s(d,l_1) > s(d,l_2)` that `d` is more likely to be written in `l_1` than `l_2`.
The table above shows the complete ordering of BM25 scores for each language for a snippet of German text.
In this setting P@1 is most commonly called accuracy. This indicates the proportion of documents for which the correct category was ranked first.
MAP scores in this setting are equal to Mean Reciprical Rank (MRR) scores because there is exactly one relevant result per ranking.
For a single topic, reciprocol rank is defined as `\R\R=1/r` where `r` is the rank of the first and only relevant result. In the case `AP = P`@`r =1/r`.
Summary statistics are often expresed as either micro-averages which are computed over all documents without regard to category or macro-averages which are an average of summary measures computed for each category.
For the accuracy and the language categorization tests just considered both of these scores were 0.79. For MRR, the scores were 0.860 and 0.857 respectively.